MBPO¶
Overview¶
Model-based policy optimization (MBPO) was first proposed in When to Trust Your Model: Model-Based Policy Optimization. MBPO utilizes short model-generated rollouts and provides a guarantee of monotonic improvement at each step. In details, MBPO trains an ensemble of models to fit the transitions of the true environment and uses it to generate short trajectories starting from real environment states to do policy improvement. For the choice of RL policy, MBPO use SAC as its RL component.
See this repo awesome-model-based-RL for more model-based rl papers.
Quick Facts¶
MBPO is a model-based RL algorithm.
MBPO uses SAC as RL policy.
MBPO only supports continuous action spaces.
MBPO uses model-ensemble.
Key Equations or Key Graphs¶
Predictive Model¶
MBPO utilizes an ensemble of gaussian neural network, each member of the ensemble is:
The maximum likelihood loss used in model training is:
Policy Optimization¶
Policy evaluation step:
Policy improvement step:
Note: This update guarantees that \(Q^{\pi_{new}}(\boldsymbol{s}_t,\boldsymbol{a}_t) \geq Q^{\pi_{old}}(\boldsymbol{s}_t,\boldsymbol{a}_t)\), please check the proof on this Lemma2 in the Appendix B.2 in the original paper.
Pseudo-code¶

Note
The initial implementation of MBPO only give the hyper-parameters of applying it on SAC, which does not fit DDPG and TD3 well.
Implementations¶
The default config of mbpo model is defined as follows:
- class ding.world_model.mbpo.MBPOWorldModel(cfg, env, tb_logger)[source]
Benchmark¶
environment |
evaluation results |
config link |
|---|---|---|
Hopper |
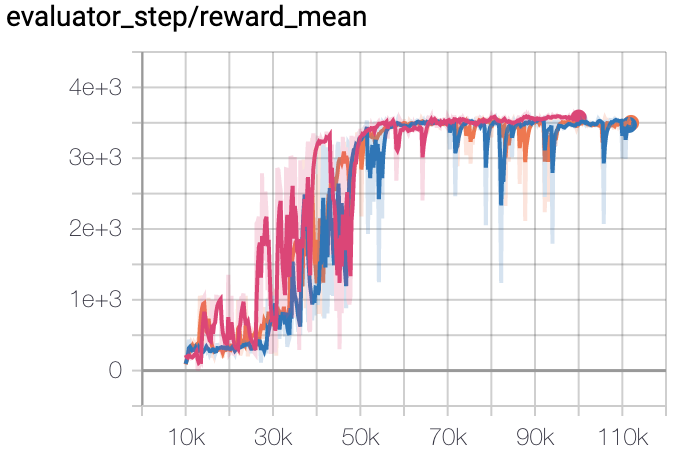
|
|
Halfcheetah |
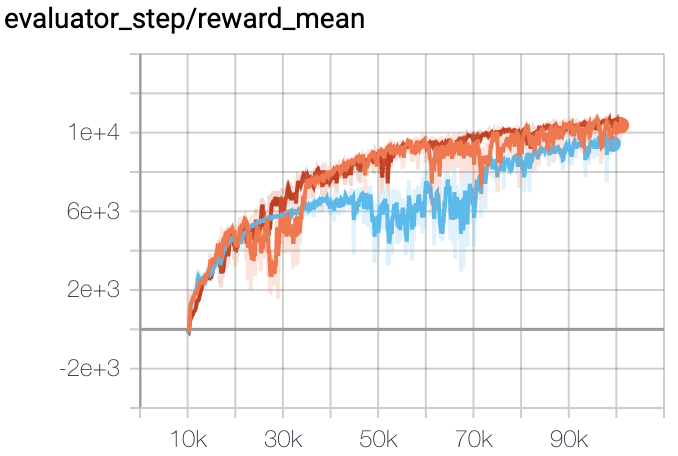
|
|
Walker2d |
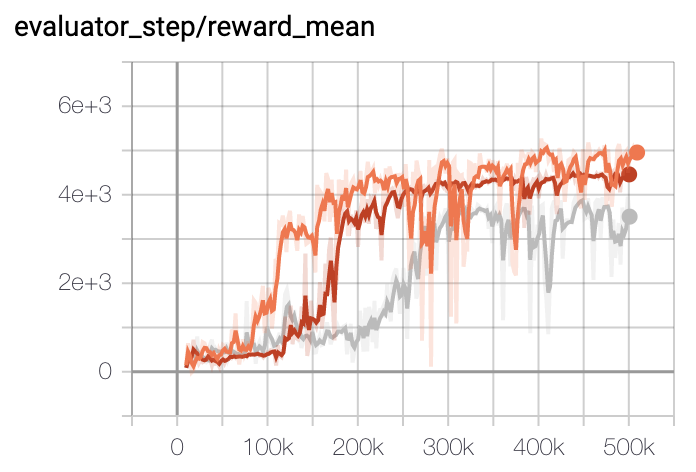
|
P.S.:
The above results are obtained by running the same configuration on three different random seeds (0, 1, 2).
Other Public Implementations¶
Reference¶
Michael Janner, Justin Fu, Marvin Zhang, Sergey Levine: “When to Trust Your Model: Model-Based Policy Optimization”, 2019; arXiv:1906.08253.