Atari¶
Overview¶
Atari is the most classical and commonly used environment in reinnforcement learning. It is often used as a benchmark environment for discrete action spaced RL algorithms. Atari is a collection of (Precisely 57) sub environments. The most commonly used are Pong,Space Invaders,QBert,Enduro,Breakout,MontezumaRevenge etc. Game “Space Invaders” is shown below.

Installation¶
Installation Methods¶
Install gym and ale-py. You can install by command pip or through DI-engine.
Note:atari-py is now aborted by developer. It is recommended to use ale-py
# Method1: Install Directly
pip install gym
pip install ale-py
pip install autorom
autorom --accept-license
# Method2: Install with DI-engine requirements
cd DI-engine
pip install ".[common_env]"
Installation Check¶
After completing installation, you can check whether it is succesful by the following commands:
import gym
env = gym.make('Breakout-v0')
obs = env.reset()
print(obs.shape) # (210, 160, 3)
DI-engine Mirror¶
DI-engine has a mirror including the system itself and Atari environment. You can acquire through command docker pull opendilab/ding:nightly-atari , or visit docker
hub.
Space before transformation (Original environment)¶
Observation Space¶
Real game screen. RGB 3-channel image. Shape is
(210, 160, 3). Data type isuint8.
Action Space¶
Buttons used in the game. In general N discrete action (N is different in different sub environments). Data type is
int. Users should pass python integer (Or 0-dim np.nndarray, e.g. action 3 isnp.array(3))Meaning of the actions. For example in Pong, N=6, i.e. action ranges in [0, 5]:
0:NOOP
1:UP
2:LEFT
3:RIGHT
4:DOWN
5:FIRE
Reward Space¶
Game score. Different massively in different sub environments. In general a
float. Detailed number can be found in Algorithm Benchmark at the bottom of this page.
Others¶
A game ending is an episode ending.
Key Facts¶
2D RGB 3-channel input. However, single frame does not have enought information (e.g. moving direction). Many stacks of images should be stacked.
Discrete action space.
Includes not only dense reward (e.g. Space Invaders), but also sparse reward (e.g. Pitfall,MontezumaRevenge).
Reward has a large range scale.
Space after transformation (RL environment)¶
Observation Space¶
Method: Greyscale image, space zoom, min-max scaling, frame stack(N=4)
Result: 3-dim
np.ndarray. Shape is(4, 84, 84). 4 stands for 4 continuous frame. Data type isnp.float32. Data range is[0, 1].
Action Space¶
Basically no transformation. Still N discrete action, but in general 1-dim
np.ndarray. Shape is(1, ). Data type isnp.int64.
Reward Space¶
Method: Reward zoom and truncate
Result: 1-dim
np.ndarray. Shape is(1, ). Data type isnp.float32. Data range is[-1, 1].
The RL environment can be described in gym as:
import gym
obs_space = gym.spaces.Box(low=0, high=1, shape=(4, 84, 84), dtype=np.float32)
act_space = gym.spaces.Discrete(6)
rew_space = gym.spaces.Box(low=-1, high=1, shape=(1, ), dtype=np.float32)
Other¶
epsiode_life: Useepisode_lifeduring training, i.e. Player has several lives (In general 5). One fail cause one minus in lives. Only after lives equals to 0, the episode is regarded to an ending.noop_reset: When the environment is reset, in the first x original game frames (1 <= x <= 30), the player would perform an empty action (i.e. NOOP). This is aimed to increase the randomness of the environment’s at the beginning.Environment
stepmethod returnedinfos must containeval_episode_returnkey-value pair, indicating the entire episode’s performance. In Atari, it is the cumulative episode reward.
Other¶
Lazy initialization¶
In order to support environment vetorization, an environment instance is oftern initialized lazily. In this way, method __init__ does not really initialize the real original environment, but only set corresponding parameters and configurations. The real original environment is initialized when first calling mdthod reset.
Random Seed¶
There are two random seeds in the environment. One is orignal environment’s random seed; The other is the random seed which is required in many environment space transformations. (e.g.
random,np.random)As a user, you only need to set these two random seeds by calling method
seed, and do not need to care about the implementation details.Implementation details: For orignal environment’s random seed, within RL env’s
resetmethod; Before orginal env’sresetmethod.Implementation details: For the seed for
random/np.random, within env’sseedmethod.
Difference Between Training Env And Evaluation Env¶
Training env uses dynamic random seed, i.e. Every episode has different random seeds generated by one random generator. However, this random generator’s random seed is set by env’s
seedmethod, and is fixed throughout an experiment. Evaluation env uses static random seed, i.e. Every episode has the same random seed, which is set directly byseedmethod.Training env and evaluation env use different pre-process wrappers.
episode_lifeandclip_rewardare not used in evaluation env.
Save the Replay Video¶
After env is initiated, and before it is reset, call enable_save_replay method to set where the replay video will be saved. Environment will automatically save the replay video after each episode is completed. (The default call is gym.wrappers.RecordVideo). The code shown below will run an environment episode and save the replay viedo in folder ./video/.
from easydict import EasyDict
from dizoo.atari.envs import AtariEnv
env = AtariEnv(EasyDict({'env_id': 'Breakout-v0', 'is_train': False}))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo Code Example¶
Complete training configuration is at github
link.
For specific configuration file, e.g. pong_dqn_config.py, you can run the demo as shown below:
from easydict import EasyDict
pong_dqn_config = dict(
env=dict(
collector_env_num=8,
evaluator_env_num=8,
n_evaluator_episode=8,
stop_value=20,
env_id='PongNoFrameskip-v4',
frame_stack=4,
),
policy=dict(
cuda=True,
priority=False,
model=dict(
obs_shape=[4, 84, 84],
action_shape=6,
encoder_hidden_size_list=[128, 128, 512],
),
nstep=3,
discount_factor=0.99,
learn=dict(
update_per_collect=10,
batch_size=32,
learning_rate=0.0001,
target_update_freq=500,
),
collect=dict(n_sample=96, ),
eval=dict(evaluator=dict(eval_freq=4000, )),
other=dict(
eps=dict(
type='exp',
start=1.,
end=0.05,
decay=250000,
),
replay_buffer=dict(replay_buffer_size=100000, ),
),
),
)
pong_dqn_config = EasyDict(pong_dqn_config)
main_config = pong_dqn_config
pong_dqn_create_config = dict(
env=dict(
type='atari',
import_names=['dizoo.atari.envs.atari_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(type='dqn'),
)
pong_dqn_create_config = EasyDict(pong_dqn_create_config)
create_config = pong_dqn_create_config
if __name__ == '__main__':
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
Note: For some specific algorithm, e.g. PPG, you use specific entry function. You can refer to link.
Algorithm Benchmark¶
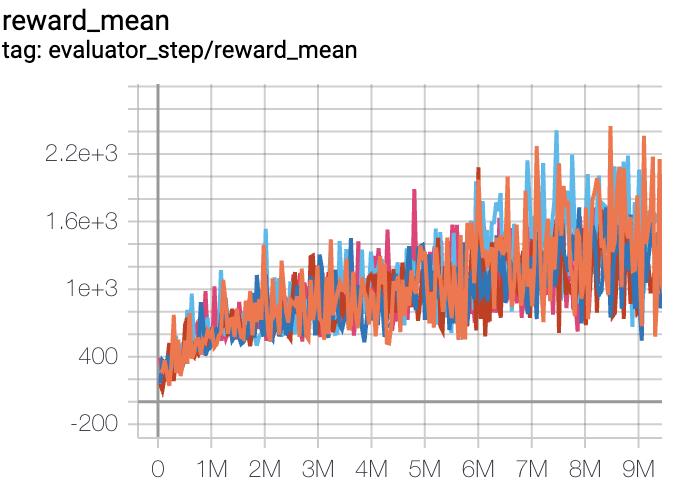
Pong (Average reward >= 20 is regarded as a good agent)
Pong + DQN
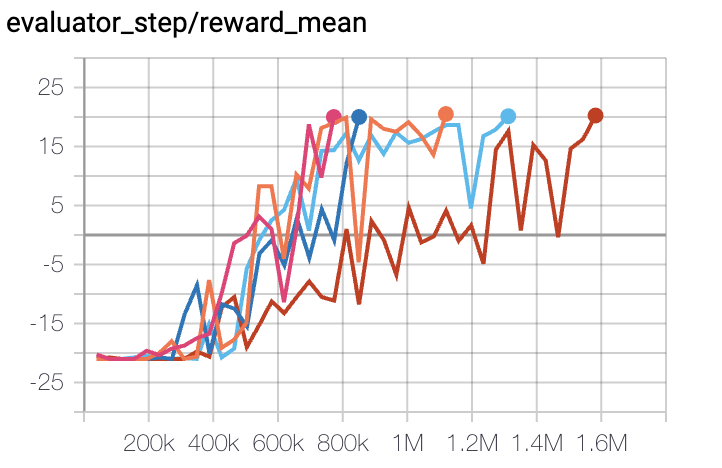
Qbert (Average reward > 15000 at 10M env step)
Qbert + DQN
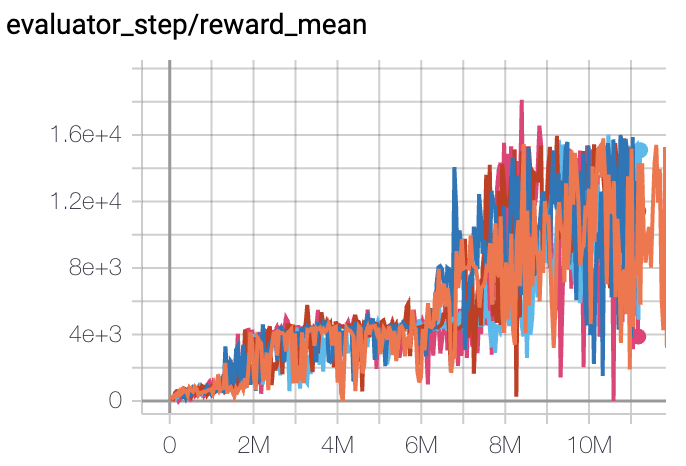
Space Invaders (Average reward > 1000 at 10M env step)
Space Invaders + DQN