Loading Pre-trained Models and Resuming Training¶
In reinforcement learning experiments using DI-engine, loading a pre-trained ckpt file to resume training from a checkpoint is a common requirement. This article provides a detailed explanation of how to load a pre-trained model and resume training seamlessly using DI-engine, with cartpole_ppo_config.py as an example.
Loading a Pre-trained Model¶
Configure load_ckpt_before_run¶
To load a pre-trained model, you first need to specify the path to the pre-trained ckpt file in the configuration file. This path is configured using the load_ckpt_before_run field.
Example code:
from easydict import EasyDict
cartpole_ppo_config = dict(
exp_name='cartpole_ppo_seed0',
env=dict(
collector_env_num=8,
evaluator_env_num=5,
n_evaluator_episode=5,
stop_value=195,
),
policy=dict(
cuda=False,
action_space='discrete',
model=dict(
obs_shape=4,
action_shape=2,
action_space='discrete',
encoder_hidden_size_list=[64, 64, 128],
critic_head_hidden_size=128,
actor_head_hidden_size=128,
),
learn=dict(
epoch_per_collect=2,
batch_size=64,
learning_rate=0.001,
value_weight=0.5,
entropy_weight=0.01,
clip_ratio=0.2,
# ======== Path to the pretrained checkpoint (ckpt) ========
learner=dict(hook=dict(load_ckpt_before_run='/path/to/your/ckpt/iteration_100.pth.tar')),
resume_training=False,
),
collect=dict(
n_sample=256,
unroll_len=1,
discount_factor=0.9,
gae_lambda=0.95,
),
eval=dict(evaluator=dict(eval_freq=100, ), ),
),
)
cartpole_ppo_config = EasyDict(cartpole_ppo_config)
main_config = cartpole_ppo_config
In the above example, load_ckpt_before_run explicitly specifies the path to the pre-trained model /path/to/your/ckpt/iteration_100.pth.tar. When you run this code, DI-engine will automatically load the model weights from this path and continue training from there.
Model Loading Process¶
The model loading process mainly occurs in the main files under the entry path. Below, we take the serial_entry_onpolicy.py file as an example to explain the process.
The key operation of loading a pre-trained model is achieved through the DI-engine’s hook mechanism:
# Learner's before_run hook.
learner.call_hook('before_run')
if cfg.policy.learn.get('resume_training', False):
collector.envstep = learner.collector_envstep
When load_ckpt_before_run is not empty, DI-engine will automatically call the learner’s before_run hook function to load the pre-trained model from the specified path. The specific implementation can be found in DI-engine’s learner_hook.py.
The checkpoint saving and loading functionalities for the policy itself are implemented through the _load_state_dict_learn and _state_dict_learn methods. For example, in the PPO policy, the implementations can be found at the following locations:
Resuming Training from a Checkpoint¶
Managing Logs and TensorBoard Paths When Resuming¶
By default, DI-engine creates a new log path for each experiment to avoid overwriting previous training data and TensorBoard logs. However, if you want the logs and TensorBoard data to be saved in the same directory when resuming training, you can configure this by setting resume_training=True in the configuration file (its default value is False).
Example code:
learn=dict(
... # Other parts of the code
learner=dict(hook=dict(load_ckpt_before_run='/path/to/your/ckpt/iteration_100.pth.tar')),
resume_training=True,
)
When resume_training=True, DI-engine will save the new logs and TensorBoard data in the original path.
The key code:
# Note that the default value of renew_dir is True. When resume_training=True, renew_dir is set to False to ensure the consistency of log paths.
cfg = compile_config(cfg, seed=seed, env=env_fn, auto=True, create_cfg=create_cfg, save_cfg=True, renew_dir=not cfg.policy.learn.get('resume_training', False))
At the same time, the train_iter and collector.envstep from the loaded ckpt file will be restored, allowing training to seamlessly continue from the previous checkpoint.
Restoring Iteration/Step Count When Resuming¶
When resuming training from a checkpoint, both the training iter and steps will be restored from the last saved iteration and step count in the checkpoint. This ensures that the training process continues from the correct point, maintaining the integrity of the training progress.
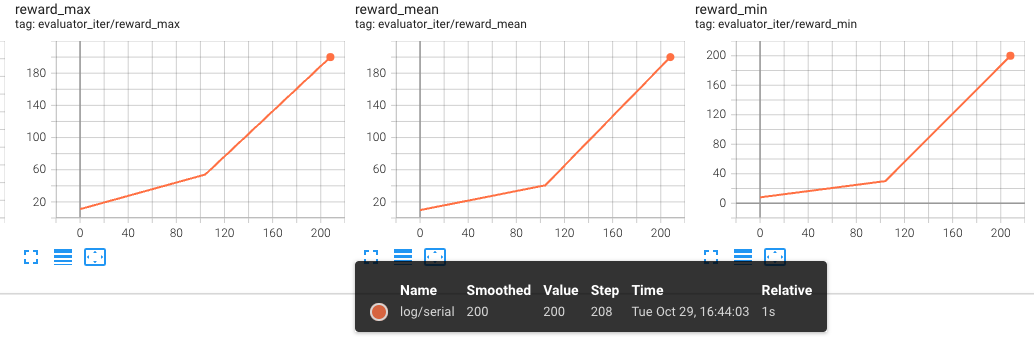
First Training (Pre-train) Results:
The following figures show the evaluator results for the first training (pre-train), with iter and steps on the x-axis, respectively:

Second Training (Resume) Results:
The following figures show the evaluator results for the second training (resume), with iter and steps on the x-axis, respectively:
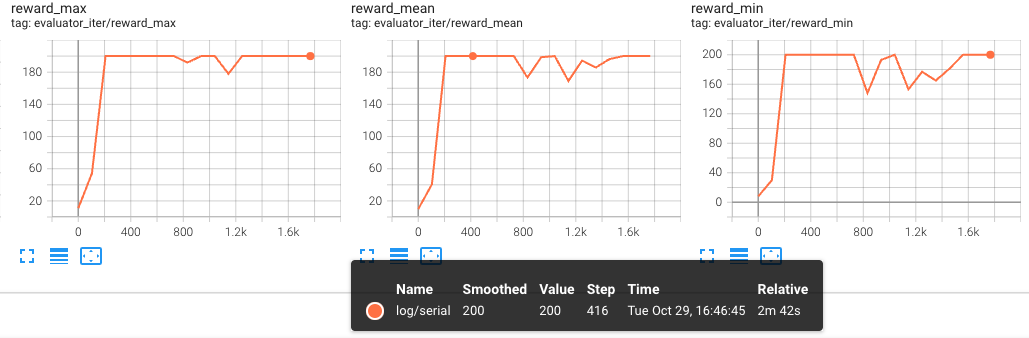
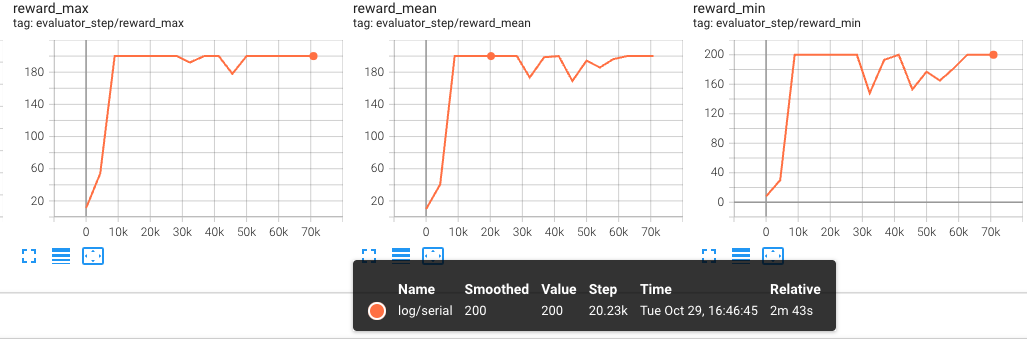
These graphs clearly demonstrate that training continues from where it left off after resuming, and the evaluation metrics show consistency at the same iterations/steps.
Conclusion¶
When conducting reinforcement learning experiments with DI-engine, loading pre-trained models and resuming training from checkpoints is crucial for ensuring stable, long-term training. From the examples and explanations provided in this article, we can observe the following:
Loading a pre-trained model is configured through the
load_ckpt_before_runfield and is automatically loaded before training through thehookmechanism.Resuming training can be achieved by setting
resume_training=True, ensuring seamless log management and training progress continuation.In practical experiments, proper management of log paths and checkpoint data can prevent redundant training and data loss, improving the efficiency and reproducibility of experiments.
We hope this article provides a clear guide for your experiments using DI-engine.