Zero-sum Game¶
Problem Definition and Research Motivation¶
Zero-sum game, is a classic concept in game theory, meaning a game in which the sum of the benefits of all parties to the game is zero.Zero-sum game can be classified into two-player zero-sum game and multi-player zero-sum game according to the number of participants.
The classic two-player zero-sum game scenario such as rock-paper-scissors, in which one side wins and the other side loses, means that when one side gains, it inevitably brings an equal amount of loss to the other side.
In the study of two-player zero-sum games, it is generally agreed that the difficulty lies in finding the solution to this problem, that is, the Nash Equilibrium Solution.
Research History¶
As scholars deepen their research on the direction of zero-sum games, there are mainly the following development stages:
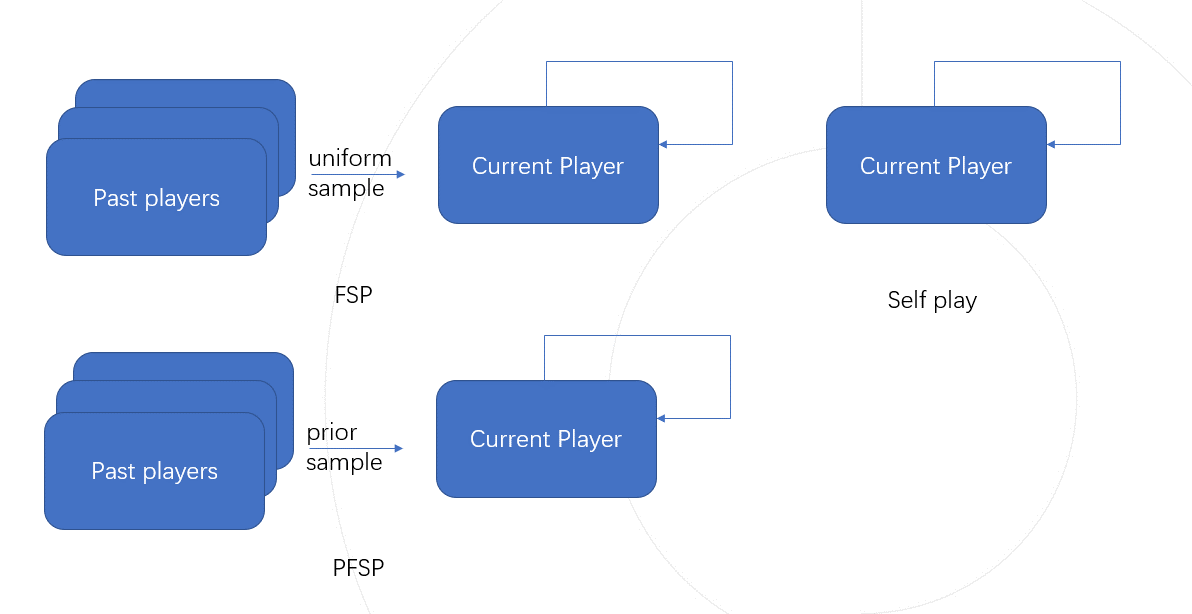
1. Self-Play, SP
Self-Play refers to training against itself and is often used to solve board games and to establish benchmarks for games in general. AlphaZero and OpenAI Five have reached a level beyond humans by simply self-gaming without using any human data. Although Self-Play can achieve performance beyond the human level in many game types, it also has shortcomings. For example, assuming that the human strategy in the rock-paper-scissors setting is to play only scissors, the Self-Play model will loop back and forth infinitely in a sequence similar to rock-paper-scissors as a strategy.
2. Fictious Self-Play, FSP [[1]]
In order to solve the Self-Play limitation problem, FSP introduces the past versions of the training intelligences into the training, and based on the Self-Play, the past versions of the intelligences are also randomly selected with the same probability against each other, and this training method is called virtual self-play. Because of the diversity of the opponent pool, the FSP converges to a uniformly random rock-paper-scissors hybrid strategy regardless of our initial strategy, which is also the Nash equilibrium solution to this problem.
3. Prioritised Fictious Self-Play, PFSP [[2]]
PFSP( Prioritised Fictious Self-Play) is based on the FSP, which allocates opponents according to the matchmaking rate between the training and historical intelligences, and increases the frequency of the training intelligences against historical intelligences with low matchmaking rates to achieve faster convergence, a training method known as preferential virtual self-gaming. StarCraft 2’s AI AlphaStar [[3]] uses PFSP to assist in training.
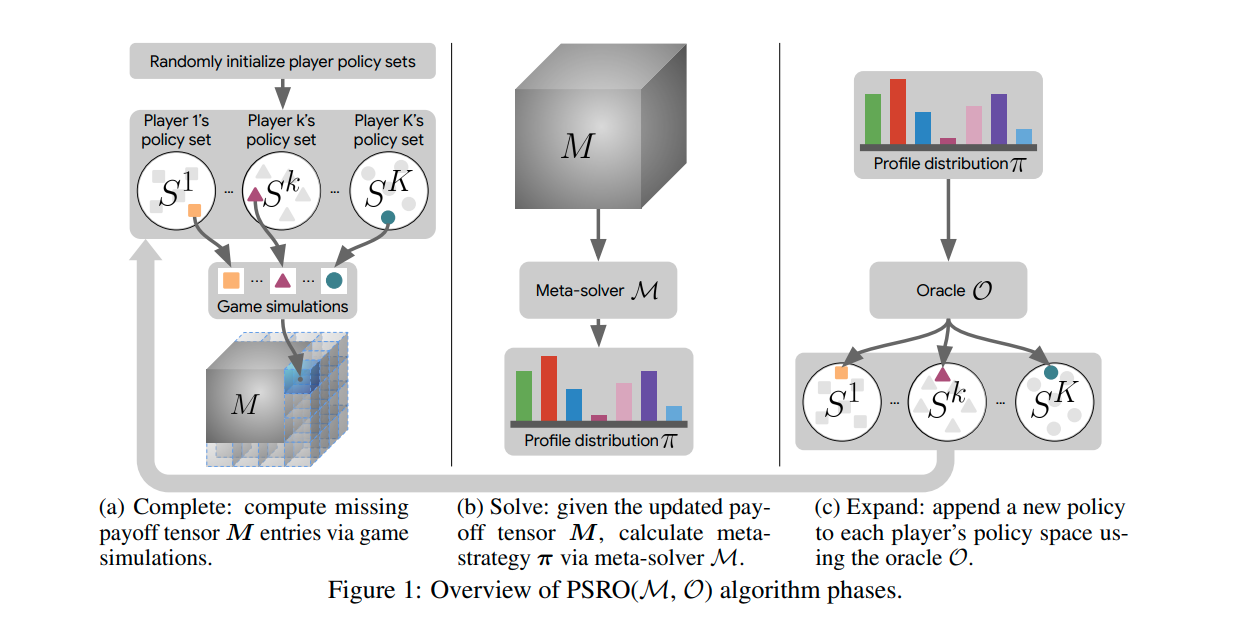
Future Prospect¶
How to design more efficient matching strategies to get stronger intelligences with fewer training resources.
The respective designs are available in a large number of engineering projects ( ALphaStar, TstarBot [[4]] ), but are often empirical (relying on subjective human judgment) and rarely argued theoretically as to why they are efficient.
How to consider multiplayer zero-sum games and even more general multiplayer games.
A solution framework for multiplayer games is presented in Policy-Space Response Oracles [[5]].
In Alpha-Rank [[6]], an alternative solution to the Nash equilibrium is considered.