Evogym¶
概述¶
Evolution Gym(Evogym)是第一个用于共同优化软体机器人设计和控制的大规模基准。每个机器人都由不同类型的体素(如软体、硬体、执行器)组成,从而形成了一个模块化和富有表现力的机器人设计空间。该环境跨越了广泛的任务范围,包括在各种类型的地形上进行运动和操纵。 下面的图片显示了一个正在行动的机器人。
安装¶
安装方法¶
Evogym 环境可以从 GitHub 下载并使用 pip 安装。 鉴于安装过程可能会因操作系统而有一些不同,遇到任何问题可以查看原始仓库中的说明。
git clone --recurse-submodules https://github.com/EvolutionGym/evogym.git
cd evogym
pip install -r requirements.txt
python setup.py install
验证安装¶
安装完成以后,运行如下命令,如果没有报错则证明安装成功。
python gym_test.py
变换前的空间(原始环境)¶
观察空间¶
观察空间包括机器人的状态信息,一个包括每个四边形体素的顶点相对于机器人
(2N)质心的相对位置的矢量(2N + 3),以及质心的速度和方向(3)。数据类型是float32。为了处理复杂的任务,特别是那些具有不同地形类型的任务,提供了一个包括地形信息的额外观察向量。
此外,提供与目标相关的信息,以告知控制器当前任务的执行状态。
例如,在操纵任务中,机器人与一些物体O互动时,获得了方向和速度,以及O的质心相对于机器人的位置。
动作空间¶
动作空间是大小为 N 的连续动作空间。动作向量的每个分量都与机器人的一个执行器体素(水平或垂直)相关联,并指示该体素的变形目标,将体素的大小从60%压缩或拉伸到160%。数据类型是
float。具体来说,行动值
u是在[0.6, 1.6]范围内,相当于该执行器逐渐膨胀/收缩到其静止长度的u倍。
奖励空间¶
每个任务都配备了一个奖励函数,衡量机器人当前的控制行动的性能。一般来说,它是一个
float值。
关键事实¶
连续观察空间根据机器人的结构、任务和环境而变化。
依据机器人结构的连续工作空间。
所学到的性能最好的策略不仅可以用来控制机器人,而且还有利于为特定任务创造更好的机器人设计。
其他¶
机器人和环境的定义¶
Evogym提供固定的任务,但你可以自定义你自己的机器人结构和环境。 具体的例子,你可以参考以下内容 json file 以及官方 文档.
惰性初始化¶
为了支持环境矢量化等并行操作,环境实例一般都实现了惰性初始化,也就是说,__init__ 方法并不初始化真正的原始环境实例,而只是设置相关参数和配置值。在第一个调用中, reset方法初始化了具体的原始环境实例。
随机种子¶
环境中的随机种子有两部分需要设置,一部分是原始环境的随机种子,另一部分是各种环境转换所使用的随机库的随机种子(如:
random,np.random)。对于环境调用者来说,只需通过环境的
seed方法设置这两个种子,不需要关心具体的实现细节环境内部的具体实现:对于原始环境的种子,在调用环境的
reset方法内部,具体的原始环境reset之前设置。Concrete implementation inside the environment: For random library seeds, the value is set directly in the
seedmethod of the environment环境内部的具体实现:对于随机库的种子,则在环境的
reset方法中直接设置该值。
训练和测试环境的区别¶
训练环境使用动态随机种子,即每个episode的随机种子都不同,都是由一个随机数发生器生成,但这个随机数发生器的种子是由环境的
seed方法固定的;测试环境使用静态随机种子,即每个 episode 的随机种子是相同的,由seed方法指定。
存储录像¶
在环境创建之后,重置之前调用 enable_save_replay 方法,指定游戏录像保存的路径。环境将在每个 episode 结束后自动保存本地视频文件。(默认调用 gym.wrappers.RecordVideo 实现),下面所示的代码将运行一个环境 episode,并将这个 episode 的结果保存在一个文件夹 ./video/里。
import time
import gym
from evogym import sample_robot
# import envs from the envs folder and register them
import evogym.envs
if __name__ == '__main__':
# create a random robot
body, connections = sample_robot((5, 5))
env = gym.make('Walker-v0', body=body)
if gym.version.VERSION > '0.22.0':
env.metadata.update({'render_modes': ["rgb_array"]})
else:
env.metadata.update({'render.modes': ["rgb_array"]})
env = gym.wrappers.RecordVideo(
env,
video_folder="./video",
episode_trigger=lambda episode_id: True,
name_prefix='rl-video-{}'.format(time.time())
)
env.reset()
# step the environment for 100 iterations
for i in range(100):
action = env.action_space.sample()
ob, reward, done, info = env.step(action)
x = env.render()
if done:
env.reset()
env.close()
DI-zoo 可运行代码示例¶
完整的训练配置文件在 github
link
里面, 对于具体的配置文件,例如 walker_ppo_config.py , 使用如下的 demo 即可运行:
from easydict import EasyDict
walker_ppo_config = dict(
exp_name='evogym_walker_ppo_seed0',
env=dict(
env_id='Walker-v0',
robot='speed_bot',
robot_dir='./dizoo/evogym/envs',
collector_env_num=1,
evaluator_env_num=1,
n_evaluator_episode=1,
stop_value=10,
manager=dict(shared_memory=True, ),
# The path to save the game replay
# replay_path='./evogym_walker_ppo_seed0/video',
),
policy=dict(
cuda=True,
recompute_adv=True,
# load_path="./evogym_walker_ppo_seed0/ckpt/ckpt_best.pth.tar",
model=dict(
obs_shape=58,
action_shape=10,
action_space='continuous',
),
action_space='continuous',
learn=dict(
epoch_per_collect=10,
batch_size=256,
learning_rate=3e-4,
value_weight=0.5,
entropy_weight=0.0,
clip_ratio=0.2,
adv_norm=True,
value_norm=True,
),
collect=dict(
n_sample=2048,
gae_lambda=0.97,
),
eval=dict(evaluator=dict(eval_freq=5000, )),
)
)
walker_ppo_config = EasyDict(walker_ppo_config)
main_config = walker_ppo_config
walker_ppo_create_config = dict(
env=dict(
type='evogym',
import_names=['dizoo.evogym.envs.evogym_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(
type='ppo',
import_names=['ding.policy.ppo'],
),
replay_buffer=dict(type='naive', ),
)
walker_ppo_create_config = EasyDict(walker_ppo_create_config)
create_config = walker_ppo_create_config
if __name__ == "__main__":
# or you can enter `ding -m serial -c evogym_walker_ppo_config.py -s 0 --env-step 1e7`
from ding.entry import serial_pipeline_onpolicy
serial_pipeline_onpolicy((main_config, create_config), seed=0)
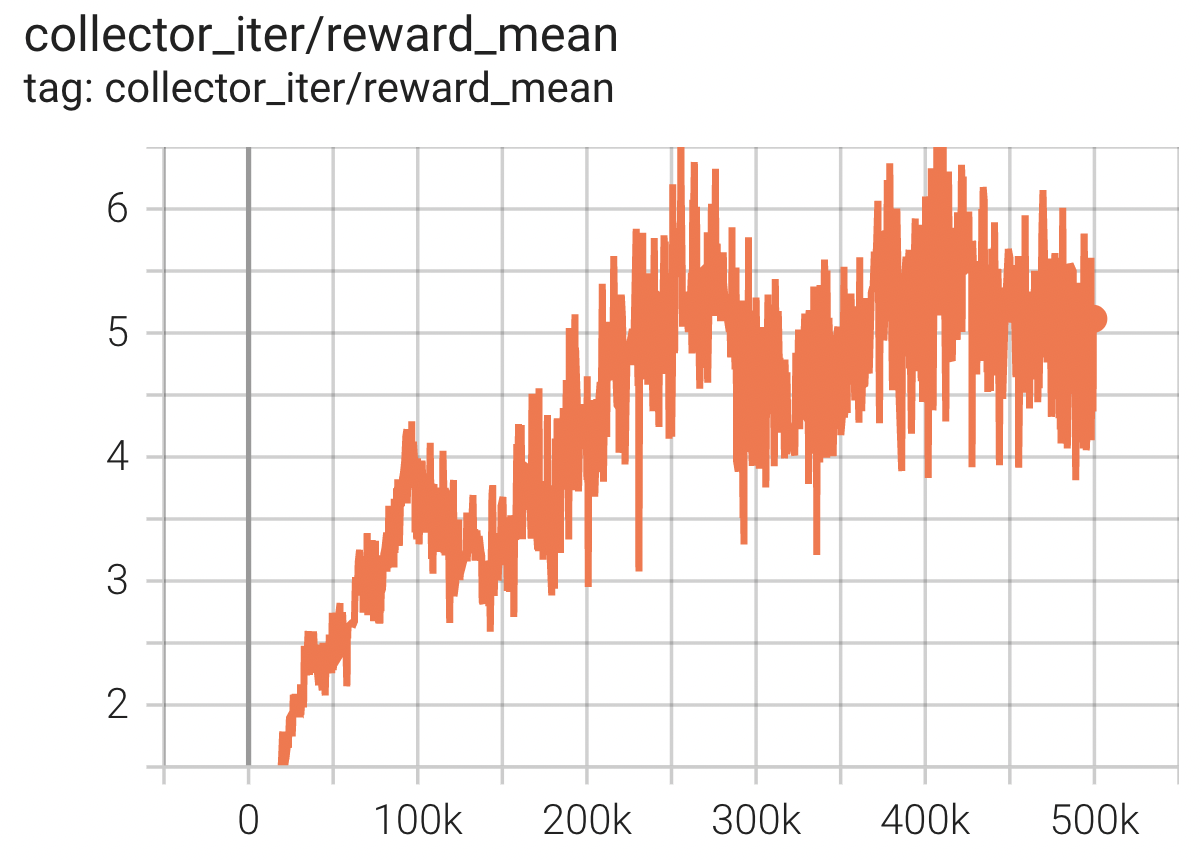
基准算法性能¶
Carrier
任务描述:机器人接住上面初始化的盒子,并尽可能地把它带到远处而不摔落,携带的距离越远奖励越大。。
Carrier + PPO