dmc2gym¶
Overview¶
dmc2gym is a light wrapper for DeepMind Control Suite , providing standard OpenAI Gym interface. DeepMind Control Suite is a set of continuous control tasks with standardized structures and interpretable rewards intended as a performance benchmark for reinforcement learning agents.
Installation¶
Method¶
\ gym\ , \ dm_control \ and \ dmc2gym \ are required to be installed, and users could install from PyPI with the following command: (Please kindly notice dm_control should you have further problems, please refer to the official related instructions)
Note: If you need to install the corresponding package to the user directory (If the user does not own root authority,then the corresponding package needs to be installed to the user directory),please add --user after the install command.
# Install Directly
pip install gym
pip install dm_control
pip install git+git://github.com/denisyarats/dmc2gym.git
Verify Installation¶
After the installation is complete, you can verify that the installation was successful by running the following command on the Python command line:
import dmc2gym
env = dmc2gym.make(domain_name='point_mass', task_name='easy', seed=1)
obs = env.reset()
print(obs.shape) # (4,)
Image¶
DI-engine image comes with the framwork and the dmc2gym environment, which is available via docker pull opendilab/ding:nightly-dmc2gym, or by visitingdocker hubto get more images.
Environment Introduction¶
select task¶
dm_control contains multiple domains (physical models), and different domains have different tasks (instances of models with specific MDP structures). We have temporarily implemented the following domain and task here:
Ball in cup

Flact Ball Cup task. A driven plane container can translate in a vertical plane in order to swing and catch a ball attached to its base. The reward for the catch task is 1 when the ball is in the cup, and 0 otherwise.
catch
Cart-pole

Conforms to the physical model proposed by Barto et al. 1983. The target is to swing and balance the unactuated pole by applying force to the cart at its bottom. This environment implements the following tasks
balance: the initial bar is close to the post
swingup: the initial bar points down
Cheetah

Planar running bipeds, based on the model proposed by Wawrzyński et al. 2009, reward
rand speed of advancevhas a linear relationship,vis up to 10m/s,r(v) = max(0, min(v/10, 1)).run
Finger

Based on the problem of the 3-DOF toy manipulation problem proposed by Tassa et al. 2010. A “finger” is used on the plane to rotate the object on a hinge with no other driving force, so that the tip of the object overlaps the target.
spin: In this task, the object must be constantly spinning.
Reacher
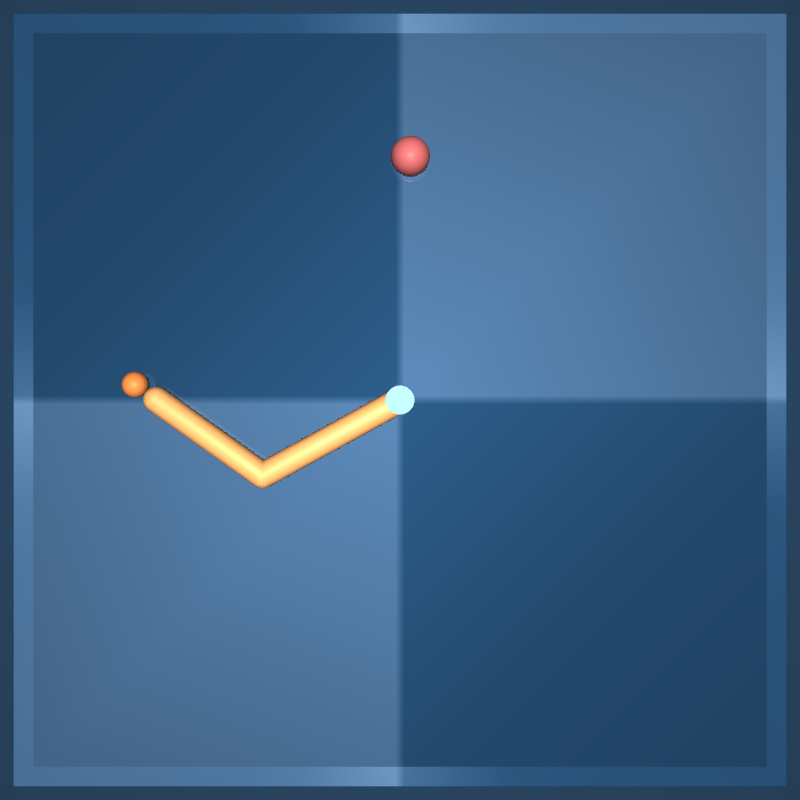
Simple two-link planar stretcher with random target positions. The reward is 1 when the end of the rod penetrates the target sphere.
easy: The target sphere is bigger than in hard missions.
Walker

An improved planar walker based on the Lillicrap et al. 2015model. The walk task contains a component incentive to move forward quickly.
walk
Called by setting the parameters domain_name,task_name:
e.g
env = DMC2GymEnv(EasyDict({
"domain_name": "cartpole",
"task_name": "balance",
}))
The corresponding state space, action space, observation space
(dim(S), dim(A), dim(O))are shown in the following table:
Domain |
Task |
dim(S) |
dim(A) |
dim(O) |
|---|---|---|---|---|
ball in cup |
catch |
8 |
2 |
8 |
cart-pole |
balance |
4 |
1 |
5 |
swingup |
4 |
1 |
5 |
|
cheetah |
run |
18 |
6 |
17 |
finger |
spin |
6 |
2 |
12 |
reacher |
easy |
4 |
2 |
7 |
walker |
walk |
18 |
6 |
24 |
Note
The task in dm_control follows the Markov Decision Process (MDP).
State
sis a real vector except for the spatial direction \(\cal{S} \equiv \mathbb{R}^{dim(\cal{S})}\) , where the spatial direction is represented by Unit quaternion \(\in SU(2)\)Observation
o(s, a)describes the state that the agent can observe. The tasks we implement are all strongly observable, that is, the state can be recovered from a single observation. The observed features that depend only on the state (position and velocity) are a function of the current state. Observations that also depend on controls (such as touch sensor readings) are functions of previous transitions.
Obervation Space¶
Based on Image Observation¶
When setting
from_pixels=True, the observation space is a three-channel game image with height and width respectively.The size of the observed image can be adjusted by setting the
height, widthparameters.Observe the specific shape of the observation space by setting
channels_first.channels_first=True, observation shape is[3, height, width]channels_first=False, observation shape is[height, width, 3]
The range of a single pixel value for each channel is
[0, 255], and the data type isuint8
Non-Image Based Observation¶
When
from_pixels=Falseis set, the observation space dimension followsdim(O)in the above tableThe default range is
[-inf, inf]
Action Space¶
Action space dimensions follow
dim(A)in the above tabledmc2gym normalizes the action space, the range of each dimension is
[-1, 1], the type isfloat32.
Reward Space¶
Image Based Observation¶
It is related to the
frame_skipparameter, which means that each step is based on the image offrame_skipframe , and the dimension is(1,)The range is
[0, frame_skip], the type isfloat32, defaultframe_skip = 1The reward space of each frame is
[0, 1], and the reward offrame_skipare superimposed together as the overall reward
Non-Image Based Observation¶
The dimension is
(1, ), the range is[0, 1], the type isfloat32.
Other¶
Abort Condition¶
Control tasks are divided into finite-horizon, firstexit and infinite-horizon. DeepMind Control Suite belongs to infinite-horizon, so there is no aborted state or time limit for tasks.
Lazy Initialization¶
In order to facilitate parallel operations such as environment vectorization, environment instances generally implement lazy initialization , which means __init__method does not initialize the real original environment instance, but only sets relevant parameters and configuration values. The concrete original environment instance is initialized when the resetmethod is used.
Random Seeds¶
There are two parts of random seeds in the environment that need to be set, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations(such as
random,np.random)For the environment caller, just set two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation details.
Concrete implementation inside the environment¶
For the seed of the original environment, set in the
resetmethods of the environment calling function , before the concrete environment implementationresetFor random library seeds, set the value directly in the
seedmethod of the environment ; for the seed of the original environment, inside theresetmethod of the calling environment, the specific original environmentresetwas previously set to seed + np_seed, where seed is the value of the aforementioned random library seed, np_seed = 100 * np.random.randint(1, 1000).
Store Video¶
After the environment is created, but before reset, call the enable_save_replaymethod,to specify the path to save the game recording. The environment will automatically save the local video files after each episode ends. (The default implementation of calling gym.wrappers.RecordVideo),the code shown below will run an environment episode and save the results of this episode in ./video/:
from easydict import EasyDict
from dizoo.dmc2gym.envs import DMC2GymEnv
env = DMC2GymEnv(EasyDict({
"domain_name": "cartpole",
"task_name": "balance",
"frame_skip": 2,
"from_pixels": True,
}))
env.enable_save_replay(replay_path='./video')
env.seed(314, dynamic_seed=False)
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo Runnable Code Example¶
The complete example file is at github link
from easydict import EasyDict
cartpole_balance_ddpg_config = dict(
exp_name='dmc2gym_cartpole_balance_ddpg_eval',
env=dict(
env_id='dmc2gym_cartpole_balance',
domain_name='cartpole',
task_name='balance',
from_pixels=False,
norm_obs=dict(use_norm=False, ),
norm_reward=dict(use_norm=False, ),
collector_env_num=1,
evaluator_env_num=8,
use_act_scale=True,
n_evaluator_episode=8,
replay_path='./dmc2gym_cartpole_balance_ddpg_eval/video',
stop_value=1000,
),
policy=dict(
cuda=True,
random_collect_size=2560,
load_path="./dmc2gym_cartpole_balance_ddpg/ckpt/iteration_10000.pth.tar",
model=dict(
obs_shape=5,
action_shape=1,
twin_critic=False,
actor_head_hidden_size=128,
critic_head_hidden_size=128,
action_space='regression',
),
learn=dict(
update_per_collect=1,
batch_size=128,
learning_rate_actor=1e-3,
learning_rate_critic=1e-3,
ignore_done=False,
target_theta=0.005,
discount_factor=0.99,
actor_update_freq=1,
noise=False,
),
collect=dict(
n_sample=1,
unroll_len=1,
noise_sigma=0.1,
),
other=dict(replay_buffer=dict(replay_buffer_size=10000, ), ),
)
)
cartpole_balance_ddpg_config = EasyDict(cartpole_balance_ddpg_config)
main_config = cartpole_balance_ddpg_config
cartpole_balance_create_config = dict(
env=dict(
type='dmc2gym',
import_names=['dizoo.dmc2gym.envs.dmc2gym_env'],
),
env_manager=dict(type='base'),
policy=dict(
type='ddpg',
import_names=['ding.policy.ddpg'],
),
replay_buffer=dict(type='naive', ),
)
cartpole_balance_create_config = EasyDict(cartpole_balance_create_config)
create_config = cartpole_balance_create_config