Metadrive¶
Overview¶
MetaDrive Env is an efficient compositional driving simulator. The goal of the environment is to control a car (or multiple vehicles) from the starting point to the finishing point safely and on time. It has the following properties:
Compositional: It supports the generation of (theoretically infinite) scenarios with various road maps and traffic settings, which can be used in the study of RL generalization.
Lightweight: easy to install and operate. It can run up to 300 FPS on a standard PC.
High fidelity: Accurate physics simulations and multiple types of inputs, including lidar, RGB images, top-down semantic maps, and first-person imagery. Users can freely choose the type of observation. The following image introduces an example of observation.

Install¶
Installation Method¶
Users can choose to install it with one click through pip, or install it from source.
Note: If the user does not have root privileges, please add --user after the install command.
# Install Directly
pip install metadrive-simulator
# Install from source code
git clone https://github.com/metadriverse/metadrive.git
cd metadrive
pip install -e .
Verify Installation¶
After the installation is complete, you can verify that the installation was successful by running the following command on the Python command line:
from metadrive import MetaDriveEnv
env = MetadriveEnv()
obs = env.reset()
print(obs.shape) # output (259,)
Image¶
The image of DI-engine is equipped with the framework itself, which can be obtained by docker pull opendilab/ding:nightly ,
or by visiting docker hub for more images. Currently, MetaDrive doesn’t have a own image.
Space before Transformation (Original Environment)¶
For details, please refer to the code implementation of MetaDrive .
Observation space¶
The observation space of the vehicle is a 259-dimensional numpy array, the data type is float32, and the obs shape is (259,). The observation space consists of the following three parts:
ego_state : The current state, such as heading, steering, speed and relative distance to the boundary.
navigation: Navigation information that guides the vehicle to the destination passing through checkpoints.
surrounding: The surrounding information is generated by lidar, usually using 240 lasers to scan the adjacent area with a radius of 50 meters.
Action space¶
The action space of the MetaDrive environment is a 2-dimensional continuous action, and its valid range is [-1, 1]. Through this design, the action space of each agent is fixed as gym.spaces.Box(low=-1.0, high=1.0, shape=(2, )).
The first dimension represents the steering angle. When the action is 1 or -1, it means that the steering wheel is turned to the left or right to the maximum steering angle, and when it is 0, it means that the steering wheel is facing straight ahead.
The second dimension represents acceleration or braking. When the range is in the (0,1) interval, it means acceleration, and when the range is in (-1,0), it means braking; when it is 0, it means no action is taken.
At the same time, it also provides a configuration called extra_action_dim (int). For example, if we set config[“extra_action_dim”] = 1, then the action space of each agent will become Box(-1.0, 1.0, shape =(3, )). This allows users to write environment wrappers that introduce more dimensions of input operations.
Reward space¶
The default reward function in MetaDrive consists of a dense (obtained during driving) reward and a sparse final reward.
Dense Reward: Reflects the degree of longitudinal motion of the vehicle towards the destination in Frenet coordinates at each step.
Terminal Reward: Only obtained when the vehicle successfully reaches the destination. The details are described in termination_reward below.
MetaDrive provides a complex reward function. We can customize the reward function from the config dict. The complete reward function consists of the following four parts:
Driving reward (driving_reward): From t-1 to t time, the longitudinal distance along the current lane line. It is a dense reward.
Speed reward (speed_reward): The speed at the current moment. The greater the speed, the greater the reward, it is also a dense reward.
Lateral scale (use_lateral_reward): It provides a multiplier in the range [0, 1] indicating whether the ego vehicle is far from the center of the current lane, used in conjunction with the driving reward. If True, the size of the driving reward depends not only on the longitudinal distance, but also on the distance between the car and the middle of the lane line.
Terminal Reward (termination_reward): At the end of an episode, other dense rewards will be disabled and a final reward will be returned depending on the state of the vehicle. The specific situations can be divided into:
Reaching the destination: the vehicle gets a reward for successfully completing the goal (success_reward);
Going off the road: the vehicle gets a corresponding penalty (out_of_road_penalty);
Crash into another car: The vehicle gets a corresponding penalty (crash_vehicle_penalty);
Crashing into an obstacle: The vehicle gets a corresponding penalty (crash_object_penalty).
Other¶
An episode ends if:
The vehicle has successfully reached the destination;
The vehicle crashed into other vehicles or obstacles;
The vehicle got off the road.
Randomness:
Randomness at the initial moment: The vehicle will be randomly initialized to a certain lane line of a road.
Randomness of the road: Depending on the random seed, the number of lane lines, the splicing of different modules of the road, and the choice of the end point will vary.
Transformed space (RL environment)¶
Observation space¶
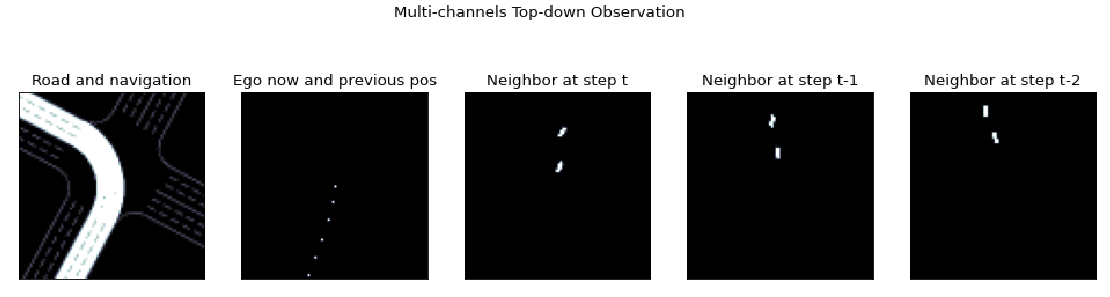
Different from the original version, the observation space is described as a 259-dimensional vector. In DI-engine, the observation space of the car is defined as a top view with a size of 5x84x84, where 5 represents the number of channels, and the last two dimensions (84x84) represent the size of the image for each channel. The semantics of the five channels are:
Road and Navigation;
Own position and own historical position (Ego now and previous pos);
Top view of surrounding vehicles at time t (Neighbor at step t);
Top view of surrounding vehicles at time t-1 (Neighbor at step t-1);
Top view of surrounding vehicles at step t-2 (Neighbor at step t-2).
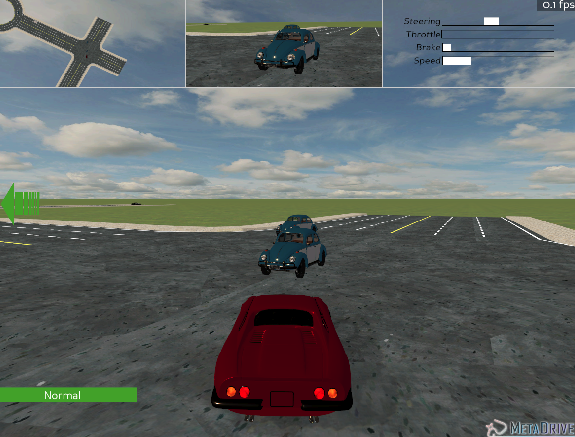
- In the figure below, a driving scene is given as an example. The red vehicle is the agent we control. It is performing a left turn and interacting with two adjacent blue vehicles.
- In the current scenario, the observation of the vehicle can be represented by the following five pictures.
Action Space¶
no change
Reward Space¶
no change
Other¶
The
inforeturned by the environmentstepmethod must contain theeval_episode_returnkey-value pair, which represents the evaluation index of the entire episode, and is the cumulative sum of the rewards of the entire episode in MetaDrive.
Other¶
Lazy Initialization¶
In order to support parallel operations such as environment vectorization, the specific environment instance generally adopts the lazy initialization method, that is, the __init__ method of the environment does not initialize the real original environment instance, but only sets relevant parameters and configuration values.
Instead, the concrete original environment instance is initialized when the reset method is called for the first time.
Random Seed¶
You can use the _reset_global_seed method to set the random seed of the environment. If you do not set it manually, the environment will randomly sample the random seed setting environment.
The difference between training and evaluation environments¶
The training environment uses a dynamic random seed, that is, the random seed of each episode is different and is generated by a random number generator, but the seed of this random number generator is fixed by the
seedmethod of the environment .The test environment uses a static random seed, that is, the random seed of each episode is the same, and is specified by the
seedmethod.
DI-zoo runnable code¶
The training configuration files of each algorithm in this environment are in the directory github
link.
Here, for a specific configuration file, such as metadrive_onppo_config.py , use the following demo to run:
from easydict import EasyDict
from functools import partial
from tensorboardX import SummaryWriter
import metadrive
import gym
from ding.envs import BaseEnvManager, SyncSubprocessEnvManager
from ding.config import compile_config
from ding.model.template import QAC, VAC
from ding.policy import PPOPolicy
from ding.worker import SampleSerialCollector, InteractionSerialEvaluator, BaseLearner
from dizoo.metadrive.env.drive_env import MetaDrivePPOOriginEnv
from dizoo.metadrive.env.drive_wrapper import DriveEnvWrapper
metadrive_basic_config = dict(
exp_name='metadrive_onppo_seed0',
env=dict(
metadrive=dict(
use_render=False,
traffic_density=0.10,
map='XSOS',
horizon=4000,
driving_reward=1.0,
speed_reward=0.1,
use_lateral_reward=False,
out_of_road_penalty=40.0,
crash_vehicle_penalty=40.0,
decision_repeat=20,
out_of_route_done=True,
),
manager=dict(
shared_memory=False,
max_retry=2,
context='spawn',
),
n_evaluator_episode=16,
stop_value=255,
collector_env_num=8,
evaluator_env_num=8,
),
policy=dict(
cuda=True,
action_space='continuous',
model=dict(
obs_shape=[5, 84, 84],
action_shape=2,
action_space='continuous',
bound_type='tanh',
encoder_hidden_size_list=[128, 128, 64],
),
learn=dict(
epoch_per_collect=10,
batch_size=64,
learning_rate=3e-4,
entropy_weight=0.001,
value_weight=0.5,
clip_ratio=0.02,
adv_norm=False,
value_norm=True,
grad_clip_value=10,
),
collect=dict(n_sample=3000, ),
eval=dict(evaluator=dict(eval_freq=1000, ), ),
),
)
main_config = EasyDict(metadrive_basic_config)
def wrapped_env(env_cfg, wrapper_cfg=None):
return DriveEnvWrapper(MetaDrivePPOOriginEnv(env_cfg), wrapper_cfg)
def main(cfg):
cfg = compile_config(
cfg, SyncSubprocessEnvManager, PPOPolicy, BaseLearner, SampleSerialCollector, InteractionSerialEvaluator
)
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env = SyncSubprocessEnvManager(
env_fn=[partial(wrapped_env, cfg.env.metadrive) for _ in range(collector_env_num)],
cfg=cfg.env.manager,
)
evaluator_env = SyncSubprocessEnvManager(
env_fn=[partial(wrapped_env, cfg.env.metadrive) for _ in range(evaluator_env_num)],
cfg=cfg.env.manager,
)
model = VAC(cfg.policy.model)
policy = PPOPolicy(cfg.policy, model=model)
tb_logger = SummaryWriter('./log/{}/'.format(cfg.exp_name))
learner = BaseLearner(cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name)
collector = SampleSerialCollector(
cfg.policy.collect.collector, collector_env, policy.collect_mode, tb_logger, exp_name=cfg.exp_name
)
evaluator = InteractionSerialEvaluator(
cfg.policy.eval.evaluator, evaluator_env, policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
learner.call_hook('before_run')
while True:
if evaluator.should_eval(learner.train_iter):
stop, rate = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop:
break
# Sampling data from environments
new_data = collector.collect(cfg.policy.collect.n_sample, train_iter=learner.train_iter)
learner.train(new_data, collector.envstep)
learner.call_hook('after_run')
collector.close()
evaluator.close()
learner.close()
if __name__ == '__main__':
main(main_config)
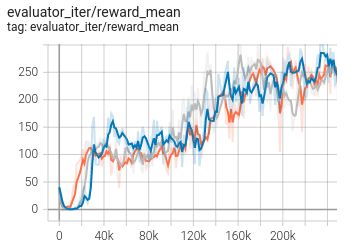
Benchmark Algorithm Performance¶
MetaDrive (the average episode return of the test episodes is greater than or equal to 250, which is regarded as the algorithm converges to an approximate optimal value).
MetaDrive + PPO