LunarLander¶
概述¶
LunarLander Env ,即月球着陆器,该环境模拟了一个经典的火箭弹道优化问题。 游戏的目标是通过控制一个着陆器的油门使其飞行并登陆到指定的地点: 着陆台(landing pad)。 该环境具有离散动作空间和连续动作空间两个版本,除了动作空间不同其他基本类似,以下主要以离散动作空间版本为例展开介绍。

安装¶
安装方法¶
安装 gym 和 Box2d 两个库即可, 用户可以选择通过 pip 一键安装
注:如果用户没有 root 权限,请在 install 的命令后面加上 --user
# Install Directly
pip install gym
pip install Box2D
验证安装¶
安装完成后,可以通过在 Python 命令行中运行如下命令验证是否安装成功:
import gym
env = gym.make('LunarLander-v2')
obs = env.reset()
print(obs.shape) # 输出 (8,)
env = gym.make('LunarLanderContinuous-v2')
obs = env.reset()
print(obs.shape) # 输出 (8,)
镜像¶
DI-engine 的镜像包含 DI-engine 框架本身和 Lunarlander 等环境,可通过docker pull opendilab/ding:nightly 获取,
或访问docker hub获取更多镜像。
变换前的空间(原始环境)¶
具体细节,可以参考 gym 的 lunar_lander 代码实现 LunarLander.
观察空间¶
着陆器的观察空间为8维的 numpy 数组,数据类型为 float32, obs shape 为 (8,), 其中每维的物理含义及其范围为:
s[0] 是横坐标,范围为[-1.5, 1.5]
s[1] 是纵坐标,范围为[-1.5, 1.5]
s[2] 是水平速度,范围为[-5, 5]
s[3] 是垂直速度,范围为[-5, 5]
s[4] 是角度,即与正y轴的角度,向右为正,相左为负,以弧度为单位,范围为[-3.14, 3.14]
s[5] 是角速度,顺时针为正,逆时针为负,范围为[-5, 5]
s[6] 如果左脚着陆, 此值为1, 否则为0,范围为{0,1}
s[7] 如果右脚着陆, 此值为1, 否则为0,范围为{0,1}
着陆初始时刻的随机性:着陆器从屏幕的顶部中心开始,会有一个 随机初始力 应用于其质心, 保证不同 seed 下的初始状态中的水平速度,垂直速度, 角度和角速度不同。 同时,会根据采样的 随机数 决定月球地形的分布情况。
着陆过程中的随机性:在着陆器的动力学方程中存在一个 随机分散力(dispersion) 保证不同 seed 下的环境转移函数不同。
除此之外,在定义环境时,还可以通过下面的方式指定额外的随机性:
import gym
env = gym.make(
"LunarLander-v2",
continuous: bool = False,
gravity: float = -10.0,
enable_wind: bool = False,
wind_power: float = 15.0,
turbulence_power: float = 1.5,
)
其中 gravity 指定了引力常数,它被限制在 0 到 -12 之间。 如果设置了 enable_wind=True,着陆器下降过程中就会有风的影响。 使用函数 \(tanh(sin(2 k (t+C)) + sin(pi k (t+C)))\) 生成风的大小。 k 设置为固定的 0.01。 C 在 -9999 和 9999 之间随机采样。 wind_power 指定施加到飞行器的线性风的最大幅度。 wind_power 的推荐值为 0.0 和 20.0 之间。turbulence_power 指定施加到飞行器的旋转风的最大幅度。 turbulence_power 的推荐值为 0.0 和 2.0 之间。
动作空间¶
离散动作空间版本 ‘LunarLander-v2’ 的动作空间是大小为4的离散动作空间,数据类型为
int,取值范围为{0,1,2,3},具体的含义是:0:什么都不做
1:启动左方向引擎
2:启动主引擎 (纵向引擎)
3:启动右方向引擎
连续动作空间版本 ‘LunarLandeContinuous-v2’ 的动作空间是2维连续动作空间, (a1, a2),a1决定主引擎(纵向引擎)的油门,a2决定横向引擎的油门, 数据类型为
float,取值范围为[-1, 1],具体的含义是:如果 a1<0 主引擎将完全关闭, 如果0 <= a1 <= 1, 主引擎打开。(0,1)对应主引擎的油门强度从 50% 变化到 100%。
如果 -0.5 < a2 < 0.5,横向引擎不会启动。 如果 a2 < -0.5, 左方向引擎将启动,如果 a2 > 0.5,右方向引擎将启动。 (-1, -0.5)和(0.5, 1)分别对应左方向引擎和 和右方向引擎的油门强度从 50% 变化到 100%
奖励空间¶
着陆器每一步都会获得奖励,奖励是一个 int 数值, 一局的总奖励是该局中所有时间步上的奖励总和。
其中每一步的奖励的定义方式为:
着陆器离着陆台(landing pad)越近,奖励越大。
着陆器移动速度越慢,奖励越大。
着陆器倾斜得越少(即 obs 中的角度越接近于0),奖励越大。
每有一条腿与地面接触,增加 10 分。
横向引擎每点火一次减少 0.03 分。
纵向(主)引擎每点火一次减少 0.3 分。
着陆器从屏幕顶部移动到月球的表面上的奖励和约为 100-140 分。 特别注意的是,在着陆器安全降落到着陆台时,可以得到 +100 分的奖励,而坠毁则会得到 -100 分的奖励。 综上所述,如果一局的奖励总和大于 200 分,则该局可以当做一次成功的着陆实验。
其他¶
如果出现以下情况,则判定 episode 结束:
着陆器坠毁(着陆器主体与月球接触)
着陆器超出观察窗口(横坐标大于1)
着陆器安全着陆并处于静止状态
变换后的空间(RL 环境)¶
观察空间¶
无变化
动作空间¶
对于离散动作空间版本 ‘LunarLander-v2’, 依然是大小为 4 的离散动作空间,但数据类型由
int转为np.int64, 尺寸为( ), 即 0-dim 的 array对于连续动作空间版本 ‘LunarLandeContinuous-v2’ ,依然是大小为2维的连续动作空间, 但数据类型由
float转为np.float32, 尺寸为(2 ), 即 2-dim 的 array
奖励空间¶
变换内容:数据结构变换
变换结果:变为 numpy 数组,尺寸为
(1, ),数据类型为np.float64
上述空间使用 gym 环境的空间定义可表示为:
import gym
obs_space = gym.spaces.spaces.Box(-np.inf, np.inf, shape=(8,), dtype=np.float32)
act_space = gym.spaces.Discrete(4)
其他¶
环境
step方法返回的info必须包含eval_episode_return键值对,表示整个 episode 的评测指标,在 lunarlander 中为整个 episode 的奖励累加和
其他¶
惰性初始化¶
为了便于支持环境向量化等并行操作,具体的环境实例一般采用惰性初始化的方法,即在环境的__init__方法不初始化真正的原始环境实例,只是设置相关参数和配置值,
而在第一次调用reset方法时初始化具体的原始环境实例。
随机种子¶
环境中有两部分随机种子需要设置,一是原始环境的随机种子,二是各种环境变换使用到的随机库的随机种子(例如
random,np.random)对于环境调用者,只需通过环境的
seed方法设置这两个种子,而无需关心具体实现细节环境内部的具体实现为:
对于随机库种子,在环境的
seed方法中直接设置该值- 对于原始环境的种子,在调用环境的
reset方法内部,具体的原始环境reset之前设置为 seed + np_seed, 其中 seed 为前述的随机库种子的值, 而np_seed = 100 * np.random.randint(1, 1000)。
- 对于原始环境的种子,在调用环境的
训练和测试环境的区别¶
训练环境使用动态随机种子,即每个 episode 的随机种子都不同,都是由一个随机数发生器产生,但这个随机数发生器的种子是通过环境的
seed方法固定的。测试环境使用静态随机种子,即每个 episode 的随机种子相同,通过
seed方法指定。
存储录像¶
在环境创建之后,重置之前,调用enable_save_replay方法,指定游戏录像保存的路径。环境会在每个 episode 结束之后自动保存本局的录像文件。(默认调用gym.wrappers.RecordVideo实现 ),
下面所示的代码将运行一个 episode,并将这个 episode 的结果保存在./video/中:
from easydict import EasyDict
from dizoo.box2d.lunarlander.envs import LunarLanderEnv
env = LunarLanderEnv({})
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo 可运行代码示例¶
各个算法在该环境上的训练配置文件在目录 github
link
里,对于具体的配置文件,例如lunarlander_dqn_config.py,使用如下的 demo 即可运行:
from easydict import EasyDict
from ding.entry import serial_pipeline
nstep = 3
lunarlander_dqn_config = dict(
env=dict(
# Whether to use shared memory. Only effective if "env_manager_type" is 'subprocess'
manager=dict(shared_memory=True, ),
# Env number respectively for collector and evaluator.
collector_env_num=8,
evaluator_env_num=5,
n_evaluator_episode=5,
stop_value=200,
),
policy=dict(
# Whether to use cuda for network.
cuda=False,
model=dict(
obs_shape=8,
action_shape=4,
encoder_hidden_size_list=[512, 64],
# Whether to use dueling head.
dueling=True,
),
# Reward's future discount factor, aka. gamma.
discount_factor=0.99,
# How many steps in td error.
nstep=nstep,
# learn_mode config
learn=dict(
update_per_collect=10,
batch_size=64,
learning_rate=0.001,
# Frequency of target network update.
target_update_freq=100,
),
# collect_mode config
collect=dict(
# You can use either "n_sample" or "n_episode" in collector.collect.
# Get "n_sample" samples per collect.
n_sample=64,
# Cut trajectories into pieces with length "unroll_len".
unroll_len=1,
),
# command_mode config
other=dict(
# Epsilon greedy with decay.
eps=dict(
# Decay type. Support ['exp', 'linear'].
type='exp',
start=0.95,
end=0.1,
decay=50000,
),
replay_buffer=dict(replay_buffer_size=100000, )
),
),
)
lunarlander_dqn_config = EasyDict(lunarlander_dqn_config)
main_config = lunarlander_dqn_config
lunarlander_dqn_create_config = dict(
env=dict(
type='lunarlander',
import_names=['dizoo.box2d.lunarlander.envs.lunarlander_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(type='dqn'),
)
lunarlander_dqn_create_config = EasyDict(lunarlander_dqn_create_config)
create_config = lunarlander_dqn_create_config
if __name__ == "__main__":
serial_pipeline([main_config, create_config], seed=0)
基准算法性能¶
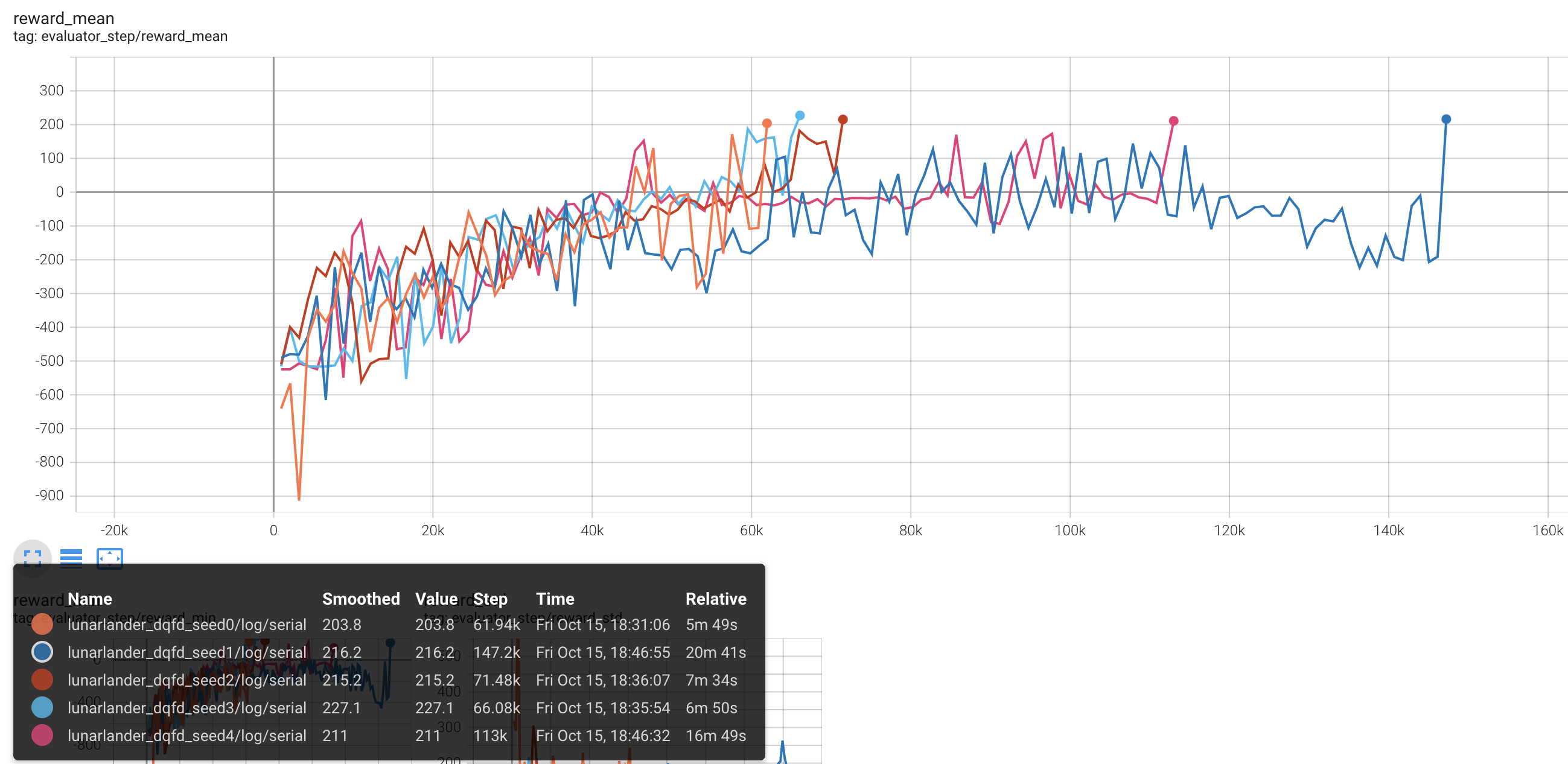
LunarLander(测试局的平均 episode return 大于等于200视为算法收敛到近似最优值)
Lunarlander + DQFD