PPG¶
Overview¶
PPG was proposed in Phasic Policy Gradient. In prior methods, one must choose between using a shared network or separate networks to represent the policy and value function. Using separate networks avoids interference between objectives, while using a shared network allows useful features to be shared. PPG is able to achieve the best of both worlds by splitting optimization into two phases, one that advances training and one that distills features.
Quick Facts¶
PPG is a model-free and policy-based RL algorithm.
PPG supports both discrete and continuous action spaces.
PPG supports off-policy mode and on-policy mode.
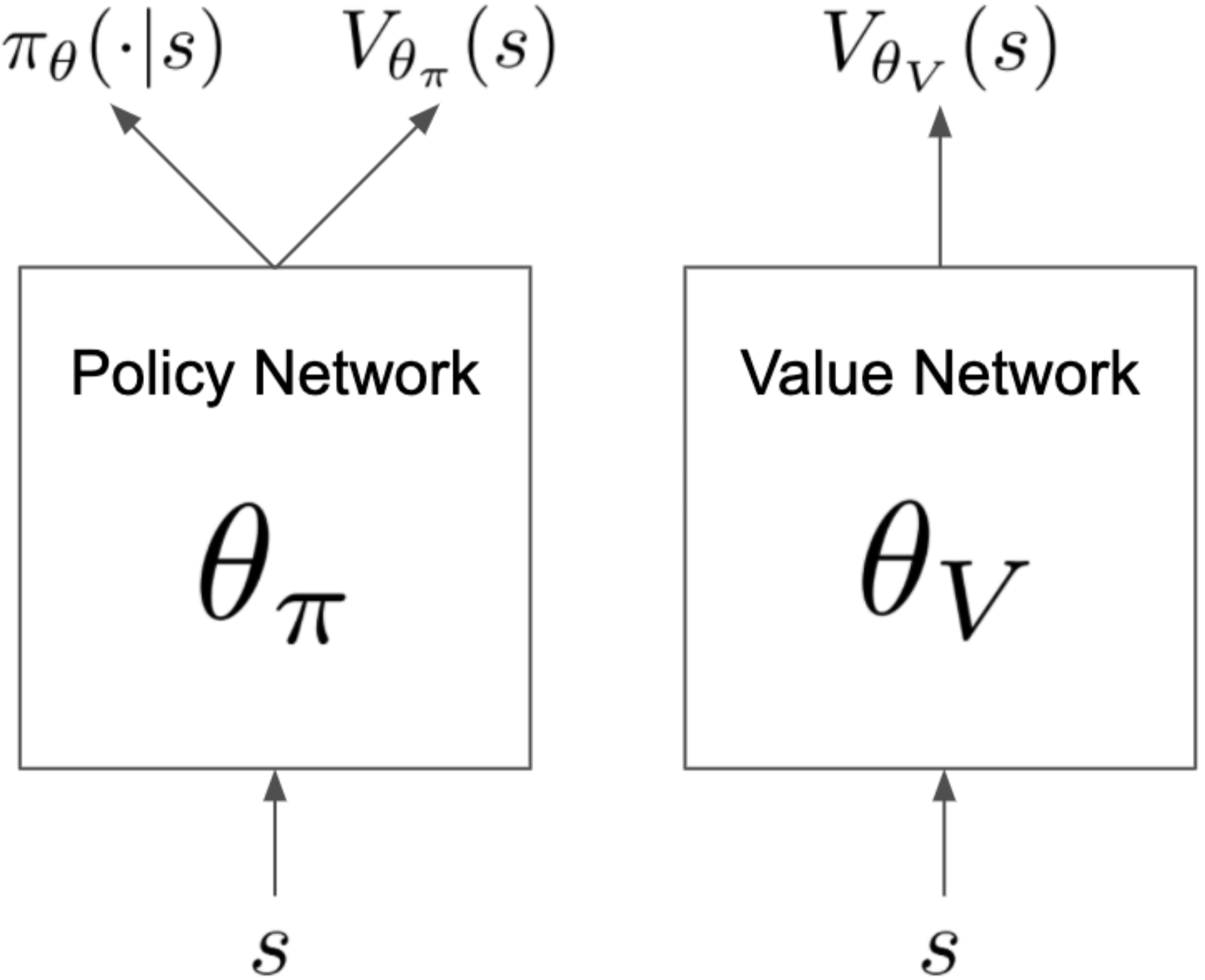
There are two value networks in PPG.
In the implementation of DI-engine, we use two buffers for off-policy PPG, which are only different from maximum data usage limit (data
max_use).
Key Graphs¶
PPG utilizes disjoint policy and value networks to reduce interference between objectives. The policy network includes an auxiliary value head which is used to distill the knowledge of value into the policy network, the concrete network architecture is shown as follows:
Key Equations¶
The optimization of PPG alternates between two phases, a policy phase and an auxiliary phase. During the policy phase, the policy network and the value network are updated similar to PPO. During the auxiliary phase, the value knowledge is distilled into the policy network with the joint loss:
The joint loss optimizes the auxiliary objective (distillation) while preserves the original policy with the KL-divergence restriction (i.e. the second item). And the auxiliary loss is defined as:
Pseudo-code¶
on-policy training procedure¶
The following flow charts show how PPG alternates between the policy phase and the auxiliary phase

Note
During the auxiliary phase, PPG also takes the opportunity to perform additional training on the value network.
off-policy training procedure¶
DI-engine also implements off-policy PPG with two buffers with different data use constraint (max_use), which policy buffer offers data for policy phase while value buffer provides auxiliary phase’s data. The whole training procedure is similar to off-policy PPO but execute additional auxiliary phase with a fixed frequency.
Extensions¶
PPG can be combined with:
GAE or other advantage estimation method
Multi-buffer, different
max_use
PPO (or PPG) + UCB-DrAC + PLR is one of the most powerful methods in procgen environment.
Implementation¶
The default config is defined as follows:
- class ding.policy.ppg.PPGPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of PPG algorithm. PPG is a policy gradient algorithm with auxiliary phase training. The auxiliary phase training is proposed to distill the value into the policy network, while making sure the policy network does not change the action predictions (kl div loss). Paper link: https://arxiv.org/abs/2009.04416.
- Interface:
_init_learn,_data_preprocess_learn,_forward_learn,_state_dict_learn,_load_state_dict_learn,_init_collect,_forward_collect,_process_transition,_get_train_sample,_get_batch_size,_init_eval,_forward_eval,default_model,_monitor_vars_learn,learn_aux.- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
ppg
RL policy register name, refer toregistryPOLICY_REGISTRYthis arg is optional,a placeholder2
cudabool
False
Whether to use cuda for networkthis arg can be diff-erent from modes3
on_policybool
True
Whether the RL algorithm is on-policyor off-policyprioritybool
False
Whether use priority(PER)priority sample,update priority5
priority_IS_weightbool
False
Whether use Importance SamplingWeight to correct biased update.IS weight6
learn.update_per_collectint
5
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingthis args can be varyfrom envs. Bigger valmeans more off-policy7
learn.value_weightfloat
1.0
The loss weight of value networkpolicy network weightis set to 18
learn.entropy_weightfloat
0.01
The loss weight of entropyregularizationpolicy network weightis set to 19
learn.clip_ratiofloat
0.2
PPO clip ratio10
learn.adv_normbool
False
Whether to use advantage norm ina whole training batch11
learn.aux_freqint
5
The frequency(normal update times)of auxiliary phase training12
learn.aux_train_epochint
6
The training epochs of auxiliaryphase13
learn.aux_bc_weightint
1
The loss weight of behavioral_cloningin auxiliary phase14
collect.discount_factorfloat
0.99
Reward’s future discount factor, aka.gammamay be 1 when sparsereward env15
collect.gae_lambdafloat
0.95
GAE lambda factor for the balanceof bias and variance(1-step td and mc)
The network interface PPG used is defined as follows:
- class ding.model.template.ppg.PPG(obs_shape: int | SequenceType, action_shape: int | SequenceType, action_space: str = 'discrete', share_encoder: bool = True, encoder_hidden_size_list: SequenceType = [128, 128, 64], actor_head_hidden_size: int = 64, actor_head_layer_num: int = 2, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, impala_cnn_encoder: bool = False)[source]
- Overview:
Phasic Policy Gradient (PPG) model from paper Phasic Policy Gradient https://arxiv.org/abs/2009.04416 This module contains VAC module and an auxiliary critic module.
- Interfaces:
forward,compute_actor,compute_critic,compute_actor_critic
- compute_actor(x: Tensor) Dict[source]
- Overview:
Use actor to compute action logits.
- Arguments:
x (
torch.Tensor): The input observation tensor data.
- Returns:
output (
Dict): The output data containing action logits.
- ReturnsKeys:
logit (
torch.Tensor): The predicted action logit tensor, for discrete action space, it will be the same dimension real-value ranged tensor of possible action choices, and for continuous action space, it will be the mu and sigma of the Gaussian distribution, and the number of mu and sigma is the same as the number of continuous actions. Hybrid action space is a kind of combination of discrete and continuous action space, so the logit will be a dict withaction_typeandaction_args.
- Shapes:
x (
torch.Tensor): \((B, N)\), where B is batch size and N is the input feature size.output (
Dict):logit: \((B, A)\), where B is batch size and A is the action space size.
- compute_actor_critic(x: Tensor) Dict[source]
- Overview:
Use actor and critic to compute action logits and value.
- Arguments:
x (
torch.Tensor): The input observation tensor data.
- Returns:
outputs (
Dict): The output dict of PPG’s forward computation graph for both actor and critic, includinglogitandvalue.
- ReturnsKeys:
logit (
torch.Tensor): The predicted action logit tensor, for discrete action space, it will be the same dimension real-value ranged tensor of possible action choices, and for continuous action space, it will be the mu and sigma of the Gaussian distribution, and the number of mu and sigma is the same as the number of continuous actions. Hybrid action space is a kind of combination of discrete and continuous action space, so the logit will be a dict withaction_typeandaction_args.value (
torch.Tensor): The predicted state value tensor.
- Shapes:
x (
torch.Tensor): \((B, N)\), where B is batch size and N is the input feature size.output (
Dict):value: \((B, 1)\), where B is batch size.output (
Dict):logit: \((B, A)\), where B is batch size and A is the action space size.
Note
compute_actor_criticinterface aims to save computation when shares encoder.
- compute_critic(x: Tensor) Dict[source]
- Overview:
Use critic to compute value.
- Arguments:
x (
torch.Tensor): The input observation tensor data.
- Returns:
output (
Dict): The output dict of VAC’s forward computation graph for critic, includingvalue.
- ReturnsKeys:
necessary:
value
- Shapes:
x (
torch.Tensor): \((B, N)\), where B is batch size and N is the input feature size.output (
Dict):value: \((B, 1)\), where B is batch size.
Benchmark¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
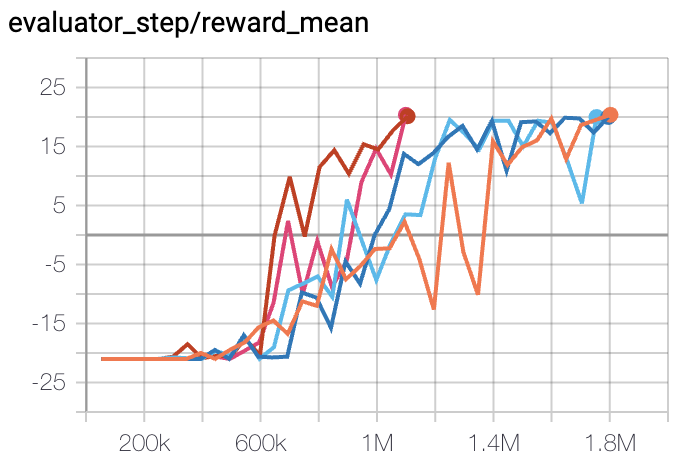
Pong
(PongNoFrameskip-v4)
|
20 |
|
DI-engine PPO off-policy(20)
|
|
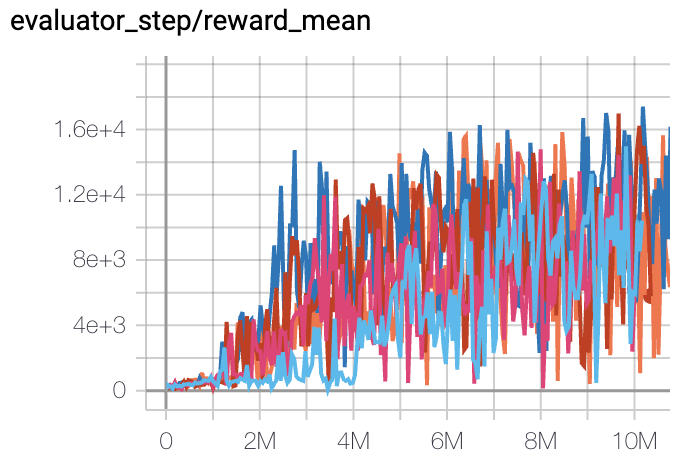
Qbert
(QbertNoFrameskip-v4)
|
17775 |
|
DI-engine PPO off-policy(16400)
|
|
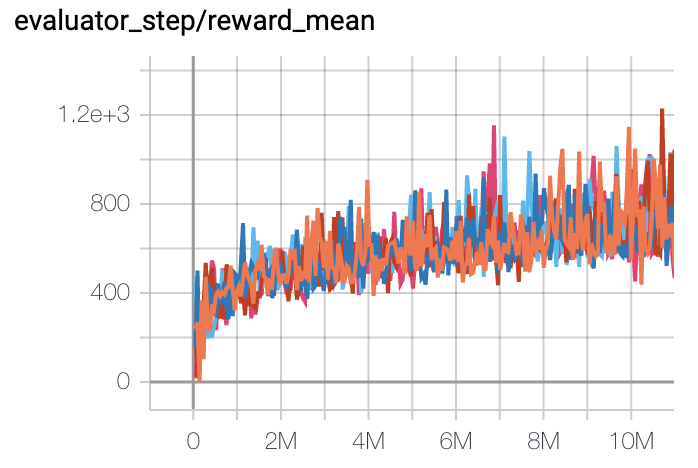
SpaceInvaders
(SpaceInvadersNoFrame skip-v4)
|
1213 |
|
DI-engine PPO off-policy(1200)
|
References¶
Karl Cobbe, Jacob Hilton, Oleg Klimov, John Schulman: “Phasic Policy Gradient”, 2020; arXiv:2009.04416.