VPN¶
Overview¶
Value Prediction Network(VPN) was first proposed in Value Prediction Network from NeurIPS 2017. Value prediction network is an improvement upon the traditional model-based reinforcement learning algorithm and a predecessor of the Muzero algorithm.
The main motivation of the VPN algorithm is that the planning phase of RL only needs to predict future rewards and value without predicting future observations.
VPN learns to predict values via Q-learning and rewards via supervised learning at the same time, VPN performs lookahead planning to choose actions and compute bootstrapped target Q-values.
(i.e., learning the dynamics of an abstract state space sufficient for computing future rewards and values)
Quick Facts¶
VPN can be viewed as combination of model-based RL and model-free RL.
The model-based part of VPN is to learn the dynamics of an abstract state space sufficient for computing future rewards and values, and the model-free part of VPN is to map the learned abstract states to rewards and values.
VPN combines temporal-difference search and n-step Q-learning to train.
The major performance improvement VPN has compared to other model-based algorithms is that VPN is more robust to stochasticity in the environment than an observation-prediction model approach.
In order to solve some of the existing problems of model-based algorithms, the VPN proposes a method between traditional model-based algorithms and model-free algorithms, using dynamics model to model the environment.
From a model-based perspective, the dynamics model models the state transition process, reward and discount function of the environment by extracting the form of abstract state.
From a model-free perspective, the extraction of abstract state by dynamics model can be regarded as an auxiliary task of training critic to predict reward and value, in order to better extract the relevant representation of the state.
VPN uses simple rollout and beam search, VPN + Monte Carlo Tree Search(MCTS) \(\approxeq\) Muzero.
Note
The model-based algorithm has better sample efficiency, but is more complicated; The model-free algorithm has lower sample efficiency, but is relatively simple and easier to implement. The model-based algorithm is not as popular as the model-free algorithm, due to its complexity, and is mostly used in environments that are costly to acquire data, such as robot-arm control. This is because the model-base algorithm involves environment modeling, resulting in a complicated modeling process. Besides, environment modeling also requires training, the overall training process for the model-based method is much more difficult than the model-free method. Most of the environmental models modeled by model-based algorithms use observation and action to predict the next observation and reward. This kind of model is called an observation-prediction model. In a relatively complex environment, observation usually has a higher dimension and is highly stochastic, which makes it difficult for model-based algorithms to learn the observation-prediction model corresponding to the environment.
Key Equations or Key Graphs¶
Value Prediction Network mainly consists of 4 parts:
The VPN consists of the following modules parameterized by \(\theta=\left\{\theta^{\text {enc }}, \theta^{\text {value }}, \theta^{\text {out }}, \theta^{\text {trans }}\right\}\):
Encoding \(f_{\theta}^{\text {enc }}: \mathbf{x} \mapsto \mathbf{s} \quad\)
Value \(f_{\theta}^{\text {value }}: \mathbf{s} \mapsto V_{\theta}(\mathbf{s})\)
Outcome \(f_{\theta}^{\text {out }}: \mathbf{s}, \mathbf{o} \mapsto r, \gamma\)
Transition \(f_{\theta}^{\text {trans }}:\) s, \(\mathbf{o} \mapsto \mathbf{s}^{\prime}\)
Encoding module maps the observation \((\mathbf{x})\) to the abstract state \(\left(\mathbf{s} \in \mathbb{R}^{m}\right)\) using neural networks (e.g., CNN for visual observations). Thus, \(\mathbf{s}\) is an abstract-state representation which will be learned by the network (and not an environment state or even an approximation to one).
Value module estimates the value of the abstract-state \(\left(V_{\theta}(\mathbf{s})\right)\). Note that the value module is not a function of the observation, but a function of the abstract-state.
Outcome module predicts the option-reward \((r \in \mathbb{R})\) for executing the option \(\mathbf{0}\) at abstract-state s. If the option takes \(k\) primitive actions before termination, the outcome module should predict the discounted sum of the \(k\) immediate rewards as a scalar. The outcome module also predicts the option-discount \((\gamma \in \mathbb{R})\) induced by the number of steps taken by the option.
Transition module transforms the abstract-state to the next abstract-state \(\left(\mathbf{s}^{\prime} \in \mathbb{R}^{m}\right)\) in an optionconditional manner.
The Q value can be estimated through the above four parts, that is, input observation and the corresponding option (action), and output the corresponding value estimation.
The corresponding Q-value prediction formula is:
\(Q_{\theta}^{d}(\mathbf{s}, \mathbf{o})=r+\gamma V_{\theta}^{d}\left(\mathbf{s}^{\prime}\right) \quad V_{\theta}^{d}(\mathbf{s})=\left\{\begin{array}{ll} V_{\theta}(\mathbf{s}) & \text { if } d=1 \\ \frac{1}{d} V_{\theta}(\mathbf{s})+\frac{d-1}{d} \max _{\mathbf{0}} Q_{\theta}^{d-1}(\mathbf{s}, \mathbf{o}) & \text { if } d>1 \end{array}\right.\)
The d-step planning process is shown below:
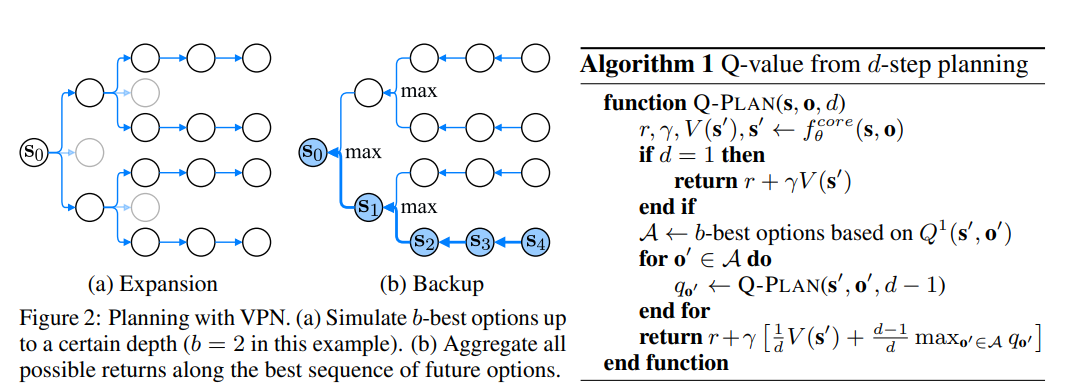
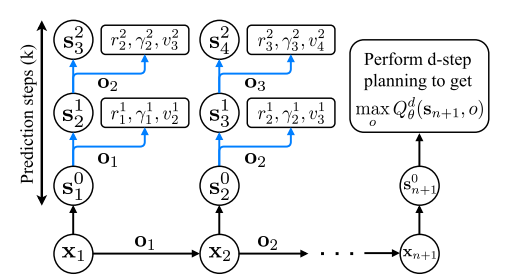
When training, VPN use k-step prediction to train:
\(\mathbf{s}_{t}^{k}=\left\{\begin{array}{ll} f_{\theta}^{\text {enc }}\left(\mathbf{x}_{t}\right) & \text { if } k=0 \\ f_{\theta}^{\text {trans }}\left(\mathbf{s}_{t-1}^{k-1}, \mathbf{o}_{t-1}\right) & \text { if } k>0 \end{array} \quad v_{t}^{k}=f_{\theta}^{\text {value }}\left(\mathbf{s}_{t}^{k}\right) \quad r_{t}^{k}, \gamma_{t}^{k}=f_{\theta}^{\text {out }}\left(\mathbf{s}_{t}^{k-1}, \mathbf{o}_{t}\right)\right.\)
The entire update flow chart is as follows:
Pseudo-code¶

Extensions¶
VPN can be combined with:
Monte Carlo Tree Search(MCTS)
In the VPN paper, the author mentioned that the VPN algorithm is compatible with other tree search algorithms such as MCTS, but in the specific experiment, the paper uses a simple Rollout for simplification. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model replaces the simple rollout with MCTS, and achieves superhuman performance in a range of challenging and visually complex domains, without any knowledge of their underlying dynamics.
Implementations¶
The default config is defined as follows:
TBD
The network interface VPN used is defined as follows:
TBD
Reference¶
Junhyuk Oh, Satinder Singh, Honglak Lee: “Value Prediction Network”, 2017; [http://arxiv.org/abs/1707.03497 arXiv:1707.03497].
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, David Silver: “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model”, 2019; [http://arxiv.org/abs/1911.08265 arXiv:1911.08265]. DOI: [https://dx.doi.org/10.1038/s41586-020-03051-4 10.1038/s41586-020-03051-4].