D4RL (MuJoCo)¶
Abstract¶
D4RL is an open source benchmark for offline Reinforcement Learning, which provides a standardized environment and dataset for training and benchmarking algorithms. The collecting strategy of datasets includes:
datasets generated by hand-designed rules and expert demonstrations
nulti-task datasets (agents performing different tasks in the same environment)
datasets collected with hybrid strategies
Specifically, the following seven sub-environments are included
Maze2D
AntMaze
Gym-MuJoco
Adroit
FrankaKitchen
Flow
Offline CARLA
Note: offline RL is trained on the d4rl and tested by interacting with a specific RL environment, such as Mujoco.
The Mujoco dataset is a physics engine designed to facilitate research and development in areas such as robotics, biomechanics, graphics, and animation that require fast and accurate simulations, and is often used as a benchmark testing environment for continuous space reinforcement learning algorithms. It is a collection of 20 subenvironments, in D4RL the subenvironments used are Half Cheetah, Hopper, and Walker2D. Each subenvironment contains 5 smaller subenvironments.
expert: train a SAC algorithm online until the strategy reaches the expert performance level, using the expert strategy to collect 1 million samples of data
medium-expert: mix equal amounts of data collected by expert and medium strategies
medium: first train a SAC algorithm online, stop training in the middle, and then use this partially trained strategy to collect 1 million samples of data
medium-replay:train a SAC algorithm online until the strategy reaches a moderate performance level, collecting all the samples placed in the buffer during training
random:use a random initialization strategy to collect
The picture below shows one of the Hopper games.

Installation¶
Method¶
Installing d4rl, gym and mujoco-py, and d4rl can be installed with one click via pip or via clone
# pip install
pip install git+https://github.com/rail-berkeley/d4rl@master#egg=d4rl
# installed by cloning the repository
git clone https://github.com/rail-berkeley/d4rl.git
cd d4rl
pip install -e .
For mujoco, you only need to install gym and mujoco-py, either via pip or in combination with DI-engine
The mujoco-py library no longer requires an active license (
mujoco-py>=2.1.0) and can be installed via pip install free-mujoco-pyIf you install
mujoco-py>=2.1, you can do the following:
# Installation for Linux
# Download the MuJoCo version 2.1 binaries for Linux.
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-linux-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
# Installation for macOS
# Download the MuJoCo version 2.1 binaries for OSX.
wget https://mujoco.org/download/mujoco210-macos-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
If you install
mujoco-py<2.1, you can do the following:
# Installation for Linux
# Download the MuJoCo version 2.0 binaries for Linux.
wget https://www.roboti.us/download/mujoco200_linux.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
unzip mujoco200_linux.zip && mkdir -p ~/.mujoco && mv mujoco200_linux ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
# Installation for macOS
# Download the MuJoCo version 2.0 binaries for OSX.
wget https://www.roboti.us/download/mujoco200_macos.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
tar xvf mujoco200-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco200_macos ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
Verifying the Installation¶
Once the installation is complete, you can verify that the installation was successful by running the following command from the Python command line.
import gym
import d4rl # Import required to register environments
# Create the environment
env = gym.make('maze2d-umaze-v1')
# d4rl abides by the OpenAI gym interface
env.reset()
env.step(env.action_space.sample())
# Each task is associated with a dataset
# dataset contains observations, actions, rewards, terminals, and infos
dataset = env.get_dataset()
print(dataset['observations']) # An N x dim_observation Numpy array of observations
# Alternatively, use d4rl.qlearning_dataset which
# also adds next_observations.
dataset = d4rl.qlearning_dataset(env)
Images¶
The DI-engine is ready with images of the framework itself, which can be obtained by docker pull opendilab/ding:nightly-mujoco , or by visiting docker
hub for more images.
Gym-Mujoco’s Space before Transformation (Original Environment)¶
Observation space¶
The vector consists of physical information(3D position, orientation, and joint angles etc.), and the specific size is
(N, ), which is determined by the environment. The data type isfloat64Fujimoto mentions that doing obs norm for the d4rl dataset will improve the stability of offline training.
Action Space¶
The vector consists of physical information(torque etc.), which is often a continuous action space with N dimension (N varies with specific subenvironments), the data type is
float32, np datasets need to be imported.(For example, the action isarray([-0.9266078 , -0.4958926 , 0.46242517], dtype=float32))For example, if it’s in the Hooper, N is 3, then the action value be chosen in
[-1, 1].
Reward space¶
Depending on the specific game content, the game score can vary very much and is usually a float value, which can be found in the performance section of the benchmark algorithm at the bottom.
Others¶
The end of the game is the end of the current environment episode
Key Facts¶
Vector physical information input, empirically it is not advisable to subtract the mean value in normalization
Continuous action space
Dense rewards
Large variation in the scale of reward taking
The Space after Transformation(RL Environment)¶
Observation space¶
Basically no change
Action space¶
Basically no transformation, still a continuous action space of size N, with a range of values
[-1, 1],size is(N, ),data type isnp.float32
Reward space¶
Basically no change
The above space can be represented using the gym environment space definition as follows
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(11, ), dtype=np.float64)
act_space = gym.spaces.Box(low=-1, high=1, shape=(3, ), dtype=np.float32)
rew_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(1, ), dtype=np.float32)
Others¶
The
inforeturned by the environmentstepmethod must contain thefinal_eval_rewardkey-value pair, which represents the evaluation metrics for the entire episode, which in Mujoco is the cumulative sum of the rewards for the entire episode.
Others¶
Inert initialization¶
To facilitate support for parallel operations such as environment vectorization, environment instances are generally implemented with inert initialization, i.e., the _init_method does not initialize the real original environment instance, but only sets the relevant parameters and configuration values, and initializes the concrete original environment instance when the resetmethod is called for the first time.
Video storage¶
After the environment is created and before it is reset, the enable_save_replaymethod is called to specify the path where the game footage is saved. The environment will automatically save the session’s video files after each episode. (The default call gym.wrappers.RecordVideois implemented), the code shown below will run an environment episode and save the results of that episode in ./video/.
from easydict import EasyDict
from dizoo.mujoco.envs import MujocoEnv
env = MujocoEnv(EasyDict({'env_id': 'Hoopper-v3' }))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, final eval reward is: {}'.format(timestep.info['final_eval_reward']))
break
DI-ZOO RUNNABLE CODE EXAMPLE¶
The complete training profile is available in github link
, for specific profiles, like https://github.com/opendilab/DI-engine/blob/main/dizoo/d4rl/config/hopper_medium_cql_default_config.py,it works with the following demo:
from easydict import EasyDict
from easydict import EasyDict
hopper_medium_cql_default_config = dict(
env=dict(
env_id='hopper-medium-v0',
norm_obs=dict(use_norm=False, ),
norm_reward=dict(use_norm=False, ),
collector_env_num=1,
evaluator_env_num=8,
use_act_scale=True,
n_evaluator_episode=8,
stop_value=6000,
),
policy=dict(
cuda=True,
model=dict(
obs_shape=11,
action_shape=3,
twin_critic=True,
actor_head_type='reparameterization',
actor_head_hidden_size=256,
critic_head_hidden_size=256,
),
learn=dict(
data_path=None,
train_epoch=30000,
batch_size=256,
learning_rate_q=3e-4,
learning_rate_policy=1e-4,
learning_rate_alpha=1e-4,
ignore_done=False,
target_theta=0.005,
discount_factor=0.99,
alpha=0.2,
reparameterization=True,
auto_alpha=False,
lagrange_thresh=-1.0,
min_q_weight=5.0,
),
collect=dict(
n_sample=1,
unroll_len=1,
data_type='d4rl',
),
command=dict(),
eval=dict(evaluator=dict(eval_freq=500, )),
other=dict(replay_buffer=dict(replay_buffer_size=2000000, ), ),
),
)
hopper_medium_cql_default_config = EasyDict(hopper_medium_cql_default_config)
main_config = hopper_medium_cql_default_config
hopper_medium_cql_default_create_config = dict(
env=dict(
type='d4rl',
import_names=['dizoo.d4rl.envs.d4rl_env'],
),
env_manager=dict(type='base'),
policy=dict(
type='cql',
import_names=['ding.policy.cql'],
),
replay_buffer=dict(type='naive', ),
)
hopper_medium_cql_default_create_config = EasyDict(hopper_medium_cql_default_create_config)
create_config = hopper_medium_cql_default_create_config
Note: For offline RL algorithms, such as TD3_bc, CQL, you need to use a special entry function, the example can be referred to link
BENCHMARK ALGORITHM PERFORMANCE¶
Walker2d
walker2d-medium-expert-v0 + CQL
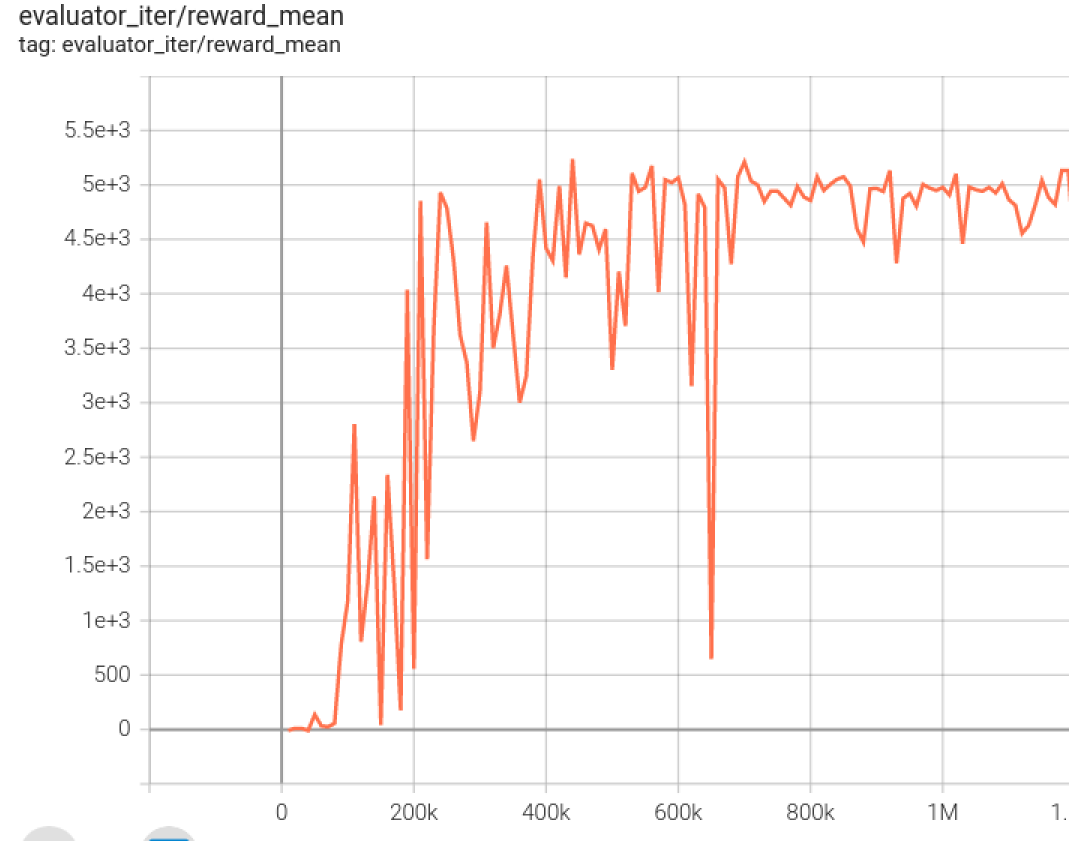
Typical iteration of 1M iteration takes 9 hours (NVIDIA V100)