Distributed Reinforcement Learning¶
Problem Definition and Research Motivation¶
Distributed reinforcement learning (Distributed RL) is the only way for deep reinforcement learning to be applied to large-scale applications and solve complex decision spaces and long-term planning problems. In order to solve super-large-scale decision-making problems like StarCraft 2 (SC2) [1] and DOTA2 [2], the computing power of a single process or even a single machine is far from enough, and it is necessary to expand each of computing and storage devices. Researchers hope to design a complete set of ‘algorithm + system’ solutions, which can allow the DRL training program to efficiently run under various computing scales and improve the efficiency of each link as much as possible while ensuring the convergence of algorithm optimization.
Generally speaking, a reinforcement learning training program has three types of core modules:
The Environment (Env) to generate data,
The Actor that generates actions,
The Learner for training using these data, each of which requires different number and types of computing resources supported.
P.S. the module including env and actor is usually referred to collector.
Depending on the algorithm and environment, some extended auxiliary modules will be added. For example, most off-policy algorithms will require a data queue (Replay Buffer) to store training data; for model-based RL algorithms, there will be related training modules for learning the dynamics of the environment; for algorithms that require a lot of self-play, a centralized Coordinator is needed to control and coordinate each component(such as dynamically communicating with both sides of the game).
From a system perspective, it is necessary to allow sufficient parallel scalability for similar modules in the entire training program. For example, the number of interacting environments can be increased according to the availability of resources (utilize more CPUs), or the throughput of the training side can be increased according to the number of parallel devices (generally, having more GPUs). For different modules, it is hoped that all modules can be executed asynchronously as much as possible, and the cost of various communication methods (network communication, database, file system) in module time is reduced. But in general, the theoretical upper limit of the efficiency optimization of a system is achieved when the Learner can continuously train efficiently without waiting; that is, when the Learner completes one training iteration efficiently, the data for the next training iteration is already available.
From the algorithmic point of view, it is hoped to reduce the algorithm’s requirements for data throughput (such as tolerating older and more off-policy data) while ensuring the convergence of the algorithm, and improving the efficiency of data exploration and the utilization of collected data (for example, modify the data sampling method, or combine some research related to data-efficiency in RL). So that it provides more space and possibilities for system design.
To sum up, distributed reinforcement learning is a more comprehensive research subfield, which requires mutual perception and coordination of deep reinforcement learning algorithm + distributed system design.
Research Direction¶
System¶
Overall Architecture¶
For common decision problems, the two most commonly used distributed architectures are IMPALA [3] and SEED RL [4].
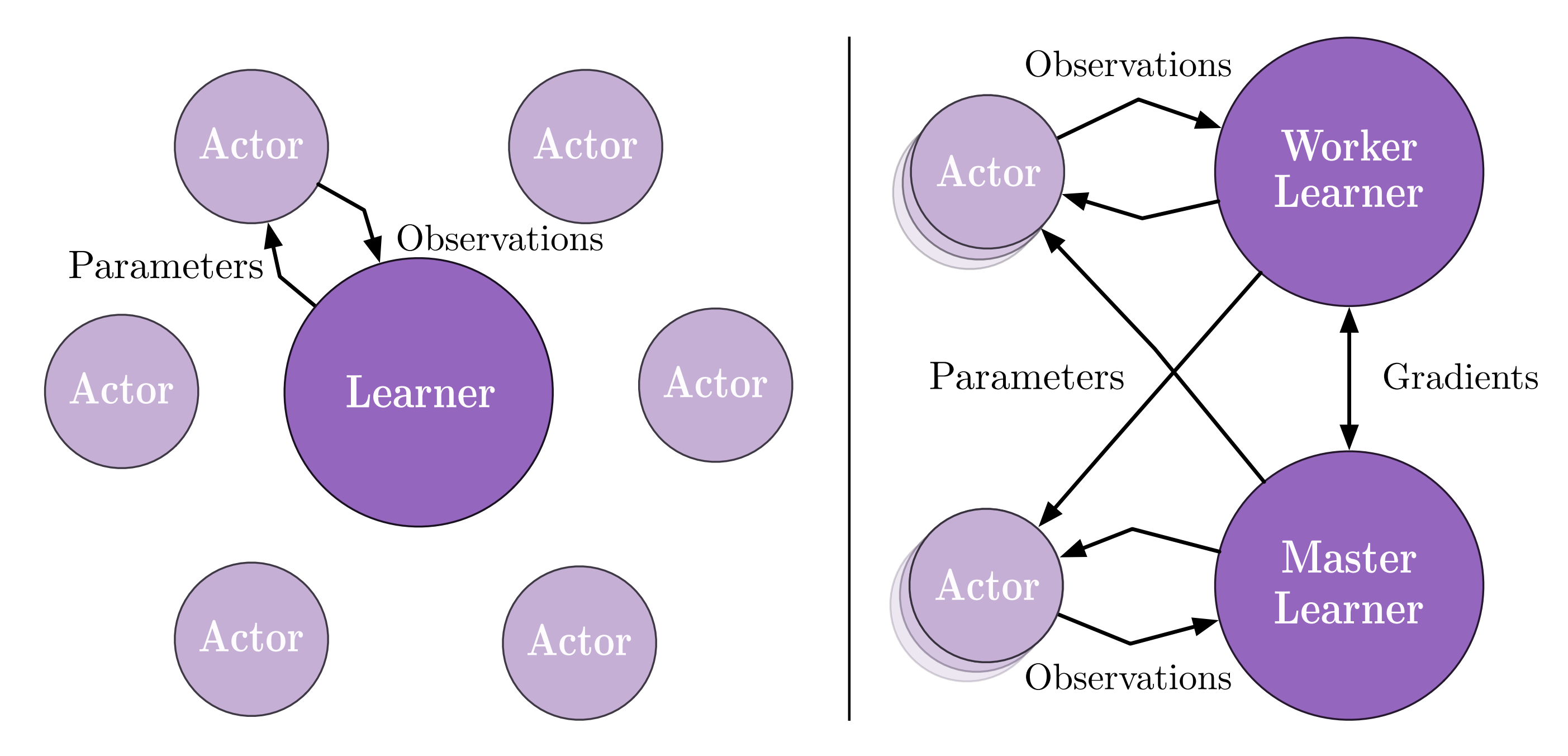
The former is the classic Actor-Learner mode; that is, the data collection and training sides are entirely separated, and the latest neural network model is regularly passed from the Learner to the Actor, and the data collected by the Actor are sent to the Learner after collecting a certain amount of dataframes (i.e. observations). If there are multiple Learners, they also periodically synchronize their gradients to update the neural network (i.e. the data-parallel model in distributed deep learning).
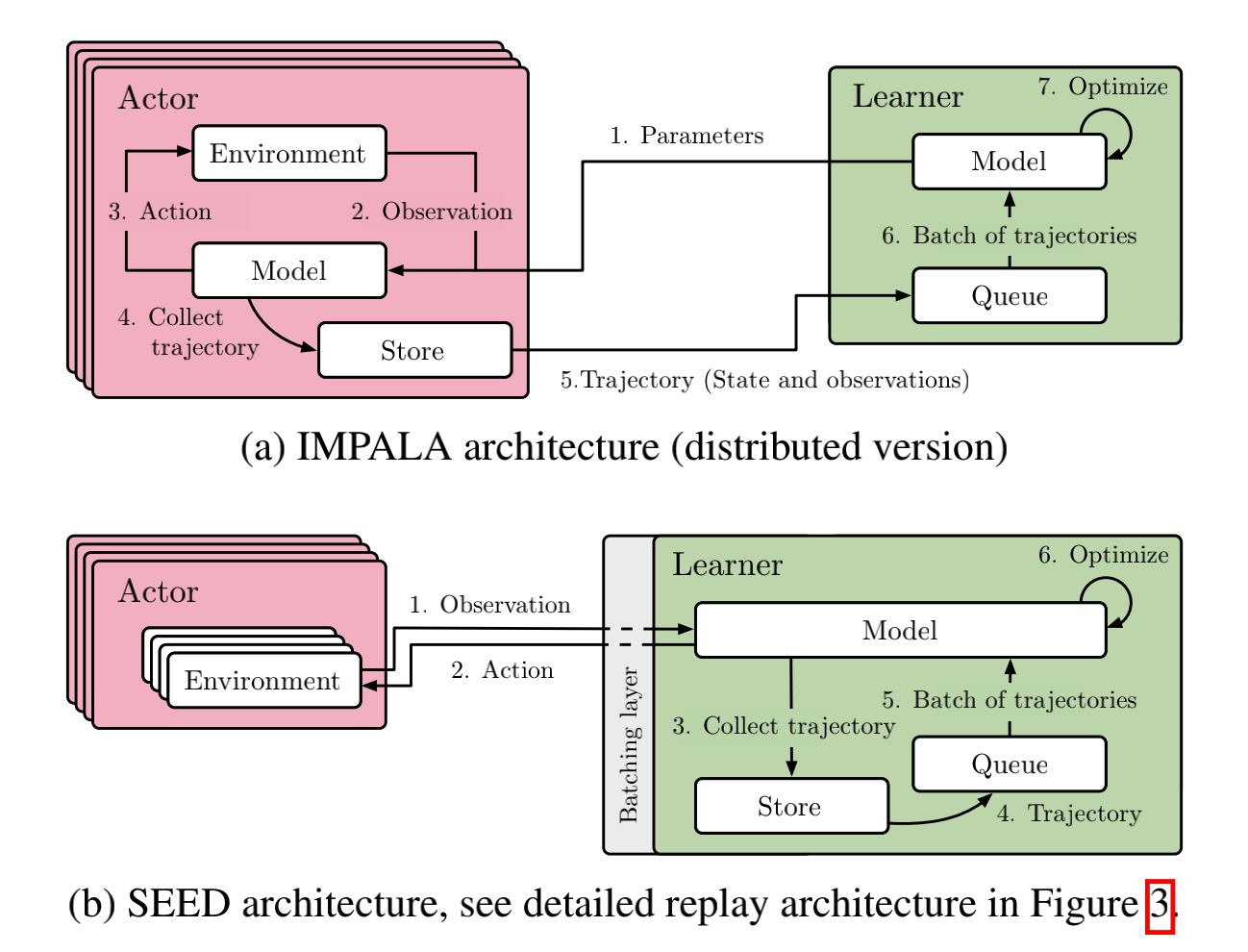
On the basis of the former, the latter is dedicated to optimizing the loss of the transmission model parameters. SEED RL strips out the part used for inference to generate actions, and puts it together with the training end to update the model parameters through efficient inter-TPU communication technology. The cost of passing the model parameters in IMPALA is greatly reduced, and for cross-machine communication between the environment and the inference Actor, SEED RL uses an optimized gRPC scheme to pass the observation and action, so there is not much burden.
Note
There is no absolute superiority or inferiority between these two schemes. If it is more expensive to transmit models across machines and there are better communication components between GPU/TPU, then SEED RL could be a more suitable option. Otherwise, if it is more expensive to transmit observations and actions data across machines, then IMPALA is a more stable choice. In addition, IMPALA can accumulate a batch of data for data transmission, while SEED RL requires data transmission in each interactive frame. This is a classic data batch and stream processing comparison problem. For the current machine learning community, the former is generally more user-friendly. Also, if the entire training procedure requires a higher degree of freedom and customization, such as dynamically controlling some behavior of the Actor, IMPALA is more convenient.
In addition to the above two architectures, there are many other distributed reinforcement learning design schemes, such as A3C [5] and Gossip A2C [6] that introduce asynchronous neural network update schemes. In order to support large-scale self-play, AlphaStar [1] with a complex League mechanism was designed, and MuZero [7] combined with model-based RL and MCTS-related modules will not be described here. Interested readers can refer to the specific Papers or refer to our Algorithm Raiders Collection section.
Efficiency Optimization on Some Sub Topics/Modules/Objectives¶
In addition to the design and innovation of the overall structure, there are many methods for optimizing a single-point module in the entire training program. They are mainly customized and optimized for a certain sub-problem. Here are some of the main methods:
Object Storein Ray/RLLib [8]: For data transfer between multiple processes and multiple machines, the Object Store in Ray/RLLib provides a very convenient and efficient way. As long as any process knows the reference of an object, it can request the Store to provide it. Providing the corresponding value, and the specific internal data transmission is completely managed by the Store, so that a distributed training program can be implemented like writing a local single-process program. The specific implementation of Object Store is completed by combining redis, plasma and gRPC.Sample Factory[9]: Sample Factory customized and optimized the APPO algorithm at the scale of a single machine, carefully designed an asynchronous scheme between the environment and the action-generating strategy, and used shared memory to greatly improve the transmission efficiency between modules.Reverbin Acme [10]: Reverb provides a set of highly flexible and efficient data manipulation and management modules. For RL, it is very suitable for implementing replay buffer related components.envpool[11]: envpool is currently the fastest environment vectorized parallel solution, using c++ threadpool and efficient implementation of many classic RL environments to provide powerful asynchronous vectorized environment simulation capabilities.
Algorithm¶
Reduce the throughput requirements of the algorithm for data generation¶
V-tracein IMPALA [3]: The off-policy algorithm can widen the range of data available for training, thereby improving the algorithm’s tolerance for old data to a certain extent and reducing the throughput pressure of the data generated by the Collector, but the data that is too off-policy can easily affect the convergence of the algorithm. Aiming at this problem, IMPALA uses the importance sampling mechanism and the corresponding clipping method to design a relatively stable algorithm scheme V-trace under the distributed training setting, which limits the negative impact of off-policy data on the optimization itself.ReuseandStalenessin OpenAI FIVE [2]: In the agent designed by OpenAI for DOTA2, they conducted some experiments on the number of data reuse and the degree of staleness. Excessive number of reuse and too old data will affect the stability of the PPO algorithm in large-scale training.
Improve data exploration efficiency + utilization efficiency of collected data¶
Data Priority and Diversity——Ape-x [12]: Ape-x is a classic distributed reinforcement learning scheme. One of the core practices is to use Priority Experience Replay to set sample different data with priority preference, so that the algorithm pays more attention to those “important” trajctories. In addition, Ape-x also sets different exploration parameters (i.e. epsilon of eps greedy) in different parallel collectors to improve data diversity.Representation Learningin RL——CURL [13]: For some high-dimensional or multi-modal inputs, the representation learning method can be combined to improve the data utilization efficiency of RL. For example, for the control problem of high-dimensional image input, CURL introduces an additional contrastive learning process, and RL is based on the learned feature space for decision-making. From the perspective of system design, there is also a lot of room for optimization in the combination of representation learning and reinforcement learning training, such as the asynchrony of the two.Model-based/MCTS RL——MuZero [7]: MuZero combines model-based RL and MCTS RL to improve the overall training efficiency, which includes many unique modules, such as the search process of MCTS, the reanalyze process of data before training, etc., which will lead to more complicated and diverse distributed reinforcement learning training systems.
Future Study¶
At present, distributed reinforcement learning is only an emerging research subfield. In many cases, it is limited by computing power and problem complexity. There are still many problems that need to be solved:
Lack of a unified benchmark to evaluate the efficiency of distributed reinforcement learning algorithms and systems;
At present, most distributed reinforcement learning solutions are only suitable for a small part of the environment and part of the RL algorithm, and there is still a long way to go before the generalization of the technology;
Current system optimization and RL algorithms themselves are still isolated, and system designs that percept RL optimization needs can be considered, such as dynamic resource perception and scheduling.