FAQ¶
Frequently Asked Questions¶
Q1. 关于使用时出现的warning¶
A1:
对于运行DI-engine时命令行中显示的import linlink, ceph, memcache, redis的相关warning,一般使用者忽略即可,DI-engine会在import时自动进行寻找相应的替代库或代码实现。
Q2. 安装之后无法使用DI-engine命令行工具(CLI)¶
A2:
部分运行环境使用pip安装时指定
-e选项会导致无法使用CLI,一般非开发者无需指定该选项,去掉该选项重新安装即可部分运行环境会将CLI安装在用户目录下,需要验证CLI的安装目录是否在使用者的环境变量中 (如 linux 的
$PATH中)
Q3: 安装时出现”没有权限”相关错误¶
A3:
- 由于某些运行环境中缺少相应权限,pip安装时可能出现”没有权限”(Permission denied),具体原因及解决方法如下:
pip添加
--user选项,安装在用户目录下将仓库根目录下的
.git文件夹移动出去,执行pip安装命令,再将其移动回来,具体原因可参见 https://github.com/pypa/pip/issues/4525
Q4: 如何设置SyncSubprocessEnvManager的相关运行参数¶
A4:
在配置文件的env字段添加manager字段,可以指定是否使用shared_memory,多进程multiprocessing启动的上下文,下面的代码提供了一个简单样例,详细的参数信息可参考 SyncSubprocessEnvManager
config = dict(
env=dict(
manager=dict(shared_memory=False)
)
)
Q5: 如何调整学习率¶
A5:
在相应算法的入口添加 lr_scheduler 代码,可以通过调用 torch.optim.lr_scheduler (参考: https://pytorch.org/docs/stable/optim.html)模块来调整学习率,并且在模型优化更新之后使用 scheduler.step() 对学习率进行更新。
下面代码提供一个简单的案例,具体可参考demo: https://github.com/opendilab/DI-engine/commit/9cad6575e5c00036aba6419f95cdce0e7342630f。
from torch.optim.lr_scheduler import LambdaLR
...
# Set up RL Policy
policy = DDPGPolicy(cfg.policy, model=model)
# Set up lr_scheduler, the optimizer attribute will be different in different policy.
# For example, in DDPGPolicy the attribute is 'optimizer_actor', but in DQNPolicy the attribute is 'optimizer'.
lr_scheduler = LambdaLR(
policy.learn_mode.get_attribute('optimizer_actor'), lr_lambda=lambda iters: min(1.0, 0.5 + 0.5 * iters / 1000)
)
...
# Train
for i in range(cfg.policy.learn.update_per_collect):
...
learner.train(train_data, collector.envstep)
lr_scheduler.step()
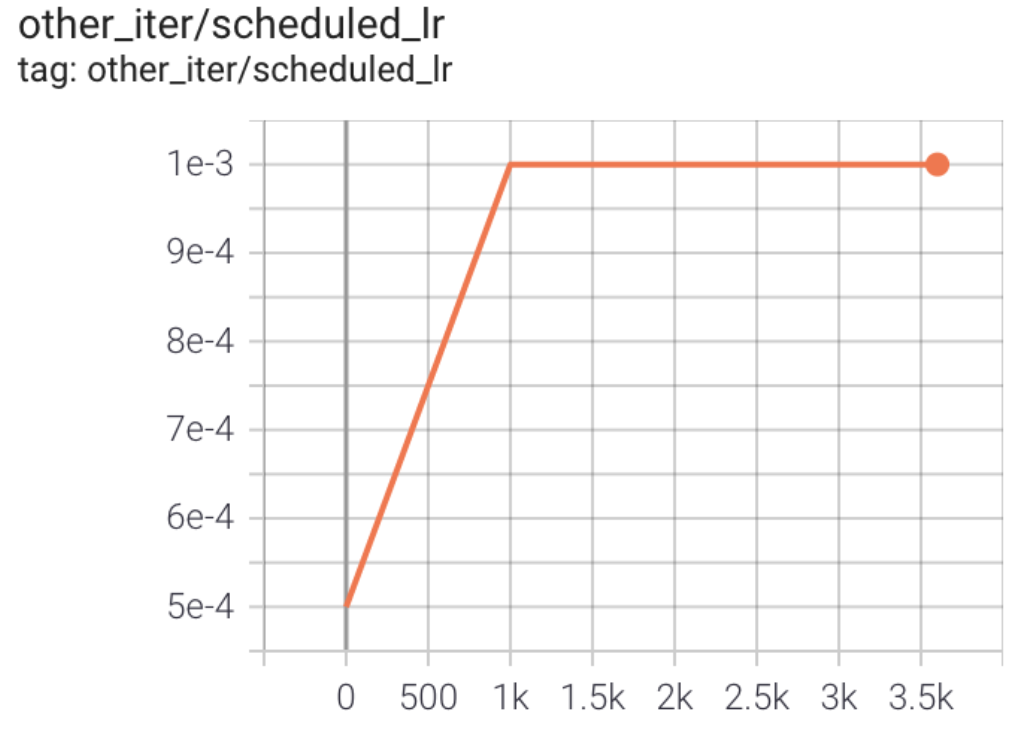
学习率变化曲线如图所示
Q6: 如何理解打印出的 [EVALUATOR] 信息¶
A6:
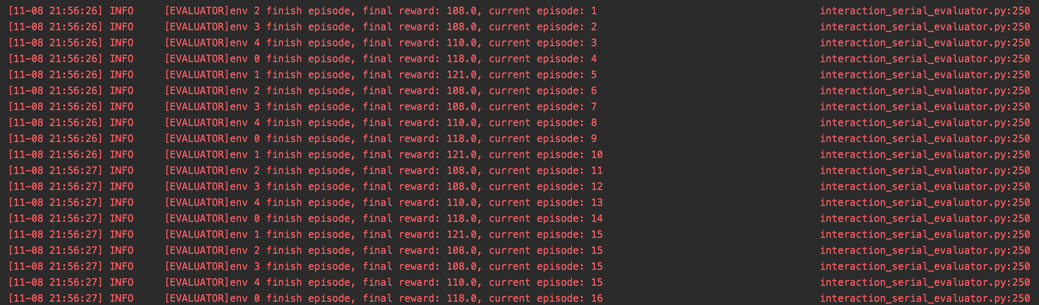
我们在 interaction_serial_evaluator.py ,打印出 evaluator 的评估信息,
包括 env, final reward, current episode 分别代表当前已完成局 (timestep.done=True) 对应的环境索引 (env_id), 当前已完成局游戏的奖励, 以及它是 evaluator 评估的第几局游戏。
一个典型的 evaluator log 信息如下图所示:
在某些情况下,evaluator 中的不同环境可能会收集不同长度的游戏局。 例如,假设我们通过 evaluator 收集 16 局游戏,但只有 5 个评估环境 (eval_env),即在 config 中设置 n_evaluator_episode=16, evaluator_env_num=5,
我们如果不对每个评估环境的评估总局数进行限制,很可能会得到许多步长较短的游戏局,这样一来,这次评估阶段得到的平均奖励就会有偏差,不能完全反映当前 policy 的性能 (只反映了在步数较短的游戏局上的性能)。
我们通过使用 VectorEvalMonitor 类来缓解这个问题。
在这个类中,我们在 这里 平均指定每个 eval_env 需要评估的局数,
例如,如果设置 n_evaluator_episode=16 和 evaluator_env_num=8,那么每个 eval_env 只有 2 局将被添加到统计量中。
关于 VectorEvalMonitor 每个方法的具体含义,请参考类 VectorEvalMonitor 的注释。
值得注意的是,当 evaluator 的某一个 eval_env 完成评估数量为 each_env_episode[i] 的游戏局后,由于环境的 reset 是由
env_manager 自动控制的,它还会继续运行下去, 除非整个评估阶段终止。
我们是用 VectorEvalMonitor 控制评估阶段的终止,只有当
eval_monitor.is_finished() 为True时,
即 evaluator 完成了所有的评估任务后 (在所有 eval_env 上一共评估了 n_evaluator_episode 局),才会退出本次评估, 所以可能会出现某个 eval_env 在完成它自己的评估数量为 each_env_episode[i] 的游戏局后,其对应的log信息仍然重复出现的情况,
用户不必担心这些重复的 logs,它们不会对评估结果产生不好的影响。
Q7: DI-engine 里的 config 文件有相关说明吗?如何在 config 中设置控制训练停止的相关字段?¶
A7:
关于 DI-engine 配置文件系统详细介绍可见 配置文件系统文档 。DI-engine 中一般来说有三种停止设置:
到达预设置的
stop value(config 中修改),即evaluation episode reward mean大于等于stop value到达预设置的最大环境交互步数(
env step),训练入口中修改到达预设置的最大训练迭代数(
train iter),训练入口中修改
另外,关于配置文件具体字段的介绍,可以参考各个类的 default config 部分的注释,例如
强化学习相关配置文件较为复杂,如果还有不懂的细节欢迎大家随时提问!
Q8: DI-engine 安装相关问题。¶
Q8-1 能否用 pip 安装 DI-engine?
A8-1:
可以,直接使用
pip install DI-engine命令即可,具体可见 安装说明文档-安装发布版本 。Q8-2 DI-engine 安装时会自动安装 PyTorch 嘛?如果电脑本身带有 PyTorch 会怎么样呢?
A8-2:
如果当前环境之前已经安装过 PyTorch,安装 DI-engine 时检查 PyTorch 版本符合要求的话,就会直接安装其他的依赖包;如果之前没有安装,DI-engine 会默认装上 cpu 版的 PyTorch 最好自己先安装 PyTorch 的合适版本,不然 di-engine 会默认装上 cpu 版的 PyTorch,具体的安装步骤可参考 安装说明文档 。
Q8-3 DI-engine 对应的 gym 版本是?是否不能适配最新 gym 版本?
A8-3:
目前 DI-engine 对应到 gym 版本 0.25.1(2023.5.5),对于 DI-engine 适配的各个依赖库版本问题,可以参考 setup.py 文件。
Q8-4 如何从 Github 源码安装最新的 DI-engine 开发版本?
A8-4:
可以从 Github clone 下来,进入到相应文件夹里
pip install -e .,如:git clone https://github.com/opendilab/DI-engine.git cd DI-engine pip install .
Q9: DI-engine 中的 episode 指什么呢?¶
A9:
episode 这个词的中文翻译比较生硬,并不是强化学习的原创概念,它来自于游戏,类似“关卡”的意思,指智能体开始玩游戏到通关或者 game over 的过程,本质是指跟环境交互的一个完整周期,比如一局游戏一盘围棋这样,或许翻译为“集”or“局”比较好。
Q10: DI-engine 支持 selfplay 机制吗?¶
A10:
支持的,最简单的例子可以参考 dizoo 中的 league demo 和 slime volleyball 。