gym hybrid¶
Overview¶
In the gym-hybrid task, the agent’s task is simple: Accelerate, turn, or break within a square box to stay in the green target area. The target area is a circle with flag. The example is shown below.
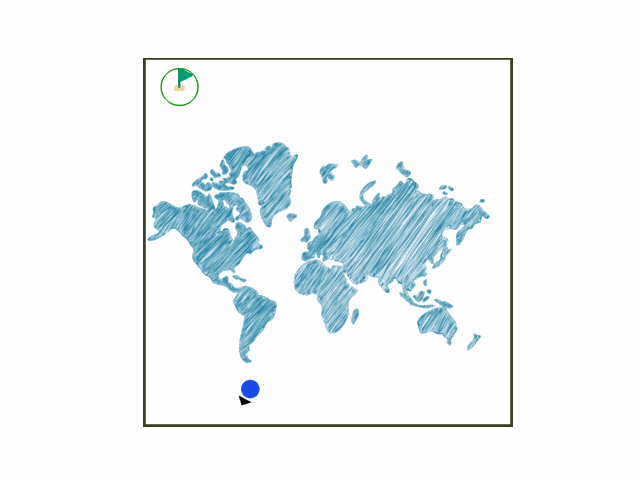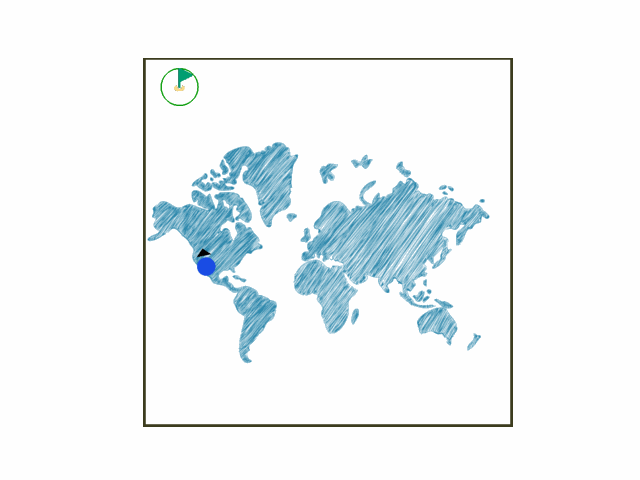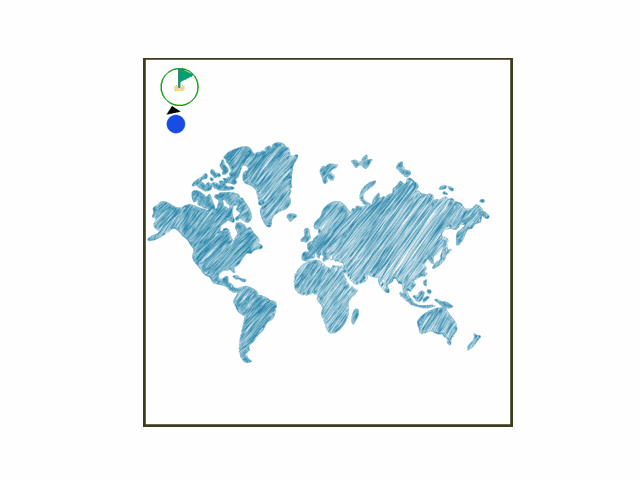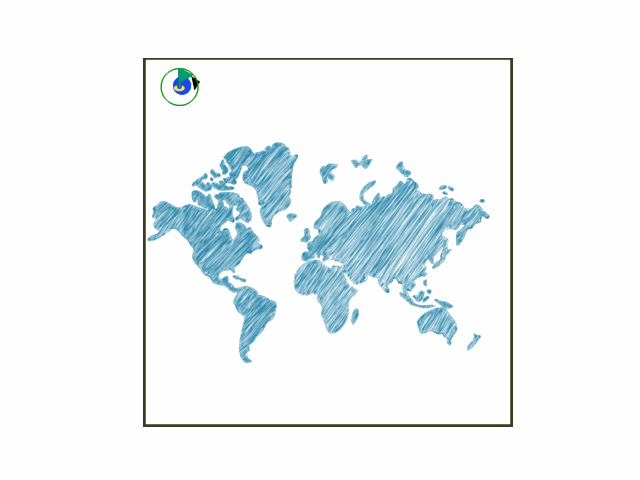
Install¶
Installation Method¶
cd ./DI-engine/dizoo/gym_hybrid/envs/gym-hybrid
pip install -e .
Verify Installation¶
Method 1: Run the following command, if the version information can be displayed normally, the installation is completed successfully.
pip show gym-hybrid
Method 2: Run the following Python program, if no error is reported, the installation is successful.
import gym
import gym_hybrid
env = gym.make('Moving-v0')
obs = env.reset()
print(obs)
Environment Introduction¶
Action Space¶
The action space of Gym-hybrid belongs to the mixed space of discrete continuous actions. There are 3 discrete actions: Accelerate, Turn, and Break. The actions Accelerate and Turn need to give the corresponding 1-dimensional continuous parameters.
Accelerate (Acceleration value): Indicates that the agent is accelerated by the size ofacceleration value. The value range ofAcceleration valueis[0,1]. The numeric type isfloat32.Turn (Rotation value): means to turn the agent in the direction ofrotation value. The value range ofRotation valueis[-1,1]. The numeric type isfloat32.Break (): means stop.
Using the gym environment space definition can be expressed as:
from gym import spaces
action_space = spaces.Tuple((spaces.Discrete(3),
spaces.Box(low=0, high=1, shape=(1,)),
spaces.Box(low=-1, high=1, shape=(1,))))
State Space¶
The state space of Gym-hybrid is represented by a list of 10 elements, which describes the current state of the agent, including the agent’s current coordinates, velocity, the sine and cosine of the orientation angle, the coordinates of the target, the distance between the agent and the target, and the target. Distance-related bool value, current relative steps.
state = [
agent.x,
agent.y,
agent.speed,
np.cos(agent.theta),
np.sin(agent.theta),
target.x,
target.y,
distance,
0 if distance > target_radius else 1,
current_step / max_step
]
Reward Space¶
The reward of each step is set as the length of the agent’s distance from the target after the action is performed in the previous step minus the length of the distance from the target after the current step performs the action, ie dist_t-1 - dist_t . The algorithm has a built-in penalty to motivate the agent to be faster
Achieve goals. When the episode ends, if the agent stops in the target area, it will get an additional reward with a value of 1; if the agent goes out of bounds or exceeds the maximum number of steps of the episode, it will not get additional reward. The reward at the current moment is expressed by the formula as follows:
reward = last_distance - distance - penalty + (1 if goal else 0)
Termination Condition¶
The termination condition for each episode of the Gym-hybrid environment is any of the following:
The agent successfully entered the target area
agant out of bounds
Reach the maximum step of the episode
Built-in Environment¶
There are two built-in environments, "Moving-v0" and "Sliding-v0" . The former does not consider conservation of inertia, while the latter does (so is more practical). The two environments are consistent in state space, action space, and reward space.
Other¶
Store Video¶
Some environments have their own rendering plug-ins, but DI-engine does not support the rendering plug-ins that come with the environment, but generates video recordings by saving the logs during training. For details, please refer to the Visualization & Logging section under the DI-engine official documentation Quick start chapter.
DI-zoo Runnable Code Example¶
The following provides a complete gym hybrid environment config, using DDPG as the baseline algorithm. Please run the gym_hybrid_ddpg_config.py file in the DI-engine/dizoo/gym_hybrid directory, as follows.
from easydict import EasyDict
from ding.entry import serial_pipeline
gym_hybrid_ddpg_config = dict(
exp_name='gym_hybrid_ddpg_seed0',
env=dict(
collector_env_num=8,
evaluator_env_num=5,
# (bool) Scale output action into legal range [-1, 1].
act_scale=True,
env_id='Moving-v0', # ['Sliding-v0', 'Moving-v0']
n_evaluator_episode=5,
stop_value=2, # 1.85 for hybrid_ddpg
),
policy=dict(
cuda=True,
priority=False,
random_collect_size=0, # hybrid action space not support random collect now
action_space='hybrid',
model=dict(
obs_shape=10,
action_shape=dict(
action_type_shape=3,
action_args_shape=2,
),
twin_critic=False,
actor_head_type='hybrid',
),
learn=dict(
action_space='hybrid',
update_per_collect=10, # [5, 10]
batch_size=32,
discount_factor=0.99,
learning_rate_actor=0.0003, # [0.001, 0.0003]
learning_rate_critic=0.001,
actor_update_freq=1,
noise=False,
),
collect=dict(
n_sample=32,
noise_sigma=0.1,
collector=dict(collect_print_freq=1000, ),
),
eval=dict(evaluator=dict(eval_freq=1000, ), ),
other=dict(
eps=dict(
type='exp',
start=1.,
end=0.1,
decay=100000, # [50000, 100000]
),
replay_buffer=dict(replay_buffer_size=100000, ),
),
),
)
gym_hybrid_ddpg_config = EasyDict(gym_hybrid_ddpg_config)
main_config = gym_hybrid_ddpg_config
gym_hybrid_ddpg_create_config = dict(
env=dict(
type='gym_hybrid',
import_names=['dizoo.gym_hybrid.envs.gym_hybrid_env'],
),
env_manager=dict(type='base'),
policy=dict(type='ddpg'),
)
gym_hybrid_ddpg_create_config = EasyDict(gym_hybrid_ddpg_create_config)
create_config = gym_hybrid_ddpg_create_config
if __name__ == "__main__":
serial_pipeline([main_config, create_config], seed=0, max_env_step=int(1e7))