如何使用 RNN¶
RNN简介¶
循环神经网络(RNN)是神经网络中的一类。RNN 是从前馈神经网络中衍生出来的,额外增加了内部状态 (hidden state)来存储历史输入信息,可以处理可变长度的输入序列。其中RNN网络在不同时刻之间的连接关系沿时间维度形成了有向图,这个性质允许它可以捕捉与时间相关的动态行为。从而适用于处理输入为可变长度序列的手写识别或语音识别等任务。
在深度强化学习中, DRQN (Deep Recurrent Q-Learning Network) 算法首先将 RNN 网络应用于RL算法中, 旨在解决atari游戏中不完全信息观测的问题。 之后,RNN 就成为了RL研究中解决复杂时序决策任务的一个重要方法。
经过多年的研究,RNN 有很多变体,如 LSTM、GRU 等。 但是核心的更新过程仍然非常相似。在MDP的每个时间步 \(t\) ,智能体需要用现在的观测状态 \(s_t\) 和历史 的观测状态 \(s_{t-1}, s_{t-2}, ...\) 来推断 \(a_t\)。这 需要 RNN 智能体保存先前的观察结果并保存RNN 隐藏状态。
DI-engine 支持 RNN 网络,并提供易于使用的 API 让用户 实现 RNN 的变体。
DI-engine中的相关组件¶
ding/model/wrapper/model_wrappers.py: HiddenStateWrapper: 用于维护隐藏状态 (hidden state)ding/torch_utils/network/rnn.py: 用于构建RNN模型ding/rl_utils/adder.py: Adder:: 用于将原始数据排列成 时序数据(通过调用 ding/utils/default_helper.py: list_split() 函数)
RNN 在 DI-engine 中的示例¶
policy |
RNN-support |
|---|---|
a2c |
× |
atoc |
× |
c51 |
× |
collaq |
√ |
coma |
√ |
ddpg |
× |
dqn |
× |
il |
× |
impala |
× |
iqn |
× |
ppg |
× |
ppo |
× |
qmix |
√ |
qrdqn |
× |
r2d2 |
√ |
rainbow |
× |
sac |
× |
sqn |
× |
在 DI-engine 中使用 RNN 的过程如下。
构建包含 RNN 的模型
将您的模型包装在策略中
将原始数据按时间顺序排列
初始化隐藏状态(hidden state)
Burn-in(Optional)
构建包含 RNN 的模型¶
您可以使用 DI-engine 的已实现的包含 RNN 的模型或您自己的模型。
使用 DI-engine 已实现的模型。 DI-engine 的 DRQN 对于离散动作空间环境提供 RNN 支持(默认为 LSTM)。你可以在配置中指定模型类型或在策略中设置默认模型以使用 它。
# in config file
policy=dict(
...
model=dict(
type='drqn',
import_names=['ding.model.template.q_learning']
),
...
),
...
# or set policy default model
def default_model(self) -> Tuple[str, List[str]]:
return 'drqn', ['ding.model.template.q_learning']
使用定制模型。 请参考 如何自定义神经网络模型(model). 为了使您的模型以最少的代码更改适应 Di-engine 的入口文件(serial entry),模型的输出 dict 应包含
next_state键。
class your_model(nn.Module):
def forward(x):
# the input data `x` must be a dict, contains the key 'prev_state', the hidden state of last timestep
...
return {
'logit': logit,
'next_state': hidden_state,
...
}
Note
DI-engine 也提供 RNN 模块。您可以通过 from ding.torch_utils import get_lstm 使用 get_lstm() 函数. 该功能允许用户使用由 ding/pytorch/HPC 实现的 LSTM。详情见
ding/torch_utils/network/rnn.py
使用模型 Wrapper 将您的模型包装在策略中¶
由于包含 RNN 的模型需要维护数据的隐藏状态(hidden states),DI-engine 提供 HiddenStateWrapper 来支持这个功能。 用户只需要在
策略的学习/收集/评估的初始化阶段来包装模型。 HiddenStateWrapper 会帮助智能体在模型计算时保留隐藏状态(hidden states),并在下一次模型计算时发送这些隐藏状态(hidden states)。
# In policy
class your_policy(Policy):
def _init_learn(self) -> None:
...
self._learn_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.learn.batch_size)
def _init_collect(self) -> None:
...
self._collect_model = model_wrap(
self._model, wrapper_name='hidden_state', state_num=self._cfg.collect.env_num, save_prev_state=True
)
def _init_eval(self) -> None:
...
self._eval_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.eval.env_num)
Note
在初始化 collect model 时设置 save_prev_state=True 是为了给 learner model 的 RNN 初始化提供 previous hidden state 。
HiddenStateWrapper 的更多细节可以在 model wrapper 中找到,它的工作流程可以表示为下图:
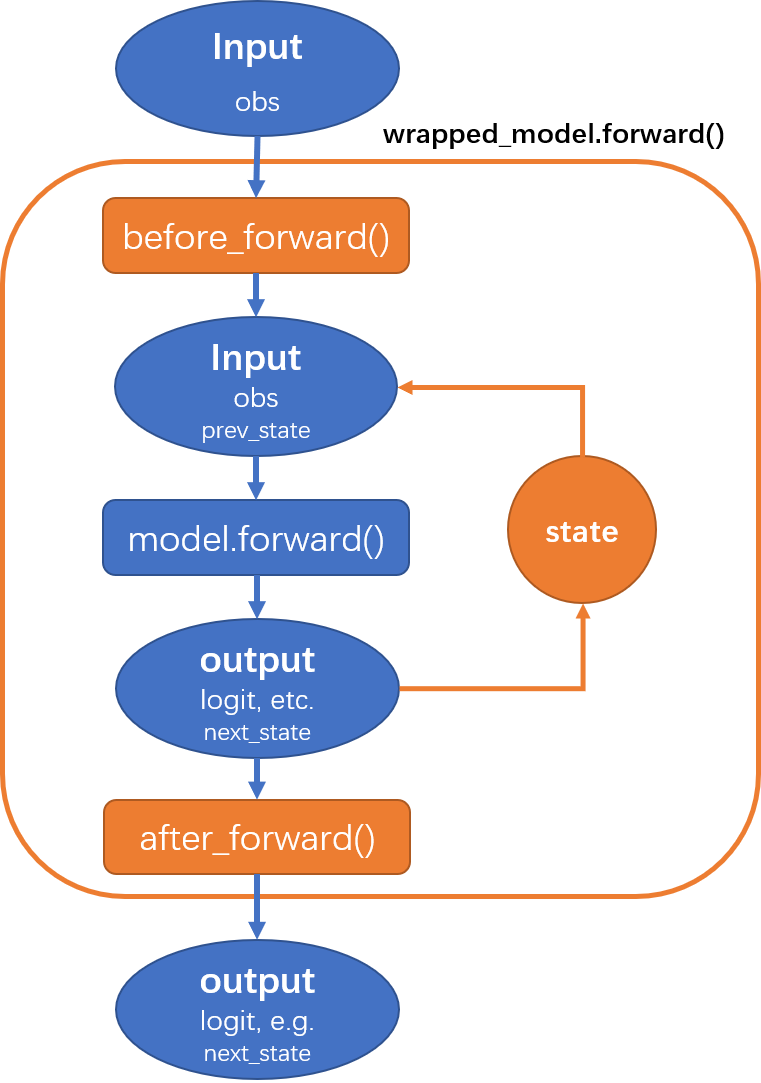
数据处理¶
用于训练 RNN 的 mini-batch 数据不同于通常的数据。 这些数据通常应按时间序列排列。 对于 DI-engine, 这个处理是在
collector 阶段完成的。 用户需要在配置文件中指定 learn_unroll_len 以确保序列数据的长度与算法匹配。 对于大多数情况,
learn_unroll_len 应该等于 RNN 的历史长度(a.k.a 时间序列长度),但在某些情况下并非如此。比如,在 r2d2 中, 我们使用burn-in操作, 序列长度等于
learn_unroll_len + burnin_step 。 这里将在下一节中具体解释。
比如原始采样数据是 \([x_1,x_2,x_3,x_4,x_5,x_6]\),每个
\(x\) 表示 \([s_t,a_t,r_t,d_t,s_{t+1}]\) (或者
\(log_\pi(a_t|s_t)\),隐藏状态等),此时 n_sample = 6 。此时根据所需 RNN
的序列长度即 learn_unroll_len 有以下三种情况:
1.
n_sample>=learn_unroll_len并且n_sample可以被learn_unroll_len除尽: 例如n_sample=6和learn_unroll_len=3,数据将被排列为:math:[[x_1,x_2,x_3],[x_4,x_5,x_6]]。1.
n_sample>=learn_unroll_len并且n_sample不可以被learn_unroll_len除尽: 默认情况下,残差数据将由上一个样本中的一部分数据填充,例如如果n_sample=6和learn_unroll_len=4,数据将被排列为 \([[x_1,x_2,x_3,x_4],[x_3,x_4,x_5,x_6]]\)。1.
n_sample<learn_unroll_len:例如如果n_sample=6和learn_unroll_len=7,默认情况下,算法将使用null_padding方法,数据将被排列为 \([[x_1,x_2,x_3,x_4,x_5,x_6,x_{null}]]\)。 \(x_{null}\) 类似于 \(x_6\) 但它的done=True和reward=0。
这里以r2d2算法为例,在r2d2中,在方法 _get_train_sample 中通过调用函数
get_nstep_return_data 和 get_train_sample 获取按时序排列的数据。
def _get_train_sample(self, data: list) -> Union[None, List[Any]]:
data = get_nstep_return_data(data, self._nstep, gamma=self._gamma)
return get_train_sample(data, self._sequence_len)
有关这两个数据处理功能的更多详细信息,请参见 ding/rl_utilrs/adder.py , 其数据处理的工作流程见下图:
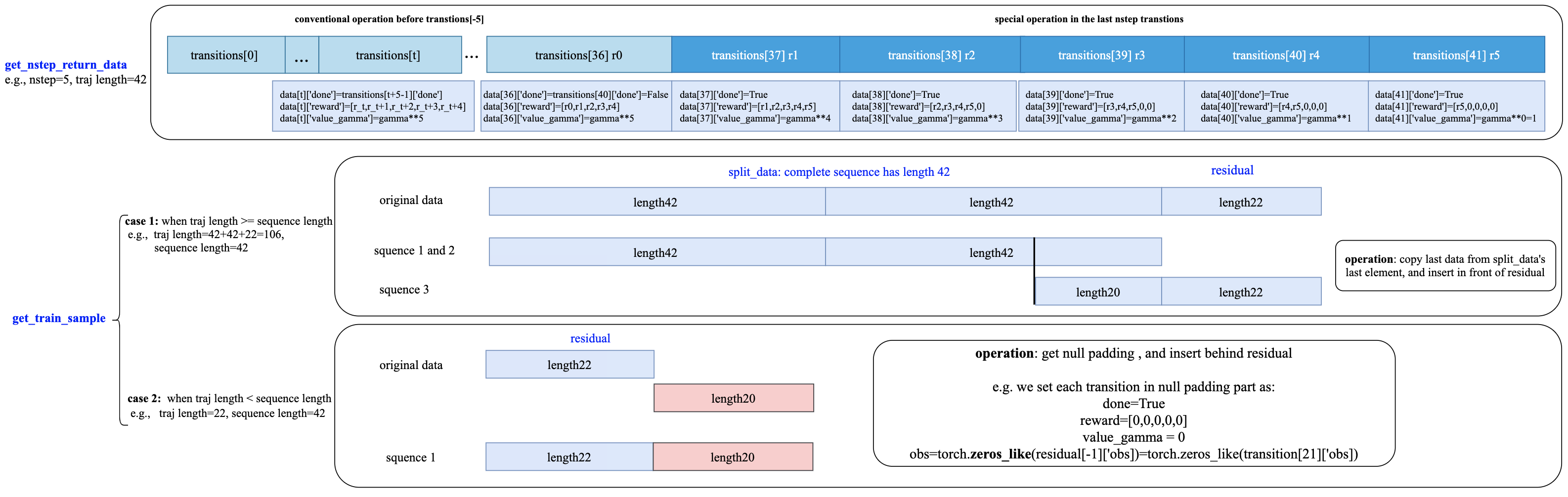
Burn-in(in R2D2)¶
Burn-in的概念来自 R2D2 (Recurrent Experience Replay In Distributed Reinforcement Learning)论文。论文指出在使用 LSTM 时,最基础的方式是:
1.将完整的 episode 轨迹切分为很多序列样本。在每个序列样本的初始时刻,使用全部为0的 tensor 作为 RNN 网络的初始化 hidden state。
2.使用完整的 episode 轨迹用于 RNN 训练。
对于第一种方法,由于每个序列样本的初始时刻的 hidden state 应该包含之前时刻的信息,这里简单使用全为0的 Tensor 带来很大的 bias 对于第二种方法,往往在不同环境上,完整的一个episode的长度是变化的,很难直接用于 RNN 的训练。
Burn-in 给予 RNN 网络一个
burn-in period。 即使用 replay sequence 的前面一部分数据产生一个开始的隐藏状态 (hidden state),然后仅在 replay sequence 的后面一部分数据上更新 RNN 网络。
在 DI-engine 中,r2d2 使用 n-step td error, 即, self._nstep 是 n 的数量。
sequence length = burnin_step + learn_unroll_len.
所以在配置文件中, learn_unroll_len 应该设置为 sequence length - burnin_step。
在此设置中,原始展开的 obs 序列被拆分为 burnin_nstep_obs , main_obs 和 marget_obs。 burnin_nstep_obs 是
用于计算 RNN 的初始隐藏状态,用便未来用于计算 q_value、target_q_value 和 target_q_action。
main_obs 用于计算 q_value。在下面的代码中, [bs:-self._nstep] 表示使用来自的数据
bs 时间步长到 sequence length - self._nstep 时间步长。
target_obs 用于计算 target_q_value。
这个数据处理可以通过下面的代码来实现:
data['action'] = data['action'][bs:-self._nstep]
data['reward'] = data['reward'][bs:-self._nstep]
data['burnin_nstep_obs'] = data['obs'][:bs + self._nstep]
data['main_obs'] = data['obs'][bs:-self._nstep]
data['target_obs'] = data['obs'][bs + self._nstep:]
在 R2D2 中,如果我们使用 burn-in, 重置的方式就不是那么简单了。
当我们调用 self._collect_model 的 forward 方法时,我们设置 inference=True ,每次调用它,我们只传入一个 timestep 数据, 所以我们可以在每个时间步得到 rnn 的隐藏状态:
prev_state。当我们调用 self._learn_model 的 forward 方法时,我们设置 inference=False ,当 self._learn_model 不是 inference 模式时,每次调用我们传入一个序列数据,他们输出的
prev_state字段只是最后一个时间步的隐藏状态,所以我们可以通过指定参数saved_hidden_state_timesteps的方式来指定要存储哪些隐藏状态。(saved_hidden_state_timesteps的数据格式是一个列表。 具体可参照 ding/model/template/q_learning.py ) 的self._learn_model的forward方法. 正如我们在下面的代码中看到的,我们首先将data['burnin_nstep_obs']传递给self._learn_model和self._target_model,以用于获取saved_hidden_state_timesteps列表中指定的不同时间步的hidden_state。 这些hidden_state将在后面计算q_value,target_q_value和target_q_action时使用.请注意,在 r2d2 中,我们指定
saved_hidden_state_timesteps=[self._burnin_step, self._burnin_step + self._nstep], 那么在调用完网络的forward方法后,burnin_output和burnin_output_target将会保存saved_hidden_state_timesteps里面指定时间步的hidden_state.
Note
- 在 DI-engine 中,每次调用 RNN 模型的 forward 方法时, 我们应该注意用
burnin_output['saved_hidden_state']这个隐藏状态重置这个网络。 因为本质上,当我们上次使用 RNN 模型时,RNN 模型的初始隐藏状态被设置为最后一个时间步隐藏状态。
def _forward_learn(self, data: dict) -> Dict[str, Any]:
# forward
data = self._data_preprocess_learn(data)
self._learn_model.train()
self._target_model.train()
# use the hidden state in timestep=0
self._learn_model.reset(data_id=None, state=data['prev_state'][0])
self._target_model.reset(data_id=None, state=data['prev_state'][0])
if len(data['burnin_nstep_obs']) != 0:
with torch.no_grad():
inputs = {'obs': data['burnin_nstep_obs'], 'enable_fast_timestep': True}
burnin_output = self._learn_model.forward(
inputs, saved_hidden_state_timesteps=[self._burnin_step, self._burnin_step + self._nstep]
)
burnin_output_target = self._target_model.forward(
inputs, saved_hidden_state_timesteps=[self._burnin_step, self._burnin_step + self._nstep]
)
self._learn_model.reset(data_id=None, state=burnin_output['saved_hidden_state'][0])
inputs = {'obs': data['main_obs'], 'enable_fast_timestep': True}
q_value = self._learn_model.forward(inputs)['logit']
self._learn_model.reset(data_id=None, state=burnin_output['saved_hidden_state'][1])
self._target_model.reset(data_id=None, state=burnin_output_target['saved_hidden_state'][1])
next_inputs = {'obs': data['target_obs'], 'enable_fast_timestep': True}
with torch.no_grad():
target_q_value = self._target_model.forward(next_inputs)['logit']
# argmax_action double_dqn
target_q_action = self._learn_model.forward(next_inputs)['action']
RNN和burn-in的更多细节可以参考 ding/policy/r2d2.py 。