Hello World for DI¶
Decision intelligence is the most important direction in the field of artificial intelligence. Its general form is to use an agent to process information from an environment, give reasonable feedback and responses, and make the state of the environment changing as designer’s expectations. For example, a autodrive car will receive information about road conditions from the environment, and give real-time autonomous driving decisions, and let the vehicle drive to the set destination.
We first use the “lunarlander” environment to introduce the agent in the DI-engine and how it interacts with the environment. In this simulated environment, the agent needs to land the lunarlander safely and smoothly to the designated area and avoid crashing.

Let the Agent Run¶
An agent is an object that can interact with the environment freely, and is essentially a mathematical model that accepts input and feeds back output. Its model consists of a model structure and a set of model parameters. In general, we will write the model into a file for saving, or read the model from that file for deploying. Here we provide an agent model trained by the DI-engine framework using the DQN algorithm: final.pth.tar Just use the following code to make the agent run, remember to replace the model address in the function (“ckpt_path=’./final.pth.tar’”), with the locally saved model file path, such as “’~/Download/final.pth.tar’”:
import gym # Load the gym library, which is used to standardize the reinforcement learning environment
import torch # Load the PyTorch library for loading the Tensor model and defining the computing network
from easydict import EasyDict # Load EasyDict for instantiating configuration files
from ding.config import compile_config # Load configuration related components in DI-engine config module
from ding.envs import DingEnvWrapper # Load environment related components in DI-engine env module
from ding.policy import DQNPolicy, single_env_forward_wrapper # Load policy-related components in DI-engine policy module
from ding.model import DQN # Load model related components in DI-engine model module
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config # Load DI-zoo lunarlander environment and DQN algorithm related configurations
def main(main_config: EasyDict, create_config: EasyDict, ckpt_path: str):
main_config.exp_name = 'lunarlander_dqn_deploy' # Set the name of the experiment to be run in this deployment, which is the name of the project folder to be created
cfg = compile_config(main_config, create_cfg=create_config, auto=True) # Compile and generate all configurations
env = DingEnvWrapper(gym.make(cfg.env.env_id), EasyDict(env_wrapper='default')) # Add the DI-engine environment decorator upon the gym's environment instance
env.enable_save_replay(replay_path='./lunarlander_dqn_deploy/video') # Enable the video recording of the environment and set the video saving folder
model = DQN(**cfg.policy.model) # Import model configuration, instantiate DQN model
state_dict = torch.load(ckpt_path, map_location='cpu') # Load model parameters from file
model.load_state_dict(state_dict['model']) # Load model parameters into the model
policy = DQNPolicy(cfg.policy, model=model).eval_mode # Import policy configuration, import model, instantiate DQN policy, and turn to evaluation mode
forward_fn = single_env_forward_wrapper(policy.forward) # Use the strategy decorator of the simple environment to decorate the decision method of the DQN strategy
obs = env.reset() # Reset the initialization environment to get the initial observations
returns = 0. # Initialize total reward
while True: # Let the agent's strategy and environment interact cyclically until the end
action = forward_fn(obs) # According to the observed state, make a decision and generate action
obs, rew, done, info = env.step(action) # Execute actions, interact with the environment, get the next observation state, the reward of this interaction, the signal of whether to end, and other information
returns += rew # Cumulative reward return
if done:
break
print(f'Deploy is finished, final epsiode return is: {returns}')
if __name__ == "__main__":
main(main_config=main_config, create_config=create_config, ckpt_path='./final.pth.tar')
As shown in the codes, the PyTorch object parameters of the model can be obtained by using torch.load. And then the model parameters can be loaded into the DQN model of DI-engine using load_state_dict to make the model rebuilt. Then load the DQN model into the DQN policy, and use the forward_fn function of the evaluation mode to make the agent generate feedback action for the environmental state, obs. The action of the agent will interact with the environment once to generate the environment state, obs, at the next moment, the reward, rew, of this interaction, the signal, done, of whether the environment is over, and other information, info.
Note
The environment state is generally a set of vectors or tensors. The reward is generally a real value. The signal whether the environment has ended is a boolean variable, yes or no. Other information is an additional message that the creator of the environment wants to pass, in any format.
The reward value at all times will be accumulated as the total score of the agent in this task.
Note
You can see the total score of the deployed agent in the log, and you can see the replay video in the experiment folder.
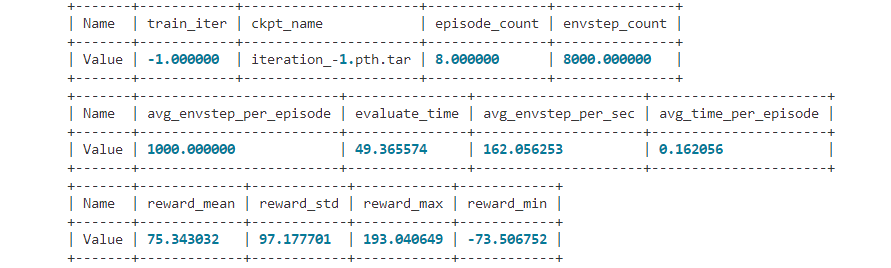
To Better Evaluate Agents¶
In various contexts of reinforcement learning, the initial states of the agents are not always exactly the same. The performance of the agent may fluctuate with different initial states. For example, in the environment of “lunarlander”, the lunar surface is different every time.
Therefore, we need to set up multiple environments and run several more evaluation tests to better score it. DI-engine designed the environment manager env_manager to do this, we can do this with the following slightly more complex code:
import os
import gym
import torch
from tensorboardX import SummaryWriter
from easydict import EasyDict
from ding.config import compile_config
from ding.worker import BaseLearner, SampleSerialCollector, InteractionSerialEvaluator, AdvancedReplayBuffer
from ding.envs import BaseEnvManager, DingEnvWrapper
from ding.policy import DQNPolicy
from ding.model import DQN
from ding.utils import set_pkg_seed
from ding.rl_utils import get_epsilon_greedy_fn
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
# Get DI-engine form env class
def wrapped_cartpole_env():
return DingEnvWrapper(
gym.make(main_config['env']['env_id']),
EasyDict(env_wrapper='default'),
)
def main(cfg, seed=0):
cfg['exp_name'] = 'lunarlander_dqn_eval'
cfg = compile_config(
cfg,
BaseEnvManager,
DQNPolicy,
BaseLearner,
SampleSerialCollector,
InteractionSerialEvaluator,
AdvancedReplayBuffer,
save_cfg=True
)
cfg.policy.load_path = './final.pth.tar'
# build multiple environments and use env_manager to manage them
evaluator_env_num = cfg.env.evaluator_env_num
evaluator_env = BaseEnvManager(env_fn=[wrapped_cartpole_env for _ in range(evaluator_env_num)], cfg=cfg.env.manager)
# switch save replay interface
# evaluator_env.enable_save_replay(cfg.env.replay_path)
evaluator_env.enable_save_replay(replay_path='./lunarlander_dqn_eval/video')
# Set random seed for all package and instance
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
# Set up RL Policy
model = DQN(**cfg.policy.model)
policy = DQNPolicy(cfg.policy, model=model)
policy.eval_mode.load_state_dict(torch.load(cfg.policy.load_path, map_location='cpu'))
# Evaluate
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
evaluator = InteractionSerialEvaluator(
cfg.policy.eval.evaluator, evaluator_env, policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
evaluator.eval()
if __name__ == "__main__":
main(main_config)
Note
When evaluating multiple environments in parallel, the environment manager of DI-engine will also count the average, maximum and minimum rewards, as well as other indicators related to some algorithms.
Training Stronger Agents from Scratch¶
Run the following code using DI-engine to get the agent model in the above test. Try generating an agent model yourself, maybe it will be stronger:
import gym
from ditk import logging
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.envs import DingEnvWrapper, BaseEnvManagerV2, SubprocessEnvManagerV2
from ding.data import DequeBuffer
from ding.config import compile_config
from ding.framework import task, ding_init
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \
eps_greedy_handler, CkptSaver, online_logger, nstep_reward_enhancer
from ding.utils import set_pkg_seed
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
def main():
logging.getLogger().setLevel(logging.INFO)
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
ding_init(cfg)
with task.start(async_mode=False, ctx=OnlineRLContext()):
collector_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(nstep_reward_enhancer(cfg))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(online_logger(train_show_freq=10))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.run()
if __name__ == "__main__":
main()
Note
The above code takes about 10 minutes to train to the default termination point with an Intel i5-10210U 1.6GHz CPU and no GPU device. If you want the training time to be shorter, try the simpler Cartpole environment.
Note
DI-engine integrates the tensorboard component to record key information during the training process. You can turn it on during training, so you can see real-time updated information, such as the average total reward value recorded by the evaluator, etc.
Well done! So far, you have completed the Hello World task of DI-engine, used the provided code and model, and learned how the reinforcement learning agent interacts with the environment. Please continue to read this document, First Reinforcement Learning Program, to understand how the RL pipeline is built in DI-engine.