Agent¶
关于 RL Agent¶
DI-engine 的 RL Agent 类,顾名思义,是用于RL训练或评估过程中与环境进行直接交互的智能体。
初始化后,每个 RL Agent 都会维护一个环境实例,一个策略实例,及其对应的相关配置。
DI-engine 的每个强化学习算法将会被实现为特定类型的 RL Agent 类。每个类都配备了标准的训练与评估方法,以确保同一种算法在不同环境下都有相同的标准训练与评估流程。
RL Agent 类支持包括 Gym Atari 和 MuJoCo 在内的一系列经典强化学习基准环境,确保了类对于这些多样环境的兼容性。
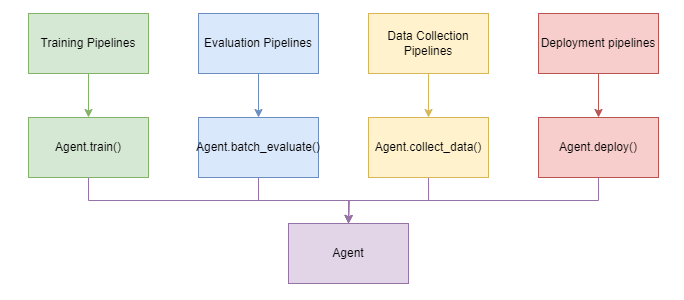
RL Agent类为RL的各类训练、评估管线提供了有效的抽象。
它包括四个主要方法:”train”、”deploy”、”batch_evaluate”和”collect_data”。这让四种不同的 DI-engine 管线合并为一个包含四个方法的类。这避免了之前需要在不同的文件中编写个别流水线代码的需求。
比如,当不熟悉强化学习流程或不熟悉 DI-engine 代码的用户需要训练某种游戏环境的PPO算法,并部署训练过的模型以进行视频重放绘制时,需要将训练和部署管线合并起来一起运行,或使用模型文件作为中间媒介来分开运行。这种代码使用上的不一致和混乱,会引发很多的问题,比如造成框架学习成本过高,或容易导致参数设置错误。
通过 RL Agent 类,现在有了一个标准的实现来管理所有的训练、评估管线,并允许用户按任意顺序连接训练和评估过程,或者让训练和评估过程轻松地由第三方库调用和激活。
RL Agent 的使用¶
RL Agent 类为经典强化学习基准环境提供了默认配置。这些默认配置经过广泛测试,训练表现稳定可靠,使得新用户不需要任何经验知识的支持,就能启动训练过程。
from ding.bonus import DQNAgent
if __name__ == "__main__":
# 智能体初始化
agent = DQNAgent(env_id="LunarLander-v2", exp_name="LunarLander-v2-DQN")
# 智能体训练
return_ = agent.train(step=int(2000000))
# 部署智能体并绘制视频
agent.deploy(enable_save_replay=True)
RL Agent 类同时也支持用户使用自定义的配置训练智能体。配置的格式可以参照默认配置,比如使用 DQN 算法训练 LunarLander 环境,可以参照文件`gym_lunarlander_v2.py <https://github.com/opendilab/DI-engine/blob/main/ding/config/example/DQN/gym_lunarlander_v2.py>`.
from ding.bonus import DQNAgent
from ding.config.example.DQN.gym_lunarlander_v2 import cfg
if __name__ == "__main__":
# 智能体初始化
agent = DQNAgent(exp_name="LunarLander-v2-DQN", cfg=cfg)
# 智能体训练
return_ = agent.train(step=int(2000000))
# 部署智能体并绘制视频
agent.deploy(enable_save_replay=True)
RL Agent 类整合了训练和评估管线,使得用户可以在同一个主文件中调用训练和评估方法,而无需使用多个文件来分别执行训练和评估。这样,用户就可以在训练过程中随时评估智能体的性能,或者在评估过程中随时训练智能体。
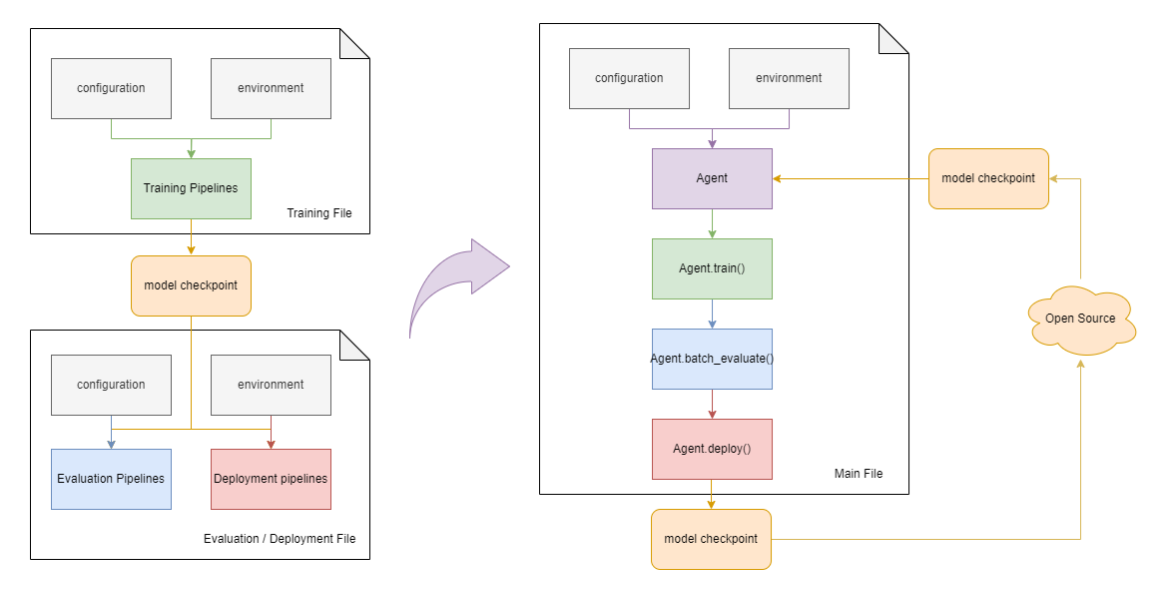
此外,训练好后的模型文件可以在 Hugging Face Hub 上获得。为了下载这些模型,请您按照网页上提供的指示进行操作。 (以`LunarLander-v2-DQN <https://huggingface.co/OpenDILabCommunity/LunarLander-v2-DQN>`_模型为例,关于如何下载和部署模型,请点击链接。)