MiniGrid¶
Overview¶
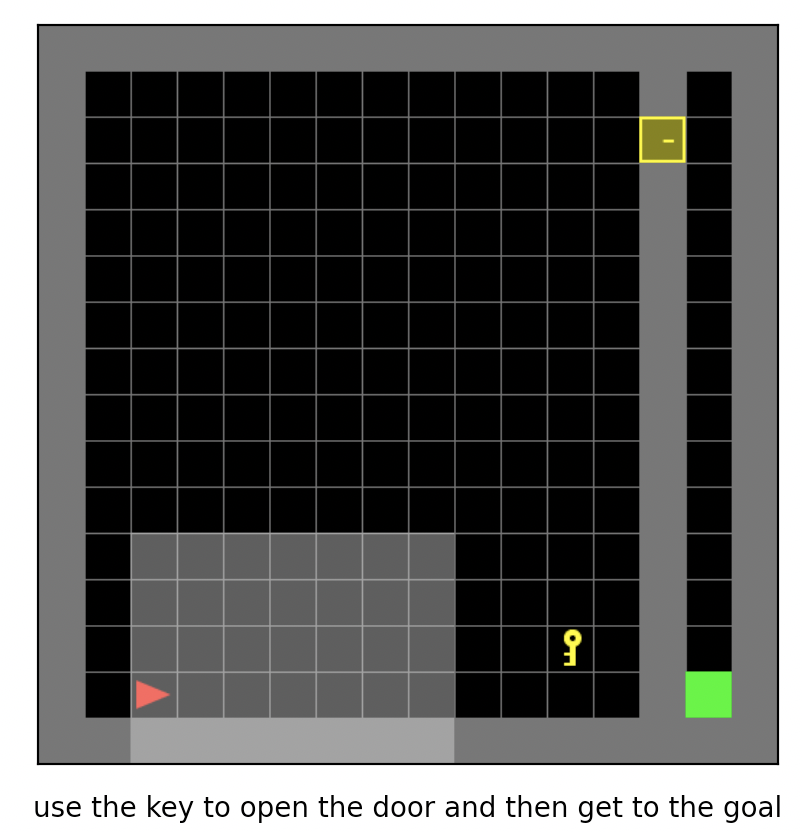
MiniGrid, that is, the minimized grid world environment, is a classic discrete action space reinforcement learning environment with sparse rewards, and is often used as a benchmark test environment for sparse reinforcement learning algorithms under discrete action space conditions. In this game, the agent needs to learn to select the appropriate action in a discrete action set, complete the move in the grid world, obtain the key, open the door and a series of sequential decisions to reach the target position. It has many different implementation versions, which are mainly introduced here MiniGrid, because its implementation is simple, lightweight, less code dependencies, and easy to install. It includes MiniGrid-Empty-8x8-v0, MiniGrid-FourRooms-v0, MiniGrid-DoorKey-16x16-v0, MiniGrid-KeyCorridorS3R3-v0, A series of environments such as MiniGrid-ObstructedMaze-2Dlh-v0, MiniGrid-ObstructedMaze-Full-v0, etc. The picture below shows the MiniGrid-DoorKey-16x16-v0 game.
Install¶
Installation Method¶
Users can choose to install via pip one-click or git clone the repository and then pip install locally.
Note: If the user does not have root privileges, please add –user after the install command
# Method1: Install Directly
pip install gym-minigrid
# Method2: First clone this repository and install the dependencies with pip
git clone https://github.com/maximecb/gym-minigrid.git
cd gym-minigrid
pip install -e .
Verify Installation¶
After the installation is complete, you can run the following command on the Python command line. If the interactive interface of the game is displayed, the installation is successful:
cd gym-minigrid
./manual_contril.py --env MiniGrid-Empty-8x8-v0
Space before Transformation (Original Environment)¶
Observation Space¶
Take MiniGrid-Empty-8x8-v0 as an example,
env = gym.make('MiniGrid-Empty-8x8-v0')
obs1 = env.reset() # obs: {'image': numpy.ndarray (7, 7, 3),'direction': ,'mission': ,}
env = RGBImgPartialObsWrapper(env) # Get pixel observations
obs2 = env.reset() # obs: {'mission': ,'image': numpy.ndarray (56, 56, 3)}
env = ImgObsWrapper(env) # Get rid of the 'mission' field
obs3 = env.reset() # obs: numpy.ndarray (56, 56, 3)
# This FlatObsWrapper cannot be used after using the above Wrapper, it should be used alone
env = gym.make('MiniGrid-Empty-8x8-v0')
env = FlatObsWrapper(env)
obs4 = env.reset() # obs: numpy.ndarray (56, 56, 3)
obs1 is a
dict, includingimage,direction,mission, these 3 fields, of whichimagefield is a shapenumpy.ndarrayof (7, 7, 3), data typeuint8(7, 7) means that only the world in the nearby 7x7 squares is observed (because the environment is partially observable), 3 means that each small square corresponds to a 3-dimensional description vector, note that this is not a real image;The directionfield is to give an instructive direction; Themissionfield is a text string describing what the agent should achieve in order to receive a reward.If the user wants to use the real pixel image, he needs to encapsulate the env through
RGBImgPartialObsWrapper, obs2 is adict, includingmission,imageThese 2 fields, whereimagefield is anumpy.ndarrayof shape (56, 56, 3), and the data type isuint8is a true image of the environment being partially observable;After passing
ImgObsWrapper, obs3 is anumpy.ndarray, shape is (56, 56, 3), data type isuint8Our codebase uses a 4th
FlatObsWrappermethod, which encodes the mission string in themissionfield in a one-hot way, And concatenate it with theimagefield content into anumpy.ndarrayobs4 with shape (2739,) and data typefloat32
Action Space¶
The game operation button space, generally a discrete action space with a size of 7, the data type is
int, you need to pass in a python value (or a 0-dimensional np array, for example, action 3 isnp.array (3))Action takes value in 0-6, the specific meaning is:
0: left
1: right
2: up
3: toggle
4: pickup
5: drop
6: done/noop
Refer to MiniGrid manual_control.py , the keyboard key-action correspondence is:
‘arrow left’: left
‘arrow right’: right
‘arrow up’: up
‘ ‘: toggle
‘pageup’: pickup
‘pagedown’: drop
‘enter’: done/noop
Reward Space¶
Game score, different minigrid sub-environments have a small difference in the reward range, the maximum value is 1, which is generally a
floatvalue. Because it is a sparse reward environment, it can only be reached when the agent (displayed as a red point) reaches goal(displayed as green dots), there is a reward greater than zero. The specific value is determined by different environments and the total number of steps used to reach the goal. The reward before reaching the goal is all 0.
Other¶
The game ends when the agent reaches the green goal or reaches the maximum step limit of the environment.
Key Facts¶
The observation input can be an image in the form of pixels or an “image” with specific semantics, or a textual string describing what the agent should achieve in order to obtain a reward.
Discrete action spaces.
Sparse reward, the scale of reward value changes is small, the maximum is 1, and the minimum is 0.
Transformed Space (RL environment)¶
Observation Space¶
Transform content: Our codebase uses a 4th
FlatObsWrappermethod, which encodes the mission string in themissionfield in a one-hot fashion and combines it withimagefield contents are concatenated into a long arrayTransformation result: one-dimensional np array with size
(2739,), data typenp.float32, value[0., 7.]
Action Space¶
Basically no transformation, it is still a discrete action space of size N=7, generally a one-dimensional np array, the size is
(1, ), and the data type isnp.int64
Reward Space¶
Transform content: basically no transform
The above space can be expressed as:
import gym
obs_space = gym.spaces.Box(low=0, high=5, shape=(2739,), dtype=np.float32)
act_space = gym.spaces.Discrete(7)
rew_space = gym.spaces.Box(low=0, high=1, shape=(1, ), dtype=np.float32)
Other¶
The
inforeturned by the environmentstepmethod must contain theeval_episode_returnkey-value pair, which represents the evaluation index of the entire episode, and is the cumulative sum of the rewards of the entire episode in minigrid
Other¶
Random Seed¶
There are two parts of random seeds in the environment that need to be set, one is the random seed of the original environment, and the other is the random seed of the random library used by various environment transformations (such as
random,np.random)For the environment caller, just set these two seeds through the
seedmethod of the environment, and do not need to care about the specific implementation details- The specific implementation inside the environment: for random library seeds, set the value directly in the
seedmethod of the environment; for the seed of the original environment, inside theresetmethod of the calling environment, The specific original environmentresetwas previously set to seed + np_seed, where seed is the value of the aforementioned random library seed, np_seed = 100 * np.random.randint(1, 1000).
- The specific implementation inside the environment: for random library seeds, set the value directly in the
The difference between training and testing environments¶
The training environment uses a dynamic random seed, that is, the random seed of each episode is different, generated by a random number generator, and the seed of this random number generator is fixed by the
seedmethod of the environment; test The environment uses a static random seed, i.e. the same random seed for each episode, specified by theseedmethod.
Store Video¶
After the environment is created, but before reset, call the enable_save_replaymethod to specify the path to save the game recording. The environment will automatically save the local video files after each episode ends. (The default call gym.wrappers.RecordVideoimplementation), the code shown below will run an environment episode and save the result of this episode in a folder ./video/:
from easydict import EasyDict
import numpy as np
from dizoo.minigrid.envs import MiniGridEnv
env = MiniGridEnv(EasyDict({'env_id': 'MiniGrid-Empty-8x8-v0', 'flat_obs': True}))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
act_val = env.info().act_space.value
min_val, max_val = act_val['min'], act_val['max']
random_action = np.random.randint(min_val, max_val, size=(1,))
timestep = env.step(random_action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo Runnable Code Example¶
The full training configuration file is at github
link
The specific configuration files, such as minigrid_r2d2_config.py, use the following demo to run:
from easydict import EasyDict
from ding.entry import serial_pipeline
collector_env_num = 8
evaluator_env_num = 5
minigrid_r2d2_config = dict(
exp_name='minigrid_empty8_r2d2_n5_bs2_ul40',
env=dict(
collector_env_num=collector_env_num,
evaluator_env_num=evaluator_env_num,
env_id='MiniGrid-Empty-8x8-v0',
# env_id='MiniGrid-FourRooms-v0',
# env_id='MiniGrid-DoorKey-16x16-v0',
n_evaluator_episode=5,
stop_value=0.96,
),
policy=dict(
cuda=True,
on_policy=False,
priority=True,
priority_IS_weight=True,
model=dict(
obs_shape=2739,
action_shape=7,
encoder_hidden_size_list=[128, 128, 512],
),
discount_factor=0.997,
burnin_step=2, # TODO(pu) 20
nstep=5,
# (int) the whole sequence length to unroll the RNN network minus
# the timesteps of burnin part,
# i.e., <the whole sequence length> = <burnin_step> + <unroll_len>
unroll_len=40, # TODO(pu) 80
learn=dict(
# according to the R2D2 paper, actor parameter update interval is 400
# environment timesteps, and in per collect phase, we collect 32 sequence
# samples, the length of each samlpe sequence is <burnin_step> + <unroll_len>,
# which is 100 in our seeing, 32*100/400=8, so we set update_per_collect=8
# in most environments
update_per_collect=8,
batch_size=64,
learning_rate=0.0005,
target_update_theta=0.001,
),
collect=dict(
# NOTE it is important that don't include key n_sample here, to make sure self._traj_len=INF
each_iter_n_sample=32,
env_num=collector_env_num,
),
eval=dict(env_num=evaluator_env_num, ),
other=dict(
eps=dict(
type='exp',
start=0.95,
end=0.05,
decay=1e5,
),
replay_buffer=dict(
replay_buffer_size=100000,
# (Float type) How much prioritization is used: 0 means no prioritization while 1 means full prioritization
alpha=0.6,
# (Float type) How much correction is used: 0 means no correction while 1 means full correction
beta=0.4,
)
),
),
)
minigrid_r2d2_config = EasyDict(minigrid_r2d2_config)
main_config=minigrid_r2d2_config
minigrid_r2d2_create_config = dict(
env=dict(
type='minigrid',
import_names=['dizoo.minigrid.envs.minigrid_env'],
),
env_manager=dict(type='base'),
policy=dict(type='r2d2'),
)
minigrid_r2d2_create_config = EasyDict(minigrid_r2d2_create_config)
create_config=minigrid_r2d2_create_config
if __name__ == "__main__":
serial_pipeline([main_config, create_config], seed=0)
Benchmark Algorithm Performance¶
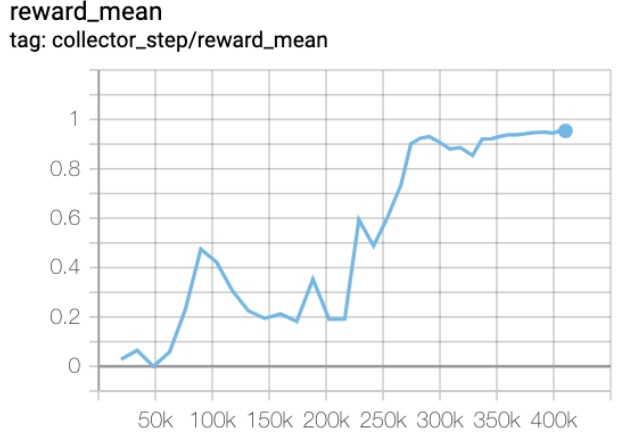
MiniGrid-Empty-8x8-v0 (under 0.5M env step, the average reward is greater than 0.95)
MiniGrid-Empty-8x8-v0+R2D2
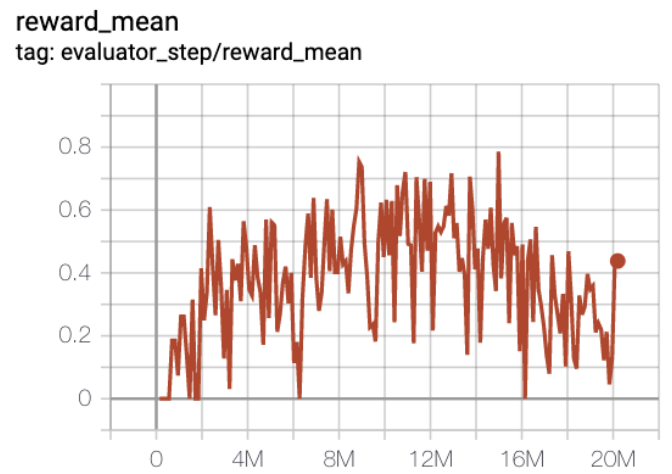
MiniGrid-FourRooms-v0 (under 10M env step, the average reward is greater than 0.6)
MiniGrid-FourRooms-v0 + R2D2
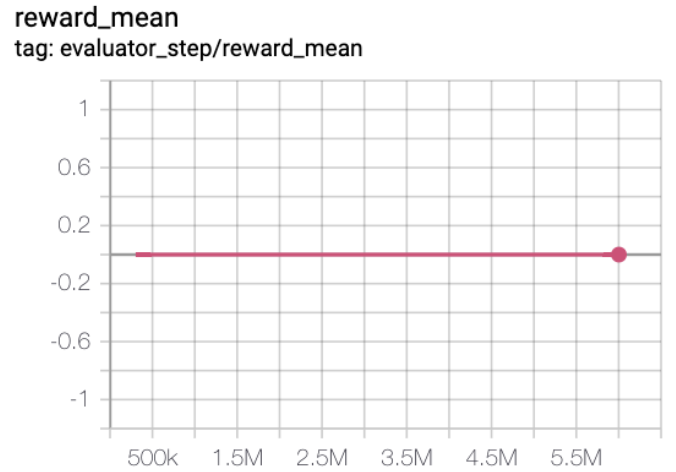
MiniGrid-DoorKey-16x16-v0 (under 20M env step, the average reward is greater than 0.2)
MiniGrid-DoorKey-16x16-v0 + R2D2