BitFlip¶
Overview¶
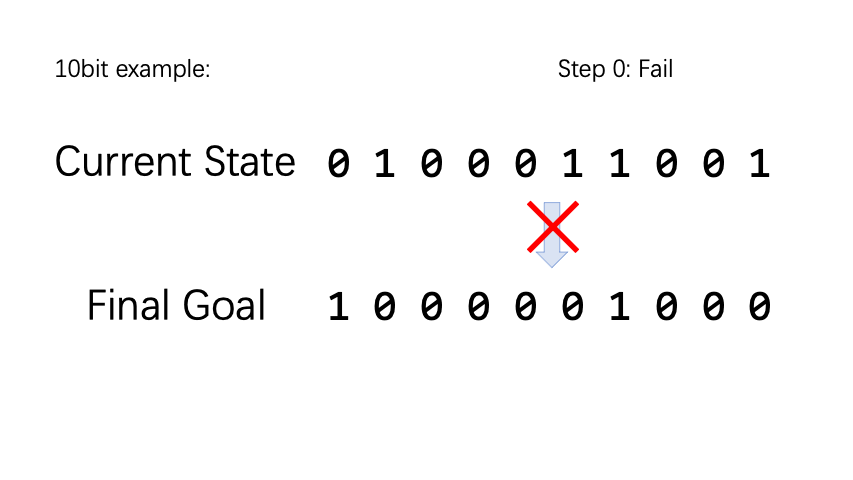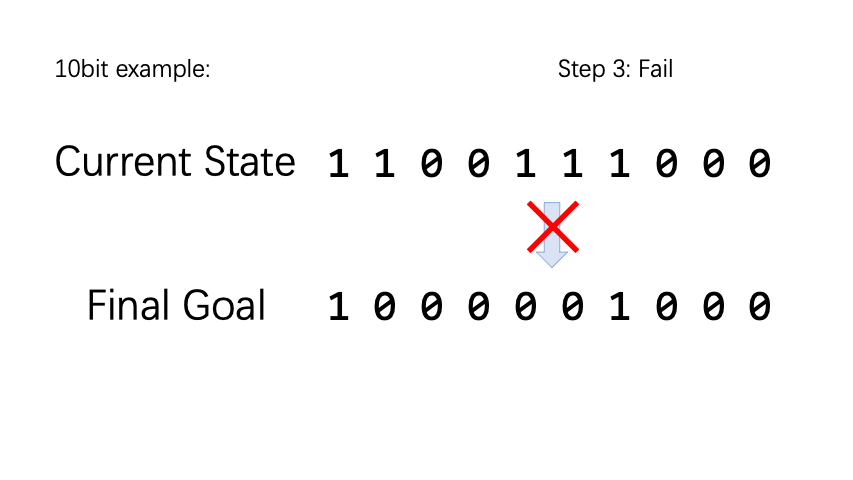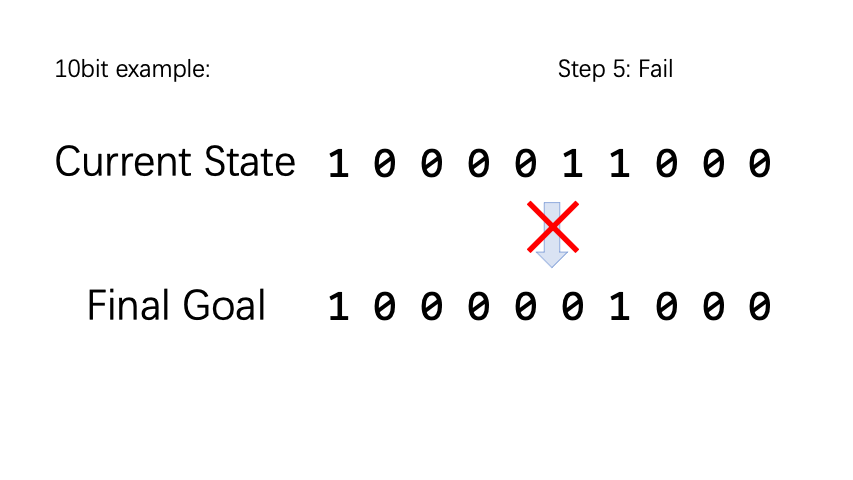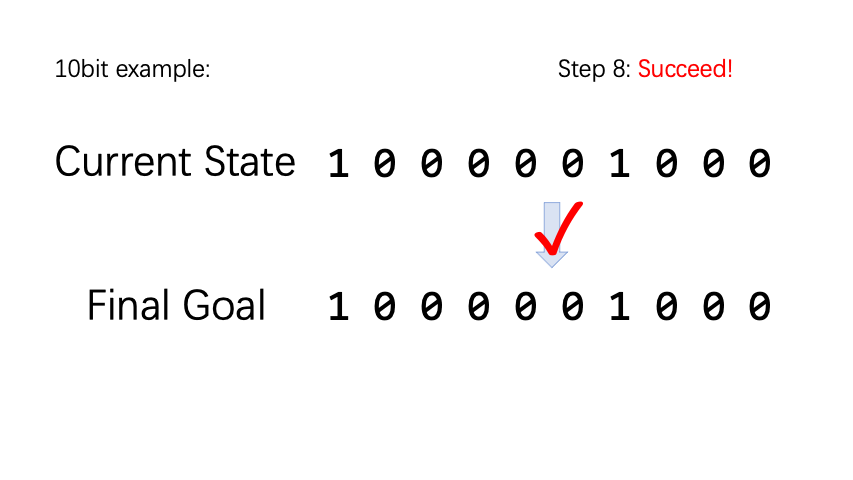
BitFlip is a very simple little game. Assuming there are n coins, each coin has two states, the positive side is denoted as 0 and the negative side is denoted as 1. The action space is a vector of length n, and executing the nth action type represents flipping the nth coin. For each episode, we randomly initialize the coin state and target state. If the coin state and the target state are not the same, the reward is -1, otherwise it is 1.
Installation¶
Installation Method¶
The BitFlip environment does not need to be installed, it is built into DI-engine.
Runnable Code Example in DI-zoo¶
Below is a complete RL training pipeline for Bitflip environment, which uses the DQN algorithm as the policy. Please run the “bitflip_dqn_main.py” file in the “DI-enginedizooclassic_controlbitflipentry” directory as follows.
import os
import gym
from tensorboardX import SummaryWriter
from easydict import EasyDict
from functools import partial
from ding.config import compile_config
from ding.worker import BaseLearner, EpisodeSerialCollector, InteractionSerialEvaluator, EpisodeReplayBuffer
from ding.envs import BaseEnvManager, DingEnvWrapper
from ding.policy import DQNPolicy
from ding.model import DQN
from ding.utils import set_pkg_seed
from ding.rl_utils import get_epsilon_greedy_fn
from ding.reward_model import HerRewardModel
from dizoo.classic_control.bitflip.envs import BitFlipEnv
from dizoo.classic_control.bitflip.config import bitflip_pure_dqn_config, bitflip_her_dqn_config
def main(cfg, seed=0, max_iterations=int(1e8)):
cfg = compile_config(
cfg,
BaseEnvManager,
DQNPolicy,
BaseLearner,
EpisodeSerialCollector,
InteractionSerialEvaluator,
EpisodeReplayBuffer,
save_cfg=True
)
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env = BaseEnvManager(
env_fn=[partial(BitFlipEnv, cfg=cfg.env) for _ in range(collector_env_num)], cfg=cfg.env.manager
)
evaluator_env = BaseEnvManager(
env_fn=[partial(BitFlipEnv, cfg=cfg.env) for _ in range(evaluator_env_num)], cfg=cfg.env.manager
)
# Set random seed for all package and instance
collector_env.seed(seed)
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
# Set up RL Policy
model = DQN(**cfg.policy.model)
policy = DQNPolicy(cfg.policy, model=model)
# Set up collection, training and evaluation utilities
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
learner = BaseLearner(cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name)
collector = EpisodeSerialCollector(
cfg.policy.collect.collector, collector_env, policy.collect_mode, tb_logger, exp_name=cfg.exp_name
)
evaluator = InteractionSerialEvaluator(
cfg.policy.eval.evaluator, evaluator_env, policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
replay_buffer = EpisodeReplayBuffer(
cfg.policy.other.replay_buffer, exp_name=cfg.exp_name, instance_name='episode_buffer'
)
# Set up other modules, etc. epsilon greedy, hindsight experience replay
eps_cfg = cfg.policy.other.eps
epsilon_greedy = get_epsilon_greedy_fn(eps_cfg.start, eps_cfg.end, eps_cfg.decay, eps_cfg.type)
her_cfg = cfg.policy.other.get('her', None)
if her_cfg is not None:
her_model = HerRewardModel(her_cfg, cfg.policy.cuda)
# Training & Evaluation loop
for _ in range(max_iterations):
# Evaluating at the beginning and with specific frequency
if evaluator.should_eval(learner.train_iter):
stop, reward = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop:
break
# Update other modules
eps = epsilon_greedy(collector.envstep)
# Sampling data from environments
new_episode = collector.collect(train_iter=learner.train_iter, policy_kwargs={'eps': eps})
replay_buffer.push(new_episode, cur_collector_envstep=collector.envstep)
# Training
for i in range(cfg.policy.learn.update_per_collect):
if her_cfg and her_model.episode_size is not None:
sample_size = her_model.episode_size
else:
sample_size = learner.policy.get_attribute('batch_size')
train_episode = replay_buffer.sample(sample_size, learner.train_iter)
if train_episode is None:
break
train_data = []
if her_cfg is not None:
her_episodes = []
for e in train_episode:
her_episodes.extend(her_model.estimate(e))
for e in her_episodes:
train_data.extend(policy.collect_mode.get_train_sample(e))
learner.train(train_data, collector.envstep)
if __name__ == "__main__":
# main(bitflip_pure_dqn_config)
main(bitflip_her_dqn_config)
Reference¶
BitFlip source code