Atari¶
概述¶
Atari是最经典最常用的离散动作空间强化学习环境,常作为离散动作空间强化学习算法的基准测试环境。它是一个由 57 个子环境构成的集合,不同的子环境对应的游戏类型差别很大,常用的子环境有 Pong,SpaceInvaders,QBert,Enduro,Breakout,MontezumaRevenge 等等,下图所示为其中的 SpaceInvaders 游戏。

安装¶
安装方法¶
安装 gym 和 ale-py 两个库即可,可以通过 pip 一键安装或结合 DI-engine 安装
注:atari-py 库目前已被开发者废弃,建议使用ale-py
# Method1: Install Directly
pip install gym
pip install ale-py
pip install autorom
autorom --accept-license
# Method2: Install with DI-engine requirements
cd DI-engine
pip install ".[common_env]"
验证安装¶
安装完成后,运行如下 Python 程序,如果没有报错则证明安装成功。
import gym
env = gym.make('Breakout-v0')
obs = env.reset()
print(obs.shape) # (210, 160, 3)
镜像¶
DI-engine 准备好了配备有框架本身和 Atari 环境的镜像,可通过docker pull opendilab/ding:nightly-atari获取,或访问docker
hub获取更多镜像
变换前的空间(原始环境)¶
观察空间¶
实际的游戏画面,RGB 三通道图片,具体尺寸为
(210, 160, 3),数据类型为uint8
动作空间¶
游戏操作按键空间,一般是大小为 N 的离散动作空间(N 随具体子环境变化),数据类型为
int,需要传入 python 数值(或是 0 维 np 数组,例如动作 3 为np.array(3))如在 Pong 环境中,N 的大小为 6,即动作在 0-5 中取值,具体的含义是:
0:NOOP
1:UP
2:LEFT
3:RIGHT
4:DOWN
5:FIRE
奖励空间¶
游戏得分,根据具体游戏内容不同会有非常大的差异,一般是一个
float数值,具体的数值可以参考最下方的基准算法性能部分。
其他¶
游戏结束即为当前环境 episode 结束
关键事实¶
2D RGB 三通道图像输入,但单帧图像蕴含的信息不足(比如运动方向),需要堆叠多帧图像来解决
离散动作空间
Atari 环境集合中的奖励类型比较复杂,既有稠密奖励 (SpaceInvaders),又有稀疏奖励 (Pitfall, MontezumaRevenge),需要的算法探索能力也不同
奖励取值尺度变化较大
变换后的空间(RL 环境)¶
观察空间¶
变换内容:灰度图,空间尺寸缩放,最大最小值归一化,堆叠相邻 N 个游戏帧(N=4)
变换结果:三维 np 数组,尺寸为
(4, 84, 84),即为相邻的 4 帧灰度图,数据类型为np.float32,取值为[0, 1]
动作空间¶
基本无变换,依然是大小为 N 的离散动作空间,但一般为一维 np 数组,尺寸为
(1, ),数据类型为np.int64
奖励空间¶
变换内容:奖励缩放和截断
变换结果:一维 np 数组,尺寸为
(1, ),数据类型为np.float32,取值为[-1, 1]
上述空间使用 gym 环境空间定义则可表示为:
import gym
obs_space = gym.spaces.Box(low=0, high=1, shape=(4, 84, 84), dtype=np.float32)
act_space = gym.spaces.Discrete(6)
rew_space = gym.spaces.Box(low=-1, high=1, shape=(1, ), dtype=np.float32)
其他¶
epsiode_life:训练时的环境使用episode_life选项,即环境拥有多条生命值(一般为 5),原始环境游戏失败一次生命值减一,所有生命值耗尽才视为 episode 结束noop_reset:环境重置时,最开始设置 x 个原始游戏帧 ( 1 =< x <=30) 执行空动作(noop),以增加环境开局的随机性环境
step方法返回的info必须包含eval_episode_return键值对,表示整个 episode 的评测指标,在Atari中为整个episode的奖励累加和
其他¶
惰性初始化¶
为了便于支持环境向量化等并行操作,环境实例一般实现惰性初始化,即__init__方法不初始化真正的原始环境实例,只是设置相关参数和配置值,在第一次调用reset方法时初始化具体的原始环境实例。
随机种子¶
环境中有两部分随机种子需要设置,一是原始环境的随机种子,二是各种环境变换使用到的随机库的随机种子(例如
random,np.random)对于环境调用者,只需通过环境的
seed方法进行设置这两个种子,无需关心具体实现细节环境内部的具体实现:对于原始环境的种子,在调用环境的
reset方法内部,具体的原始环境reset之前设置环境内部的具体实现:对于随机库种子,则在环境的
seed方法中直接设置该值
训练和测试环境的区别¶
训练环境使用动态随机种子,即每个 episode 的随机种子都不同,都是由一个随机数发生器产生,但这个随机数发生器的种子是通过环境的
seed方法固定的;测试环境使用静态随机种子,即每个 episode 的随机种子相同,通过seed方法指定。训练环境和测试环境使用的环境预处理 wrapper 不同,
episode_life和clip_reward在测试时不使用。
存储录像¶
在环境创建之后,重置之前,调用enable_save_replay方法,指定游戏录像保存的路径。环境会在每个 episode 结束之后自动保存本局的录像文件。(默认调用gym.wrappers.RecordVideo实现 ),下面所示的代码将运行一个环境 episode,并将这个 episode 的结果保存在./video/中:
from easydict import EasyDict
from dizoo.atari.envs import AtariEnv
env = AtariEnv(EasyDict({'env_id': 'Breakout-v0', 'is_train': False}))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo 可运行代码示例¶
完整的训练配置文件在 github
link
内,对于具体的配置文件,例如pong_dqn_config.py,使用如下的 demo 即可运行:
from easydict import EasyDict
pong_dqn_config = dict(
env=dict(
collector_env_num=8,
evaluator_env_num=8,
n_evaluator_episode=8,
stop_value=20,
env_id='PongNoFrameskip-v4',
frame_stack=4,
),
policy=dict(
cuda=True,
priority=False,
model=dict(
obs_shape=[4, 84, 84],
action_shape=6,
encoder_hidden_size_list=[128, 128, 512],
),
nstep=3,
discount_factor=0.99,
learn=dict(
update_per_collect=10,
batch_size=32,
learning_rate=0.0001,
target_update_freq=500,
),
collect=dict(n_sample=96, ),
eval=dict(evaluator=dict(eval_freq=4000, )),
other=dict(
eps=dict(
type='exp',
start=1.,
end=0.05,
decay=250000,
),
replay_buffer=dict(replay_buffer_size=100000, ),
),
),
)
pong_dqn_config = EasyDict(pong_dqn_config)
main_config = pong_dqn_config
pong_dqn_create_config = dict(
env=dict(
type='atari',
import_names=['dizoo.atari.envs.atari_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(type='dqn'),
)
pong_dqn_create_config = EasyDict(pong_dqn_create_config)
create_config = pong_dqn_create_config
if __name__ == '__main__':
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
注:对于某些特殊的算法,比如 PPG,需要使用专门的入口函数,示例可以参考 link
基准算法性能¶
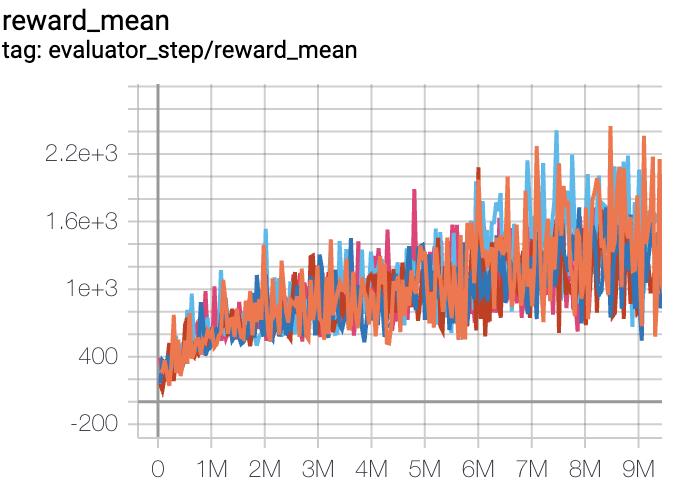
Pong(平均奖励大于等于 20 视为较好的 Agent)
Pong + DQN
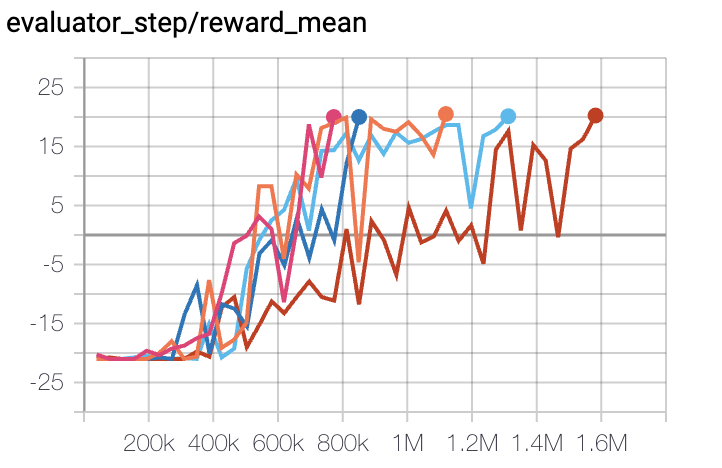
Qbert(10M env step 下,平均奖励大于 15000)
Qbert + DQN
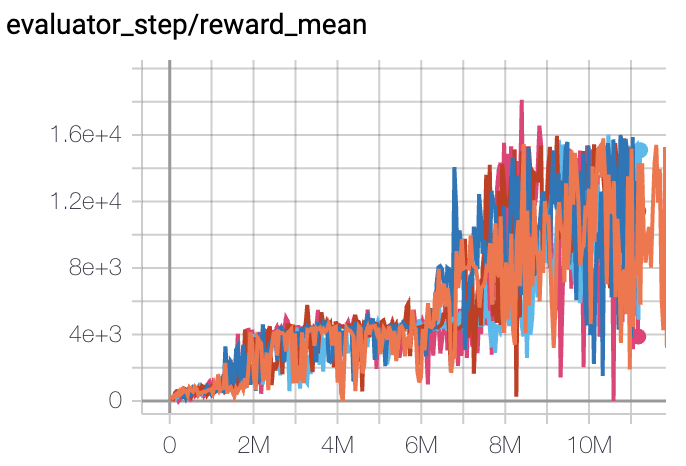
Space Invaders(10M env step 下,平均奖励大于 1000)
Space Invaders + DQN