First Reinforcement Learning Program¶
Reinforcement learning is a promising algorithm for making a decision-intelligence artificial agent, among many machine learning algorithms. CartPole is the ideal learning environment for an introduction to reinforcement learning, and using the DQN algorithm allows CartPole to converge (maintain equilibrium) in a very short time. We will introduce the use of DI-engine based on CartPole + DQN.
Using the Configuration File¶
The DI-engine uses a global configuration file to control all variables of the environment and strategy, each of which has a corresponding default configuration that can be found in cartpole_dqn_config, in the tutorial we use the default configuration directly:
from dizoo.classic_control.cartpole.config.cartpole_dqn_config import main_config, create_config
from ding.config import compile_config
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
Initialize the Environments¶
In reinforcement learning, there may be a difference in the strategy for collecting environment data between the training process and the evaluation process, for example, the training process tends to train one epoch for n steps of collection, while the evaluation process requires completing the whole game to get a score. We recommend that the collection and evaluation environments be initialized separately as follows.
from ding.envs import DingEnvWrapper, BaseEnvManagerV2
collector_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
Note
DingEnvWrapper is a unified wrapper of DI-engine for different environment libraries. BaseEnvManagerV2 is a unified external interface for managing multiple environments. so you can use BaseEnvManagerV2 to collect multiple environments in parallel.
Select Policy¶
DI-engine covers most of the reinforcement learning policies, using them only requires selecting the right policy and model. Since DQN is off-policy, we also need to instantiate a buffer module.
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.data import DequeBuffer
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
Build the Pipeline¶
With the various middleware provided by DI-engine, we can easily build the entire pipeline:
from ding.framework import task
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, eps_greedy_handler, CkptSaver
with task.start(async_mode=False, ctx=OnlineRLContext()):
# Evaluating, we place it on the first place to get the score of the random model as a benchmark value
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg)) # Decay probability of explore-exploit
task.use(StepCollector(cfg, policy.collect_mode, collector_env)) # Collect environmental data
task.use(data_pusher(cfg, buffer_)) # Push data to buffer
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_)) # Train the model
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100)) # Save the model
# In the evaluation process, if the model is found to have exceeded the convergence value, it will end early here
task.run()
Run the Code¶
The full example can be found in DQN example and can be run via python dqn.py.
In addition, we also provide the Colab Running Example from the DI-engine installation to training for reference.
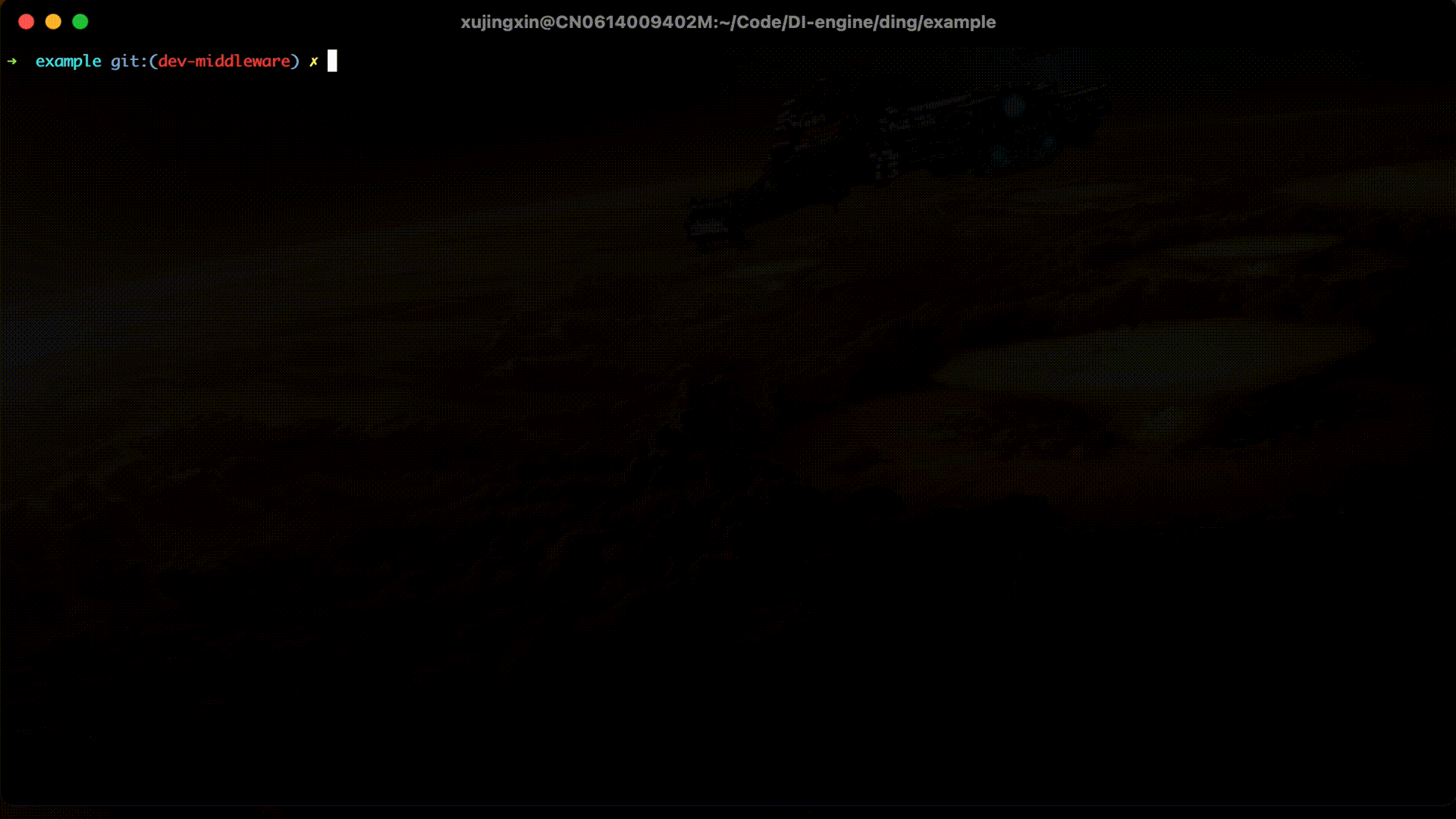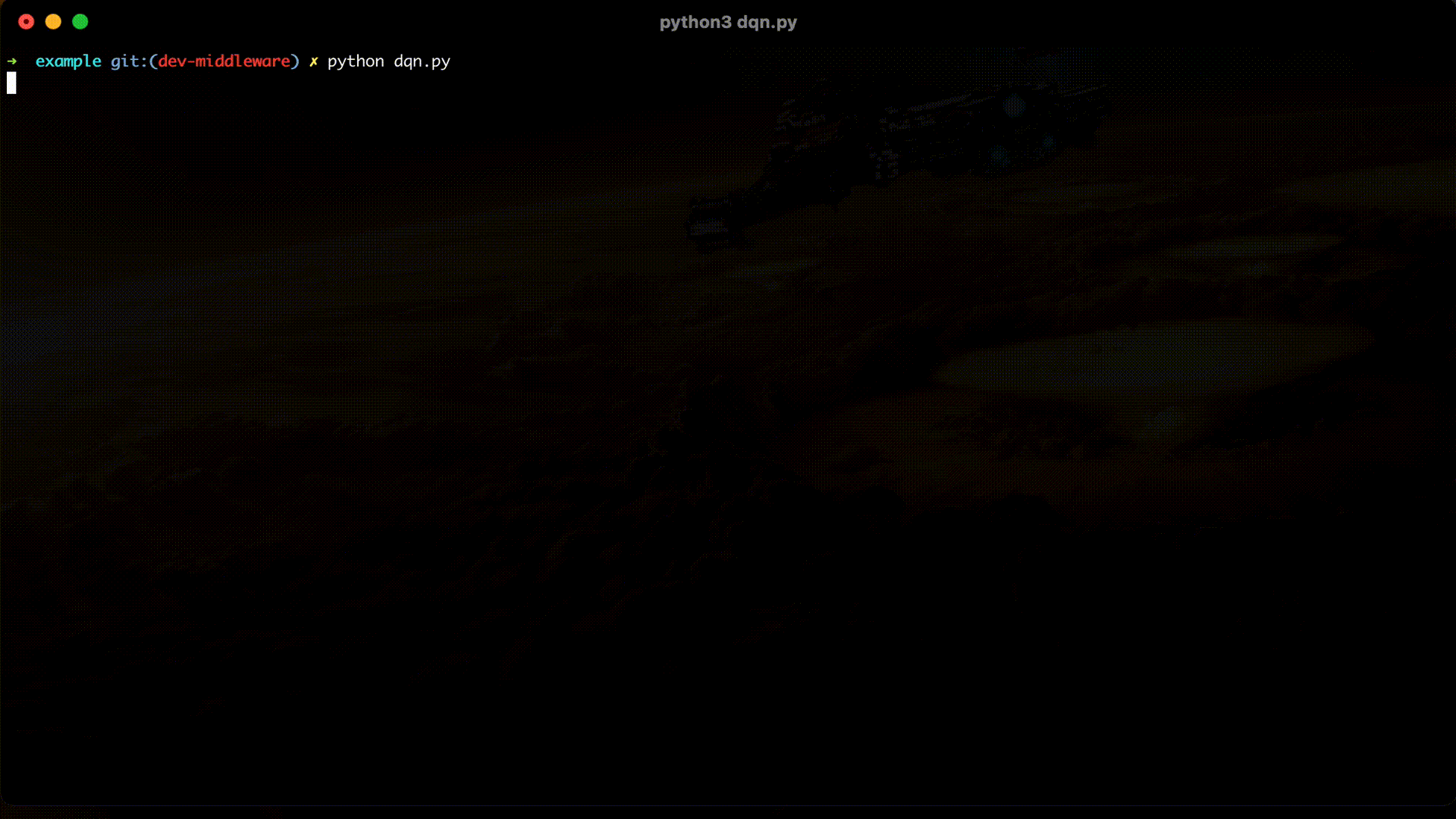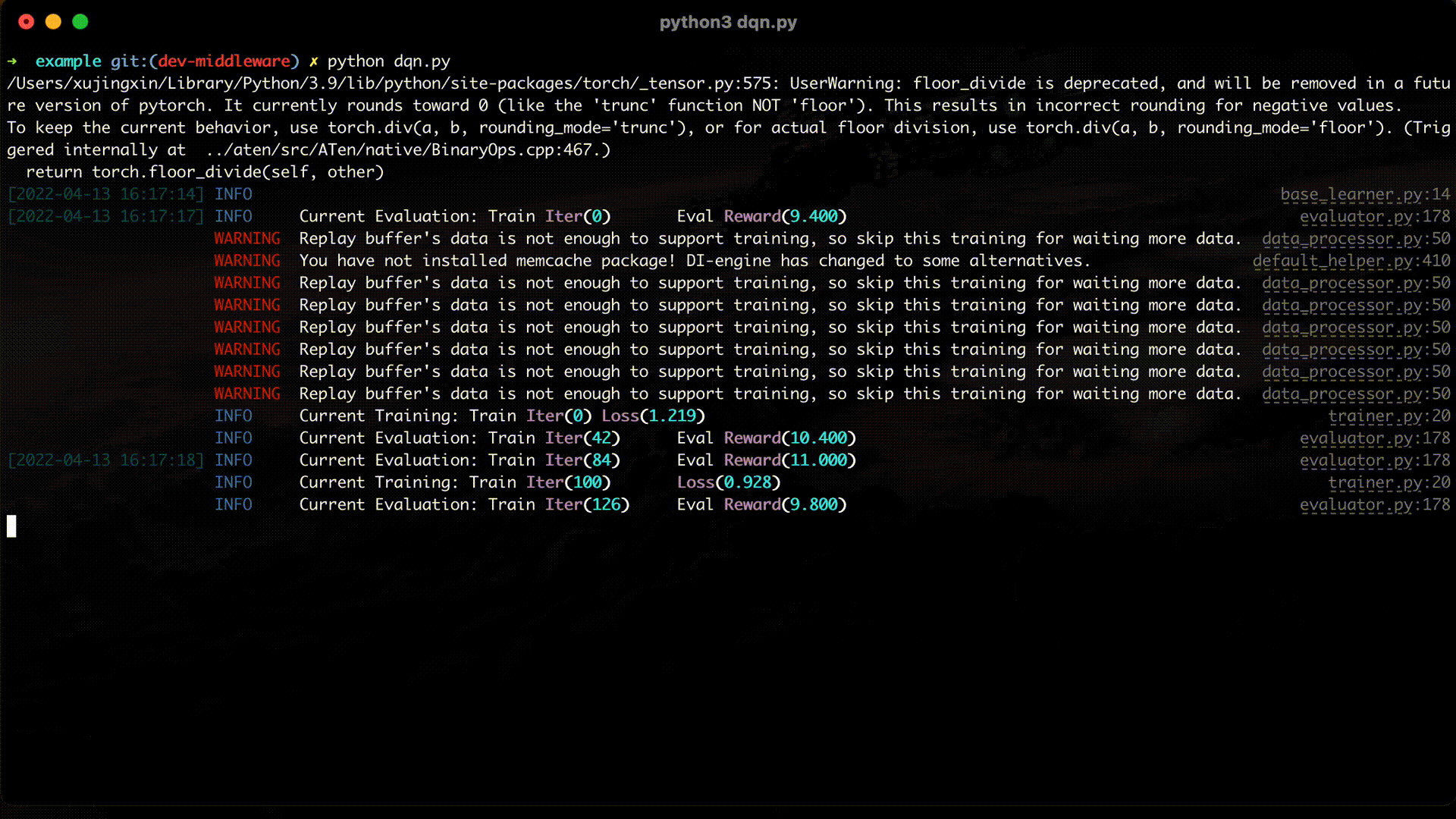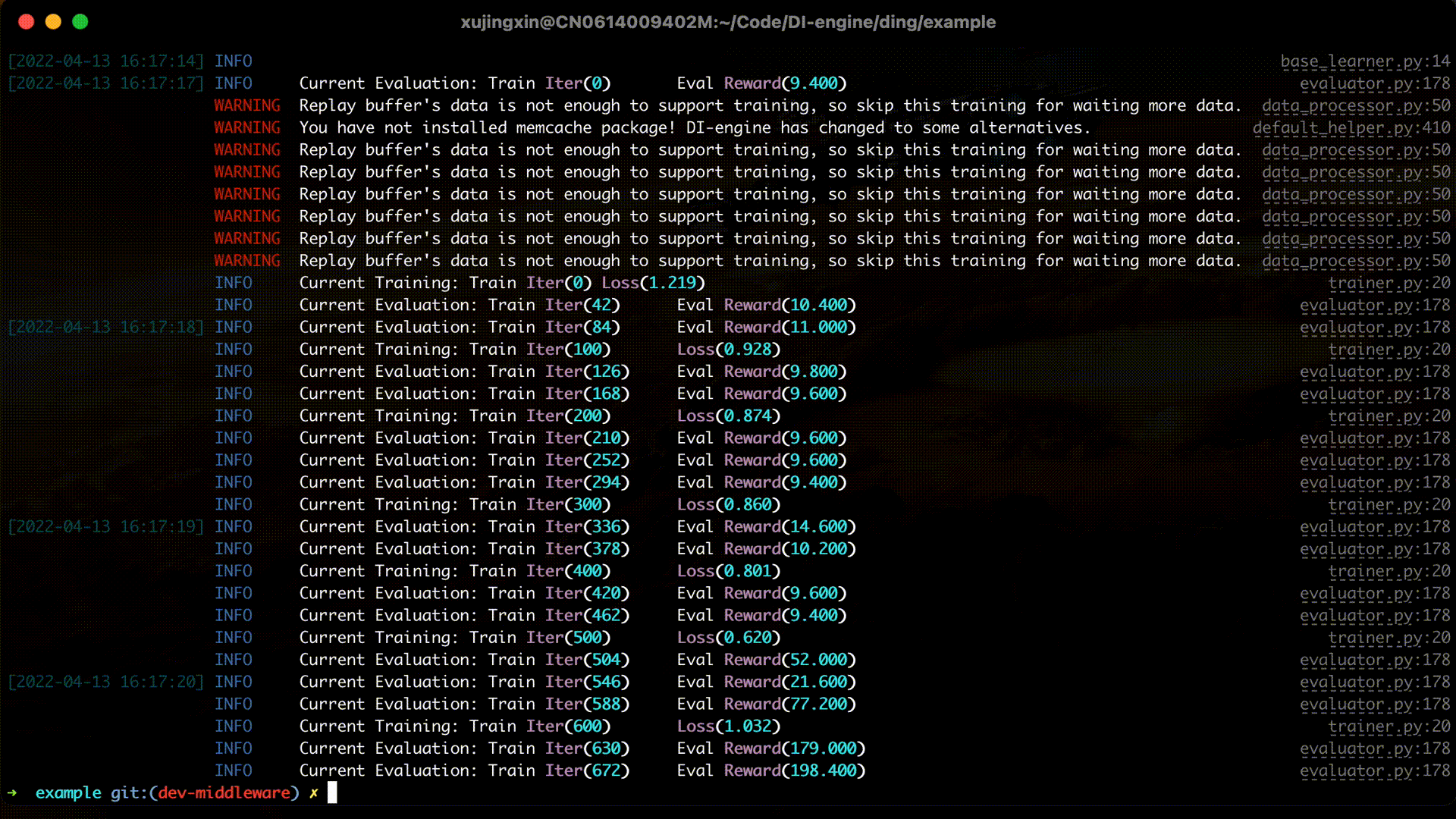
Now you have completed your first reinforcement learning task with DI-engine, you can try out more algorithms in the Examples directory, or continue reading the documentation to get a deeper understanding of DI-engine’s Algorithm, System Design and Best Practices.