QTRAN¶
Overview¶
QTRAN is proposed by Kyunghwan et al.(2019). QTRAN is a factorization method for MARL, which is free from such structural constraints and takes on a new approach to transform the original joint action-value function into an easily factorizable one, with the same optimal actions.
Compared to VDN(Sunehag et al. 2017), QMIX(Rashid et al. 2018), QTRAN guarantees more general factorization than VDN or QMIX, thus covering a much wider class of MARL tasks than does previous methods, and it performs better than QMIX in 5m_vs_6m and MMM2 maps.
Quick Facts¶
QTRAN uses the paradigm of centralized training with decentralized execution.
QTRAN is a model-free and value-based method.
QTRAN only support discrete action spaces.
QTRAN is an off-policy multi-agent RL algorithm.
QTRAN considers a partially observable scenario in which each agent only obtains individual observations.
QTRAN accepts DRQN as individual value network.
QTRAN learns the joint value function through Individual action-value network, Joint action-value network and State-value network.
Key Equations or Key Graphs¶
The overall QTRAN architecture including individual agent networks and the mixing network structure:
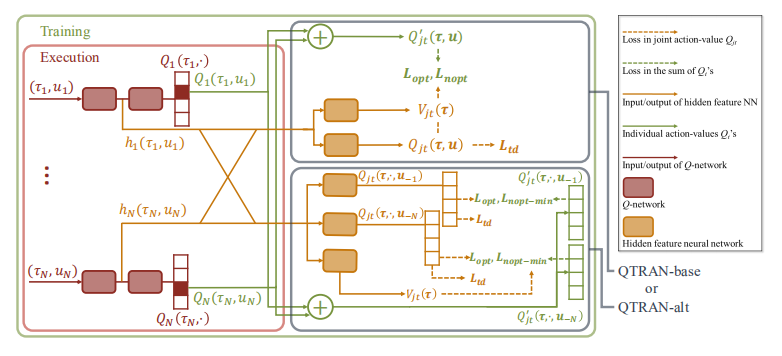
QTRAN trains the mixing network via minimizing the following loss:
Pseudo-code¶
The following flow charts show how QTRAN trains.

Extensions¶
QTRAN++ (Son et al. 2019), as an extension of QTRAN, successfully bridges the gap between empirical performance and theoretical guarantee, and newly achieves state-of-the-art performance in the SMAC environment.
Implementations¶
The default config is defined as follows:
- class ding.policy.qtran.QTRANPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of QTRAN algorithm. QTRAN is a multi model reinforcement learning algorithm, you can view the paper in the following link https://arxiv.org/abs/1803.11485
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
qtran
POLICY_REGISTRY2
cudabool
True
3
on_policybool
False
prioritybool
False
5
priority_IS_weightbool
False
6
learn.update_per_collectint
20
7
learn.target_update_thetafloat
0.001
8
learn.discount_factorfloat
0.99
- The network interface QTRAN used is defined as follows:
- ding.model.template.qtran
alias of <module ‘ding.model.template.qtran’ from ‘/home/runner/work/DI-engine/DI-engine/ding/model/template/qtran.py’>
The Benchmark result of QTRAN in SMAC (Samvelyan et al. 2019), for StarCraft micromanagement problems, implemented in DI-engine is shown.
smac map |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
MMM |
1.00 |
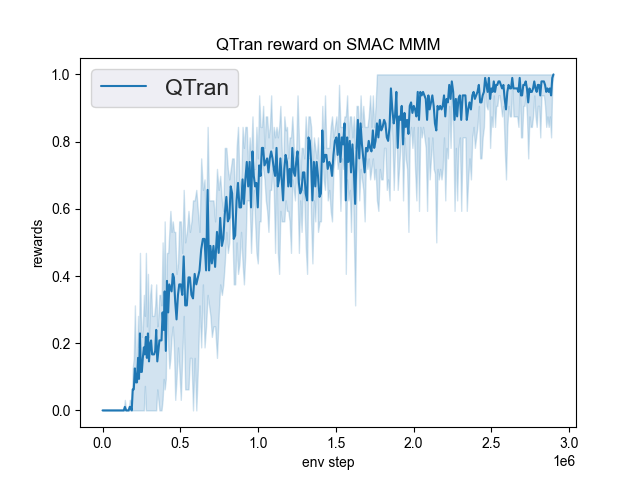
|
Pymarl(1.0) |
|
3s5z |
0.95 |
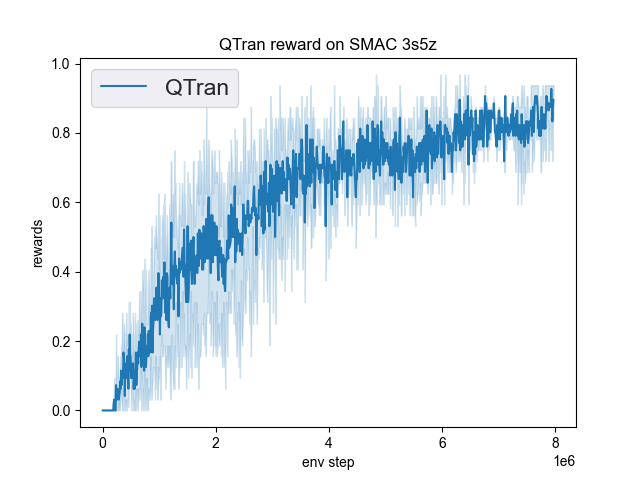
|
Pymarl(0.1) |
|
5m6m |
0.55 |
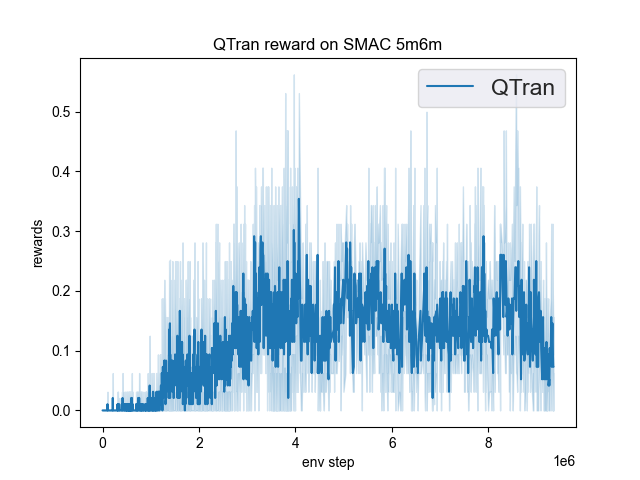
|
Pymarl(0.7) |
References¶
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning. ICML, 2019.