bsuite is a collection of carefully-designed experiments that investigate core capabilities of a reinforcement learning (RL) agent with two main objectives:
To collect clear, informative and scalable problems that capture key issues in the design of efficient and general learning algorithms.
To study agent behavior through their performance on these shared benchmarks.
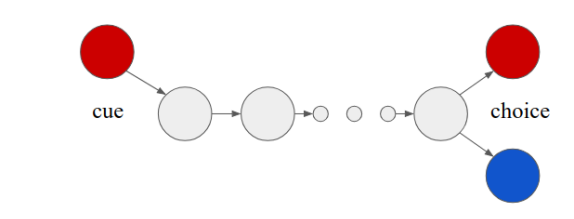
Here we take Memory Length as an example environment to illustrate below. It’s designed to test the number of sequential steps an agent can remember a single bit. The underlying environment is based on a stylized T-maze problem, parameterized by a length \(N \in \mathbb{N}\).
Each episode lasts N steps with observation \(o_t=\left(c_t, t / N\right)\) and
action space \(\mathcal{A}=\{-1,+1\}\).
At the beginning of the episode the agent is provided a context of +1 or -1, which means \(c_1 \sim {Unif}(\mathcal{A})\).
At all future timesteps the context is equal to zero and a countdown until the end of the episode, which means \(c_t=0\) for all \(t>2\).
At the end of the episode the agent must select the correct action corresponding to the context to reward. The reward \(r_t=0\) for all \(t<N\), and \(r_N={Sign}\left(a_N=c_1\right)\)
The observation of agent is a 3-dimensional vector. Data type is float32. Their specific meaning is as below:
obs[0] shows the current time, ranging from [0, 1].
obs[1] shows the query as an integer number between 0 and num of bit at the last step. It’s always 0 in memory length experiment because there is only a single bit. (It’s useful in memory size experiment.)
obs[2] shows the context of +1 or -1 at the first step. At all future timesteps the context is equal to 0 and a countdown until the end of the episode
We can change the memory length N to make it gradually more challenging.
Discrete actions space.
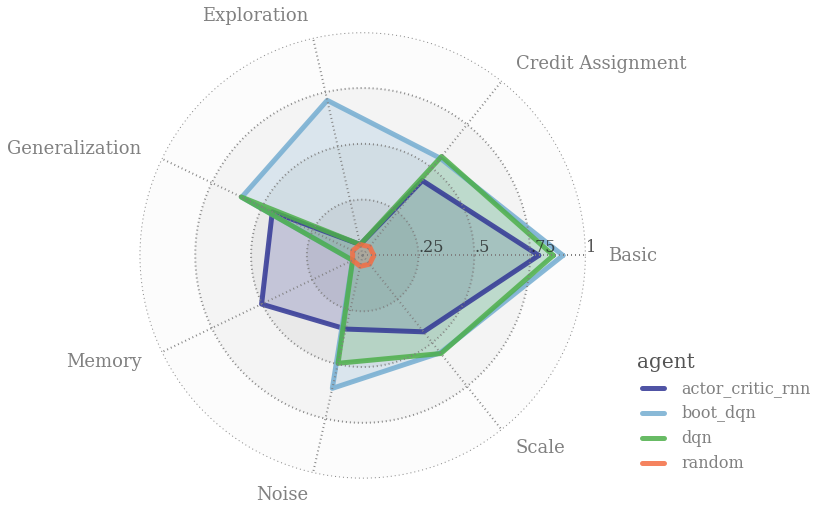
Each environment is designed to test a particular propriety of RL policies, including: generalization, exploration, credit assignment, scaling, noise, memory.
Our implementation uses the bsuite Gym wrapper to make the bsuite codebase run under the OpenAI Gym interface. Hence, gym needs to be installed to make bsuite work properly.
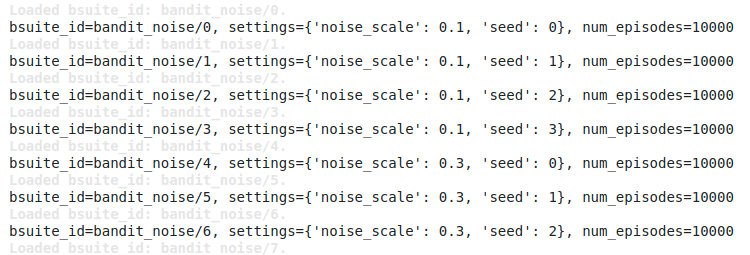
Configurations are designed to increase the level of difficulty of an environment. For example, in a 5-armed bandit environment, configurations are used to regulate the level of noise to perturb the rewards.
Given a specific environment, all possible configurations can be visualized with the following code snippet.
frombsuiteimportsweep# this module contains information about all the environmentsforbsuite_idinsweep.BANDIT_NOISE:env=bsuite.load_from_id(bsuite_id)print('bsuite_id={}, settings={}, num_episodes={}'.format(bsuite_id,sweep.SETTINGS[bsuite_id],env.bsuite_num_episodes))
Using DI-engine, you can create a bsuite environment simply with the name of your desired configuration.
The full training configuration can be found on github
link
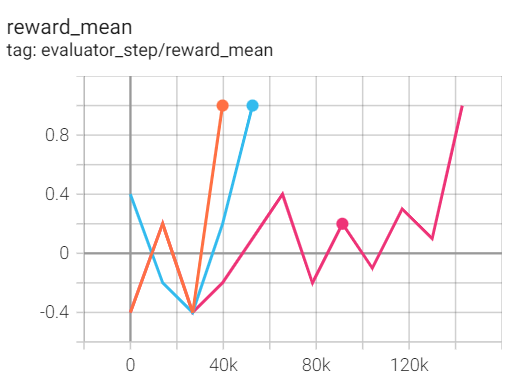
. In the following part, we show an example of configuration for the file, memory_len_0_dqn_config.py, you can run the demo with the following code: