WQMIX¶
Overview¶
WQMIX was first proposed in Weighted QMIX: Expanding Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. Their focus of study is the unique properties of the particular function space represented by monotonic structure of Q functions in QMIX, and the tradeoffs in representation quality across different joint actions induced by projection into that space. They show that the projection in QMIX can fail to recover the optimal policy, which primarily stems from the equal weighting placed on each joint action. WQMIX rectify this by introducing a weighting into the projection, in order to place more importance on the better joint actions.
WQMIX propose two weighting schemes and prove that they recover the correct maximal action for any joint action Q-values.
WQMIX introduce two scalable versions: Centrally-Weighted (CW) QMIX and Optimistically-Weighted (OW) QMIX and demonstrate improved performance on both predator-prey and challenging multi-agent StarCraft benchmark tasks.
Quick Facts¶
WQMIX is an off-policy model-free value-based multi-agent RL algorithm using the paradigm of centralized training with decentralized execution. And only support discrete action spaces.
WQMIX considers a partially observable scenario in which each agent only obtains individual observations.
WQMIX accepts DRQN as individual value network.
WQMIX represents the joint value function using an architecture consisting of agent networks and a mixing network. The mixing network is a feed-forward neural network that takes the agent network outputs as input and mixes them monotonically, producing joint action values.
Key Equations or Key Graphs¶
The overall WQMIX architecture including individual agent networks and the mixing network structure:
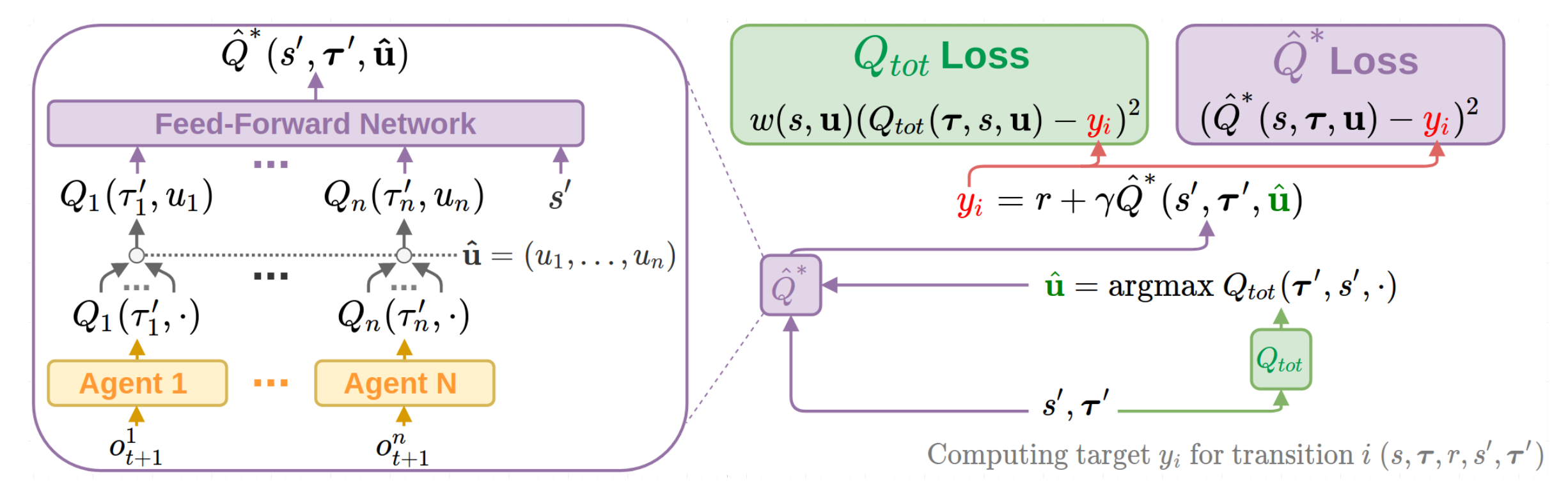
First, WQMIX examine an operator that represents an idealised version of QMIX in a tabular setting. The purpose of this analysis is primarily to understand the fundamental limitations of QMIX that stem from its training objective and the restricted function class it uses. This is the space of all \(Q_{tot}\) that can be represented by monotonic funtions of tabular \(Q_{a}(s,u)\) :
At each iteration of our idealised QMIX algorithm, we constrain \(Q_{tot}\) to lie in the above space by solving the following optimisation problem:
where, the Bellman optimality operator is defined by:
Then define the corresponding projection operator \(T^{Qmix}\) as follows:
Properties of \(T_{*}^{Qmix}\) :
\(T_{*}^{Qmix}\) is not a contraction.
QMIX’s argmax is not always correct.
QMIX can underestimate the value of the optimal joint action.
The WQMIX paper argues that this equal weighting over joint actions when performing the optimisation in QMIX. is responsible for the possibly incorrect argmax of the objective minimising solution. To prioritise estimating \(T_{tot}(u^{*})\) well, while still anchoring down the value estimates for other joint actions, we can add a suitable weighting function w into the projection operator of QMIX:
The choice of weighting is crucial to ensure that WQMIX can overcome the limitations of QMIX. WQMIX considers two different weightings and proved that these choices of w ensure that the \(Q_{tot}\) returned from the projection has the correct argmax.
Idealised Central Weighting: It implies down-weight every suboptimal action. However, this weighting requires computing the maximum across the joint action space, which is often infeasible. In implementation WQMIX takes an approximation to this weighting in the deep RL setting.
Optimistic Weighting: This weighting assigns a higher weighting to those joint actions that are underestimated relative to Q, and hence could be the true optimal actions (in an optimistic outlook).
For the details analysis, please refer to the WQMIX paper.
Implementations¶
The default config is defined as follows:
- class ding.policy.wqmix.WQMIXPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
- Policy class of WQMIX algorithm. WQMIX is a reinforcement learning algorithm modified from Qmix,
you can view the paper in the following link https://arxiv.org/abs/2006.10800
- Interface:
- _init_learn, _data_preprocess_learn, _forward_learn, _reset_learn, _state_dict_learn, _load_state_dict_learn
_init_collect, _forward_collect, _reset_collect, _process_transition, _init_eval, _forward_eval_reset_eval, _get_train_sample, default_model
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
qmix
POLICY_REGISTRY2
cudabool
True
3
on_policybool
False
prioritybool
False
5
priority_IS_weightbool
False
6
learn.update_per_collectint
20
7
learn.target_update_thetafloat
0.001
8
learn.discount_factorfloat
0.99
The network interface WQMIX used is defined as follows:
- class ding.model.template.WQMix(agent_num: int, obs_shape: int, global_obs_shape: int, action_shape: int, hidden_size_list: list, lstm_type: str = 'gru', dueling: bool = False)[source]
- Overview:
WQMIX (https://arxiv.org/abs/2006.10800) network, There are two components: 1) Q_tot, which is same as QMIX network and composed of agent Q network and mixer network. 2) An unrestricted joint action Q_star, which is composed of agent Q network and mixer_star network. The QMIX paper mentions that all agents share local Q network parameters, so only one Q network is initialized in Q_tot or Q_star.
- Interface:
__init__,forward.
- forward(data: dict, single_step: bool = True, q_star: bool = False) dict[source]
- Overview:
Forward computation graph of qmix network. Input dict including time series observation and related data to predict total q_value and each agent q_value. Determine whether to calculate Q_tot or Q_star based on the
q_starparameter.- Arguments:
- data (
dict): Input data dict with keys [‘obs’, ‘prev_state’, ‘action’].
agent_state (
torch.Tensor): Time series local observation data of each agents.global_state (
torch.Tensor): Time series global observation data.prev_state (
list): Previous rnn state forq_networkor_q_network_star.action (
torch.Tensoror None): If action is None, use argmax q_value index as action to calculateagent_q_act.single_step (
bool): Whether single_step forward, if so, add timestep dim before forward and remove it after forward.Q_star (
bool): Whether Q_star network forward. If True, using the Q_star network, where the agent networks have the same architecture as Q network but do not share parameters and the mixing network is a feedforward network with 3 hidden layers of 256 dim; if False, using the Q network, same as the Q network in Qmix paper.- Returns:
ret (
dict): Output data dict with keys [total_q,logit,next_state].total_q (
torch.Tensor): Total q_value, which is the result of mixer network.agent_q (
torch.Tensor): Each agent q_value.next_state (
list): Next rnn state.- Shapes:
agent_state (
torch.Tensor): \((T, B, A, N)\), where T is timestep, B is batch_size A is agent_num, N is obs_shape.global_state (
torch.Tensor): \((T, B, M)\), where M is global_obs_shape.prev_state (
list): math:(T, B, A), a list of length B, and each element is a list of length A.action (
torch.Tensor): \((T, B, A)\).total_q (
torch.Tensor): \((T, B)\).agent_q (
torch.Tensor): \((T, B, A, P)\), where P is action_shape.next_state (
list): math:(T, B, A), a list of length B, and each element is a list of length A.
Benchmark¶
The Benchmark result of WQMIX in SMAC (Samvelyan et al. 2019), for StarCraft micromanagement problems, implemented in DI-engine is shown.
smac map |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
MMM |
1.00 |
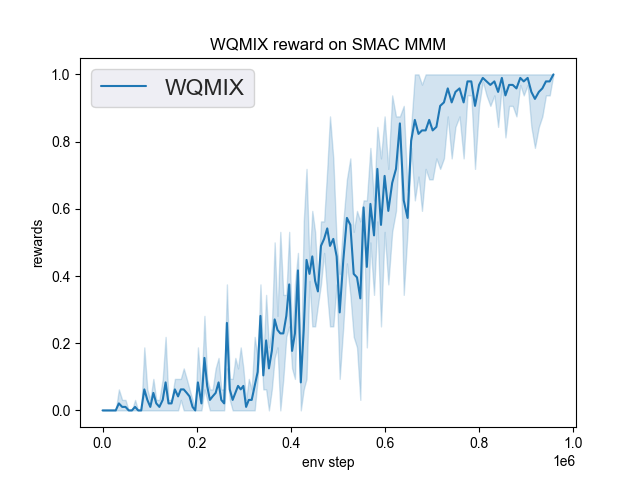
|
wqmix(Tabish) (1.0) |
|
3s5z |
0.72 |
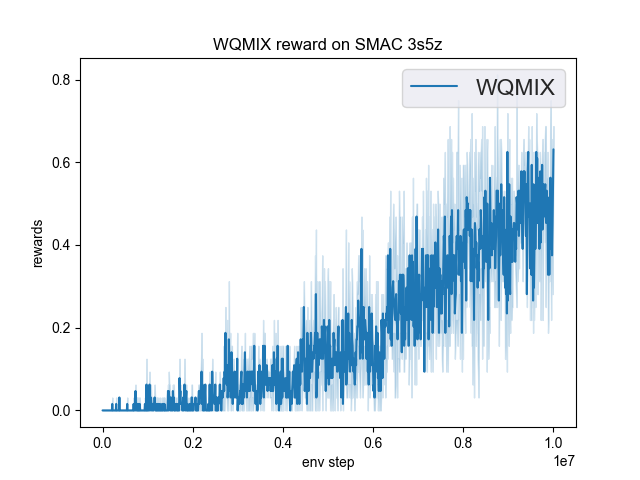
|
wqmix(Tabish) (0.94) |
|
5m6m |
0.45 |
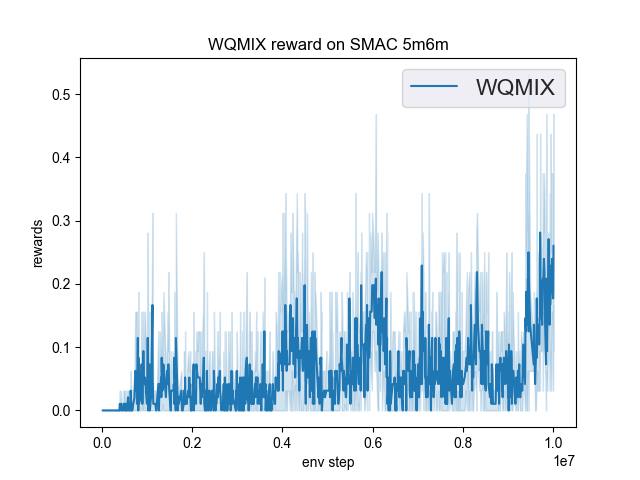
|
wqmix(Tabish) (0.9) |
References¶
Rashid, Tabish, et al. “Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning.” arXiv preprint arXiv:2006.10800 (2020).
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder de Witt, Gregory Farquhar, Jakob Foerster, Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. International Conference on Machine Learning. PMLR, 2018.
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, Thore Graepel. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017.
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, Yung Yi. QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning. International Conference on Machine Learning. PMLR, 2019.
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, Shimon Whiteson. The StarCraft Multi-Agent Challenge. arXiv preprint arXiv:1902.04043, 2019.