FAQ¶
Frequently Asked Questions¶
Q1: Import packages warning¶
A1:
Regarding import linlink, ceph, memcache, redis related warnings displayed on the command line when running DI-engine, generally users can ignore it, and DI-engine will automatically search for corresponding alternative libraries or code implementations during import.
Q2: Cannot use DI-engine command line tool (CLI) after installation¶
A2:
pip with
-eflag might sometimes make CLI not available. Generally, non-developers do not need to install with-eflag, removing the flag and reinstall is sufficient.Part of the operating environment will install the CLI in the user directory, you need to verify whether the CLI installation directory is in the user’s environment variable (such as
$PATHin Linux).
Q3: “No permission” error occurred during installation¶
A3:
- Due to the lack of corresponding permissions in some operating environments, “Permission denied” may appear during pip installation. The specific reasons and solutions are as follows:
pip with
--userflag and install in user’s directoryMove the
.gitfolder in the root directory out, execute the pip installation command, and then move it back. For specific reasons, see https://github.com/pypa/pip/issues/4525
Q4: How to set the relevant operating parameters of SyncSubprocessEnvManager¶
A4:
Add manager field to the env field in cfg file, you can specify whether to use shared_memory as well as the context of multiprocessing launch. The following code provides a simple example. For detailed parameter information, please refer to SyncSubprocessEnvManager.
config = dict(
env=dict(
manager=dict(shared_memory=False)
)
)
Q5: How to adjust the learning rate¶
- A5:
Add lr_scheduler module in the entry file.
You can adjust the learning rate by calling torch.optim.lr_scheduler (refer to https://pytorch.org/docs/stable/optim.html) and apply the scheduler.step() to update the learning rate after optimizer’s update.
The following code provides a simple example. For more detail, see demo: https://github.com/opendilab/DI-engine/commit/9cad6575e5c00036aba6419f95cdce0e7342630f.
from torch.optim.lr_scheduler import LambdaLR
...
# Set up RL Policy
policy = DDPGPolicy(cfg.policy, model=model)
# Set up lr_scheduler, the optimizer attribute will be different in different policy.
# For example, in DDPGPolicy the attribute is 'optimizer_actor', but in DQNPolicy the attribute is 'optimizer'.
lr_scheduler = LambdaLR(
policy.learn_mode.get_attribute('optimizer_actor'), lr_lambda=lambda iters: min(1.0, 0.5 + 0.5 * iters / 1000)
)
...
# Train
for i in range(cfg.policy.learn.update_per_collect):
...
learner.train(train_data, collector.envstep)
lr_scheduler.step()
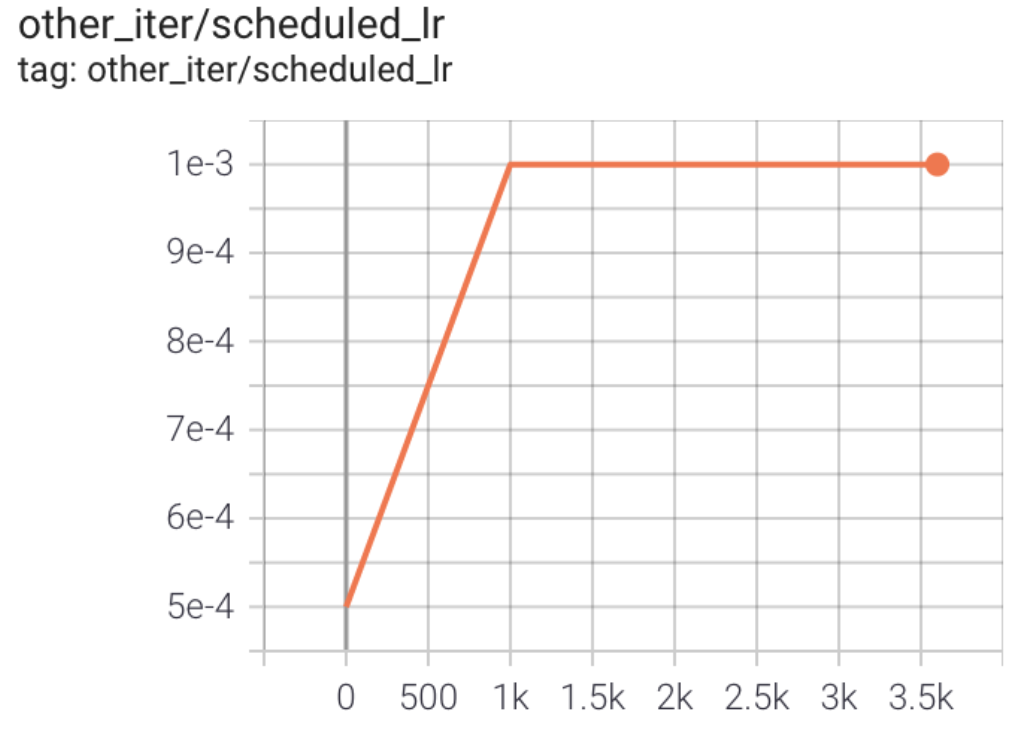
The curve of learning rate is shown in the figure below
Q6: How to understand the printed [EVALUATOR] information¶
A6:
We print out the evaluation information of evaluator in interaction_serial_evaluator.py ,
including env, final reward, current episode, which represent the eval_env index (env_id) corresponding to the current completed episode (in which timestep.done=True),
the final reward of the completed episode, and how many episodes it was evaluated by the evaluator, respectively. A typical demonstration log is shown in the figure below:
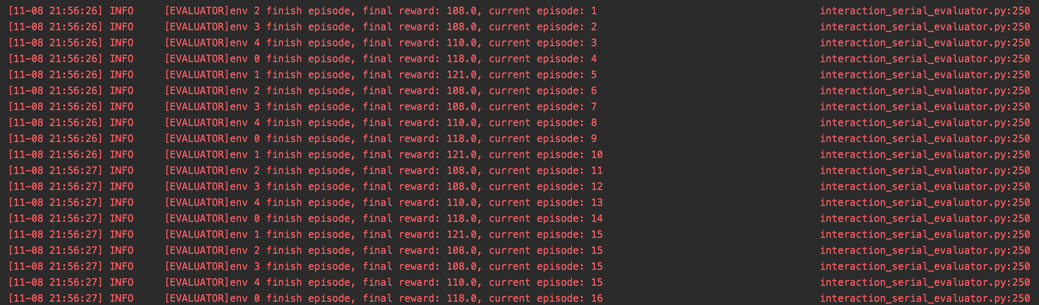
In some cases, different evaluator environment (abbreviated as eval_env) in the evaluator may collect episodes with different lengths. For example, suppose we collect 16 episodes through evaluator, but only have 5 eval_env,
i.e. setting n_evaluator_episode=16, evaluator_env_num=5 in config,
If we do not limit the number of evaluation episodes in each eval_env, it is likely that we will get many episodes with short lengths.
As a result, the average reward obtained in this evaluation phase will be biased and cannot fully reflect the performance of the current policy (Only reflects the performance on episodes with shorter lengths).
To address this issue, we propose to utilize the VectorEvalMonitor class.
In this class, we averagely specify the number of episodes each eval_env needs to evaluate in here,
e.g. if n_evaluator_episode=16 and evaluator_env_num=8, then only 2 episodes of each eval_env will be added into statistics.
For the specific meaning of each method of VectorEvalMonitor, please refer to the annotations in class VectorEvalMonitor.
It is worth noting that when a certain eval_env of the evaluator completes the number of each_env_episode[i] episodes, since the reset of the eval_env is controlled by
env_manager automatically, the certain eval_env will continue to run until exiting the whole evaluation phase.
We utilize VectorEvalMonitor to control the termination/exiting of the evaluation phase, only if
eval_monitor.is_finished() is True
, i.e. the evaluator completes all evaluation episodes (n_evaluator_episode in config), the evaluator will exit the evaluation phase.
Thus there may be a case where the corresponding log information of an eval_env is still repeated even if it finishes the evaluation of each_env_episode[i] episodes, which
do not adversely affect the evaluation results, so the users don’t need to be worried about these repeated logs.
Q7: Is there any documentation for the config file in DI-engine? How can I set the fields in the config file to control training termination?¶
A7:
For a detailed introduction to the configuration file system in DI-engine, please refer to the Configuration File System Documentation. In DI-engine, there are generally three types of termination settings:
When the pre-set
stop value(modified in the config file) is reached, i.e., when theevaluation episode reward meanis greater than or equal to thestop value.When the maximum number of environment interaction steps (
env step) is reached, which can be modified in the training entry.Example 1: https://github.com/opendilab/DI-engine/blob/main/ding/entry/serial_entry.py#L24
Example 2: https://github.com/opendilab/DI-engine/blob/main/ding/example/sac.py#L41 (setting the value of
max_env_step)
When the maximum number of training iterations (
train iter) is reached, which can be modified in the training entry.
Furthermore, for specific field descriptions in the config file, you can refer to the comments in the default config section of each class. For example:
Reinforcement learning-related configuration files can be complex. If there are any details you don’t understand, please feel free to ask!
Q9: What does “episode” refer to in DI-engine?¶
A9:
It is not an original concept in reinforcement learning but originates from gaming. It is similar to the concept of a “level” and refers to the process where an agent starts playing a game until it reaches a game over or successfully completes the game. In essence, it represents a complete cycle of interaction with the environment, such as a game session or a game of Go.
Q10: Does DI-engine support the self-play mechanism?¶
A10:
Yes, it is supported. The simplest examples can be found in the league demo and slime volleyball in the dizoo directory.