CQL¶
综述¶
离线强化学习(RL)是一个新出现的研究领域,旨在使用大量预先收集的数据集学习行为,而无需进一步与环境进行交互。它有可能在许多实际决策问题中取得巨大进展, 其中与环境交互昂贵(例如,在机器人技术、药物发现、对话生成、推荐系统中)或不安全/危险(例如,在医疗保健、自动驾驶或教育中)。 此外,在线收集的数据量远远低于离线数据集。这样的范式有望解决将强化学习算法从受限实验室环境带到现实世界的关键挑战。
然而,直接在离线设置中使用现有的基于价值的离线 RL 算法通常会导致性能不佳,这是由于从分布外动作(out-of-distribution actions)引导和过度拟合等问题。因此,许多约束技术被添加到基本在线 RL 算法中。 保守 Q 学习(CQL),首次提出于 Conservative Q-Learning for Offline Reinforcement Learning, 是其中之一,它通过对标准基于价值的 RL 算法进行简单修改来学习保守 Q 函数,其期望值下限。
快速了解¶
CQL 是一种离线 RL 算法。
CQL 可以在许多标准在线 RL 算法之上用不到20行代码实现。
CQL 支持离散和连续动作空间。
重要公式/重要图示¶
CQL 可以在许多标准在线 RL 算法之上用不到20行代码实现,只需将 CQL 正则化项添加到 Q 函数更新中。
通常情况下,对于保守的离线策略评估,Q 函数通过迭代更新进行训练:
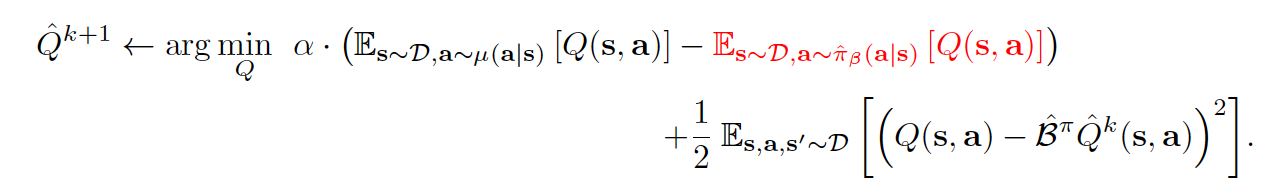
仔细观察上面的方程,它由两部分组成-正则化项和通常的贝尔曼误差与权衡因子 \(\alpha\) 。在正则化项内部, 第一项总是在从 \(\mu\) 采样的(s,a)对上推动 Q 值下降,而第二项在从离线数据集抽取的(s,a)样本上推动Q值上升。
根据以下定理,当 \(\mu\) = \(\pi\) 时,上述方程下限了策略 \(\pi\) 下的期望值。
对于合适的 \(\alpha\) ,在采样误差和函数近似下,该界限成立。我们还注意到,随着更多数据变得可用并且|D(s; a)|增加,保证下界所需的 \(\alpha\) 的理论值减小, 这表明在无限数据的极限情况下,可以通过使用极小的 \(\alpha\) 值获得下界。
请注意,下面提供的分析假定 Q 函数中未使用函数近似,这意味着每次迭代都可以精确表示。该定理中的结果可以进一步推广到线性函数逼近器和非线性神经网络函数逼近器的情况, 其中后者基于 neural tangent kernel(NTK)框架。有关更多详细信息,请参阅原始论文附录 D.1 中的定理 D.1 和定理 D.2。
那么,我们应该如何利用这一点进行策略优化呢?我们可以在每个策略迭代 \(\hat{\pi}^{k}(a|s)\) 之间交替执行完整的离线策略评估和一步策略改进。 然而,这可能会计算昂贵。另外,由于策略 \(\hat{\pi}^{k}(a|s)\) 通常源自Q函数,我们可以选择 \(\mu(a|s)\) 来近似最大化当前Q函数迭代的策略,从而产生一个在线算法。 因此,对于一个完整的离线RL算法,Q函数通常按如下方式更新:
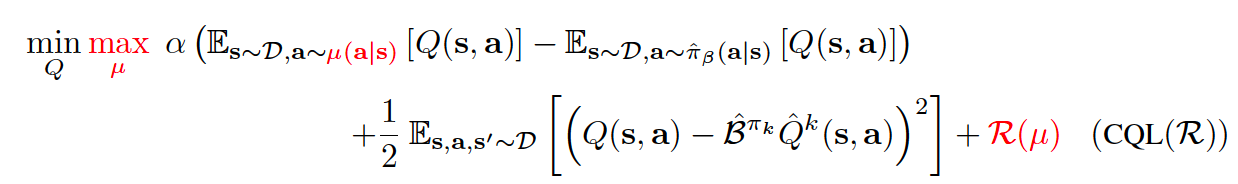
其中 \(CQL(R)\) 由正则化器 \(R(\mu)\) 的特定选择来表征。如果 \(R(\mu)\) 被选择为与先验分布 \(\rho(a|s)\) 的 KL 散度, 则我们得到 \(\mu(a|s)\approx \rho(a|s)exp(Q(s,a))\) 。首先,如果 \(\rho(a|s)\) = Unif(a),则上面的第一项对应于任何状态 s 下 Q 值的软最大值,并产生以下变体, 称为CQL(H):
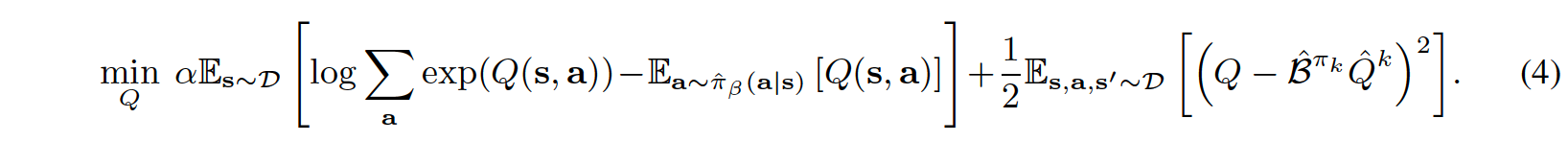
其次,如果 \(\rho(a|s)\) 被选择为前一个策略 \(\hat{\pi}^{k-1}\) ,则上述方程(4)中的第一项被替换为来自所选 \(\hat{\pi}^{k-1}(a|s)\) 的动作的 Q 值的指数加权平均值。
伪代码¶
伪代码显示在算法1中,与传统的 Actor-Critic 算法(例如SAC)和深度 Q 学习算法(例如DQN)的区别以红色显示。

上述伪代码中的方程4如下:
请注意,在实现过程中,方程(4)中的第一项将在 torch.logsumexp 下计算,这会消耗大量运行时间。
实现¶
CQL 算法的默认设置如下:
- class ding.policy.cql.CQLPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of CQL algorithm for continuous control. Paper link: https://arxiv.org/abs/2006.04779.
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
cql
RL policy register name, referto registryPOLICY_REGISTRYthis arg is optional,a placeholder2
cudabool
True
Whether to use cuda for network3
random_collect_sizeint
10000
Number of randomly collectedtraining samples in replaybuffer when training starts.Default to 10000 forSAC, 25000 for DDPG/TD3.4
model.policy_embedding_sizeint
256
Linear layer size for policynetwork.5
model.soft_q_embedding_sizeint
256
Linear layer size for soft qnetwork.6
model.value_embedding_sizeint
256
Linear layer size for valuenetwork.Defalut to None whenmodel.value_networkis False.7
learn.learning_rate_qfloat
3e-4
Learning rate for soft qnetwork.Defalut to 1e-3, whenmodel.value_networkis True.8
learn.learning_rate_policyfloat
3e-4
Learning rate for policynetwork.Defalut to 1e-3, whenmodel.value_networkis True.9
learn.learning_rate_valuefloat
3e-4
Learning rate for policynetwork.Defalut to None whenmodel.value_networkis False.10
learn.alphafloat
0.2
Entropy regularizationcoefficient.alpha is initiali-zation for autoalpha, whenauto_alpha is True11
learn.repara_meterizationbool
True
Determine whether to usereparameterization trick.12
learn.auto_alphabool
False
Determine whether to useauto temperature parameteralpha.Temperature parameterdetermines therelative importanceof the entropy termagainst the reward.13
learn.-ignore_donebool
False
Determine whether to ignoredone flag.Use ignore_done onlyin halfcheetah env.14
learn.-target_thetafloat
0.005
Used for soft update of thetarget network.aka. Interpolationfactor in polyak averaging for targetnetworks.
- class ding.policy.cql.DiscreteCQLPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of discrete CQL algorithm in discrete action space environments. Paper link: https://arxiv.org/abs/2006.04779.
Benchmark¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
HalfCheetah (Medium Expert) |
57.6 \(\pm\) 3.7 |
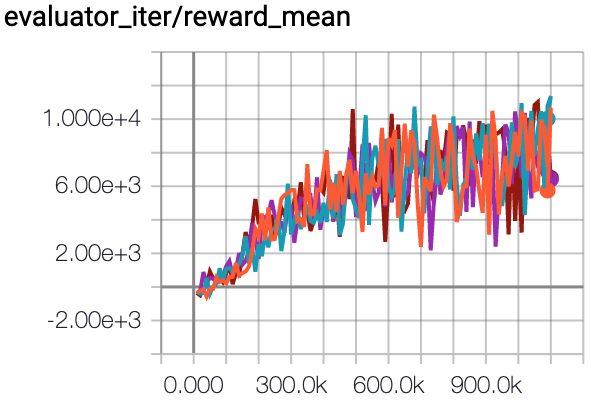
|
CQL Repo (75.6 \(\pm\) 25.7) |
|
Walker2d (Medium Expert) |
109.7 \(\pm\) 0.8 |
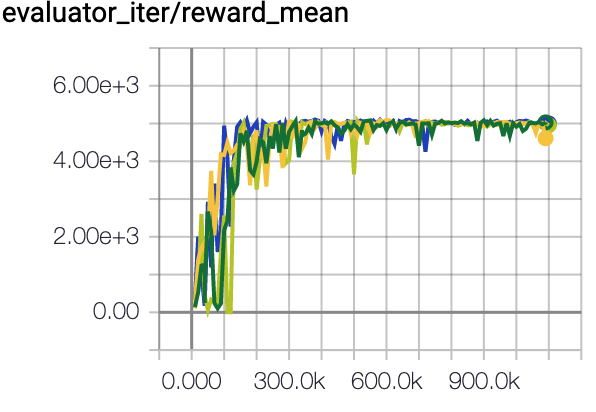
|
CQL Repo (107.9 \(\pm\) 1.6) |
|
Hopper (Medium Expert) |
85.4 \(\pm\) 14.8 |
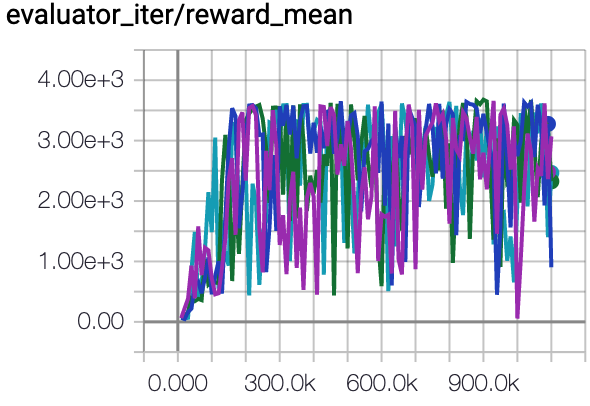
|
CQL Repo (105.6 \(\pm\) 12.9) |
对于每个数据集,我们的实现结果如下:
environment |
random |
medium replay |
medium expert |
medium |
expert |
|---|---|---|---|---|---|
HalfCheetah |
18.7 \(\pm\) 1.2 |
47.1 \(\pm\) 0.3 |
57.6 \(\pm\) 3.7 |
49.7 \(\pm\) 0.4 |
75.1 \(\pm\) 18.4 |
Walker2d |
22.0 \(\pm\) 0.0 |
82.6 \(\pm\) 3.4 |
109.7 \(\pm\) 0.8 |
82.4 \(\pm\) 1.9 |
109.2 \(\pm\) 0.3 |
Hopper |
3.1 \(\pm\) 2.6 |
98.3 \(\pm\) 1.8 |
85.4 \(\pm\) 14.8 |
79.6 \(\pm\) 8.5 |
105.4 \(\pm\) 7.2 |
P.S.:
上述结果是通过在四个不同的随机种子(5、10、20、30)上运行相同的配置获得的。
上述基准测试是针对HalfCheetah-v2、Hopper-v2、Walker2d-v2。
上述比较结果是通过论文 Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning. 获得的。完整表格如下所示。
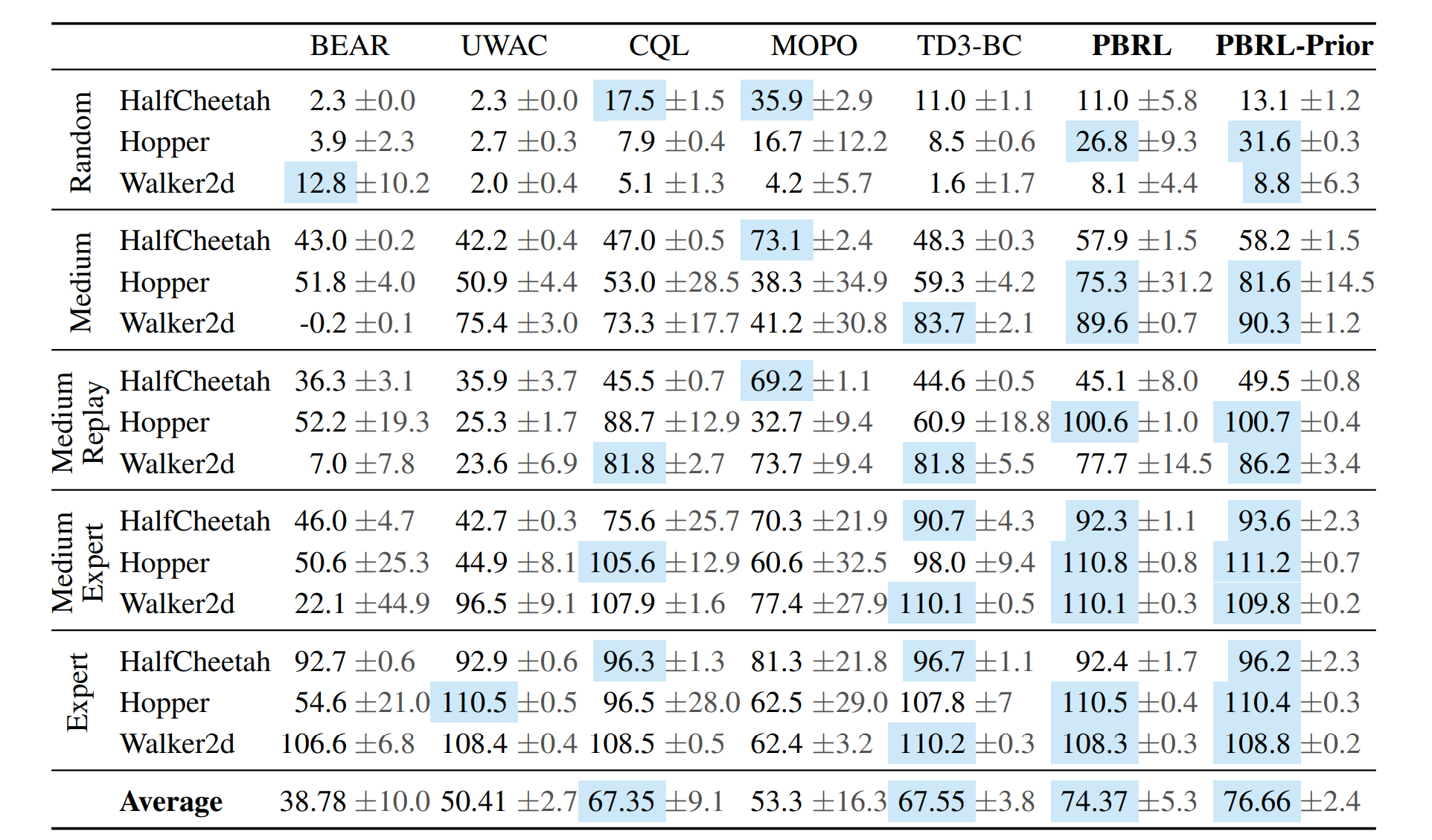
上图给出了没有进行归一化(可以直接通过 env.get_normalized_score 函数得到)的结果。
引用¶
Kumar, Aviral, et al. “Conservative q-learning for offline reinforcement learning.” arXiv preprint arXiv:2006.04779 (2020).
Chenjia Bai, et al. “Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning.”