Slime Volleyball¶
Overview¶
Slime Volleyball is a two-player match-based environment with two types of observation spaces, vector and picture forms. The action space is often simplified to a discrete action space, used as the basic environment for testing self-play-related algorithms. It is a collection of environments (there are 3 sub-environments, namely SlimeVolley-v0, SlimeVolleyPixel-v0, SlimeVolleyNoFrameskip-v0), of which the SlimeVolley-v0 game is shown in the figure below.
Installation¶
Installation Methods¶
Install slimevolleygym. You can install by command pip or through DI-engine.
# Method1: Install Directly
pip install slimevolleygym
Installation Check¶
After completing installation, you can check whether it is succesful by the following commands:
import gym
import slimevolleygym
env = gym.make("SlimeVolley-v0")
obs = env.reset()
print(obs.shape) # (12, )
DI-engine Mirrors¶
Due to Slime Volleyball is easy to install, DI-engine does not have Mirror specifically for it. You can customize your build with the benchmark Mirror opendilab/ding:nightly, or visit the docker
hub for more mirrors.
Original Environment¶
Note: SlimeVolley-v0 is used here as an example, because benchmarking the self-play series of algorithms naturally gives priority to simplicity. If you want to use the other two environments, you can check the original repository and adapt the environment according to the DI-engine’s API.
Observation Space¶
The observation space is a vector of size
(12, )containing the absolute coordinates of self, opponent, and ball with two consecutive frames stitched togerther. The data type isfloat64i.e. (x_agent, y_agent, x_agent_next, y_agent_next, x_ball, y_ball, x_ball_next, y_ball_next, x_opponent, y_opponent, x_opponent_next, y_opponent_next)
Action Space¶
The original action space of
SlimeVolley-v0is defined asMultiBinary(3)with three kinds of actions. More than one actions can be performed at the same time. Each action is corresponding to two cases: 0 (not executed) and 1 (executed). i.e.(1, 0, 1)represents the execution of the first and third actions at the same time. The data type isint, which needs to be passed into a python list object (or a 1-dimensional np array of size 3, i.e.np.array([0, 1, 0])The actual implementation does not strictly limit the action to 0 and 1. It treats values greater than 0 as 1, while values less than or equal to 0 as 0.
In the
SlimeVolley-v0environment, the basic action is meant to be0: forward (forward)
1: backward (backward)
2: jump (jump)
In the
SlimeVolley-v0environment, the combined action is meant to be[0, 0, 0], NOOP
[1, 0, 0], LEFT (forward)
[1, 0, 1], UPLEFT (forward jump)
[0, 0, 1], UP (jump)
[0, 1, 1], UPRIGHT (backward jump)
[0, 1, 0], RIGHT (backward)
Reward Space¶
The reward is the score of the game. If the ball lands on the ground of your field, -1 is given. If it lands on the ground of the opponent‘s field, +1 is given. If the game is still in progress, 0 is given.
Other¶
The end of the game is represented as the end of episode. There are two ending conditions
The life point of one side is 0, default is 5.
reach the maximum environmental step, default is 3000.
The game supports two kinds of matchmaking, intelligent body against built-in bot (the bot left, the intelligent body right), intelligent body against intelligent body
The built-in bot is a very simple RNN-trained smartbody bot_link
Only one side’s obs are returned by default. The other side’s obs, and information can be found in the
infofield
Key Facts¶
1-dimensional vector observation space (of size (12, )) with information in absolute coordinates
MultiBinaryaction spacesparser rewards (maximum life value of 5, maximum number of steps of 3,000, the reward can be gain only when the life value is deducted)
RL Environment Space¶
Observation Space¶
Transform the space vector into a one-dimensional np array of size
(12, ). The data type isnp.float32.
Action Space¶
Transform the
MultiBinaryaction space into a discrete action space of size 6 (a simple Cartesian product is sufficient). The final result is a one-dimensional np array of size(1, ). The data type isnp.int64
Reward Space¶
Transform the reward vector into a one-dimensional np array of size
(1, ). The data type isnp.float32values in[-1, 0, 1].
Using Slime Volleyball in ‘OpenAI Gym’ format:
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(12, ), dtype=np.float32)
act_space = gym.spaces.Discrete(6)
rew_space = gym.spaces.Box(low=-1, high=1, shape=(1, ), dtype=np.float32)
Other¶
Theinfo`returned form the environment
stepmust contain theeval_episode_returnkey-value pair, which represents the evaluation metrics for the entire episode, containing the rewards for the episode (life value difference between two players).The above spatial definitions are all descriptions of single intelligences. The multi-intelligence space splices the corresponding obs/action/reward information.
i.e. The observation space changes from (12, ) to (2, 12), thar represents the observation information of both sides.
Other¶
Lazy initialization¶
In order to support environment vetorization, an environment instance is oftern initialized lazily. In this way, method __init__ does not really initialize the real original environment, but only set corresponding parameters and configurations. The real original environment is initialized when first calling mdthod reset.
Random Seed¶
There are two random seeds in the environment. One is orignal environment’s random seed; The other is the random seed which is required in many environment space transformations. (e.g.
random,np.random)As a user, you only need to set these two random seeds by calling method
seed, and do not need to care about the implementation details.Implementation details: For orignal environment’s random seed, within RL env’s
resetmethod; Before orginal env’sresetmethod.Implementation details: For the seed for
random/np.random, within env’sseedmethod.
Difference between training env and evaluation env¶
Training env uses dynamic random seed, i.e. Every episode has different random seeds generated by one random generator. However, this random generator’s random seed is set by env’s
seedmethod, and is fixed throughout an experiment. Evaluation env uses static random seed, i.e. Every episode has the same random seed, which is set directly byseedmethod.Training env and evaluation env use different pre-process wrappers.
episode_lifeandclip_rewardare not used in evaluation env.
Save the replay video¶
After env is initiated, and before it is reset, call enable_save_replay method to set where the replay video will be saved. Environment will automatically save the replay video after each episode is completed. (The default call is gym.wrappers.RecordVideo). The code shown below will run an environment episode and save the replay viedo in a folder ./video/.
from easydict import EasyDict
from dizoo.slime_volley.envs.slime_volley_env import SlimeVolleyEnv
env = SlimeVolleyEnv(EasyDict({'env_id': 'SlimeVolley-v0', 'agent_vs_agent': False}))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo runnable code¶
Complete training configuration can be found on github
link.
For specific configuration file, e.g. slime_volley_selfplay_ppo_main.py, you can run the demo as shown below:
import os
import gym
import numpy as np
import copy
import torch
from tensorboardX import SummaryWriter
from functools import partial
from ding.config import compile_config
from ding.worker import BaseLearner, BattleSampleSerialCollector, NaiveReplayBuffer, InteractionSerialEvaluator
from ding.envs import SyncSubprocessEnvManager
from ding.policy import PPOPolicy
from ding.model import VAC
from ding.utils import set_pkg_seed
from dizoo.slime_volley.envs import SlimeVolleyEnv
from dizoo.slime_volley.config.slime_volley_ppo_config import main_config
def main(cfg, seed=0, max_iterations=int(1e10)):
cfg = compile_config(
cfg,
SyncSubprocessEnvManager,
PPOPolicy,
BaseLearner,
BattleSampleSerialCollector,
InteractionSerialEvaluator,
NaiveReplayBuffer,
save_cfg=True
)
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env_cfg = copy.deepcopy(cfg.env)
collector_env_cfg.agent_vs_agent = True
evaluator_env_cfg = copy.deepcopy(cfg.env)
evaluator_env_cfg.agent_vs_agent = False
collector_env = SyncSubprocessEnvManager(
env_fn=[partial(SlimeVolleyEnv, collector_env_cfg) for _ in range(collector_env_num)], cfg=cfg.env.manager
)
evaluator_env = SyncSubprocessEnvManager(
env_fn=[partial(SlimeVolleyEnv, evaluator_env_cfg) for _ in range(evaluator_env_num)], cfg=cfg.env.manager
)
collector_env.seed(seed)
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
model = VAC(**cfg.policy.model)
policy = PPOPolicy(cfg.policy, model=model)
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
learner = BaseLearner(
cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name, instance_name='learner1'
)
collector = BattleSampleSerialCollector(
cfg.policy.collect.collector,
collector_env, [policy.collect_mode, policy.collect_mode],
tb_logger,
exp_name=cfg.exp_name
)
evaluator_cfg = copy.deepcopy(cfg.policy.eval.evaluator)
evaluator_cfg.stop_value = cfg.env.stop_value
evaluator = InteractionSerialEvaluator(
evaluator_cfg,
evaluator_env,
policy.eval_mode,
tb_logger,
exp_name=cfg.exp_name,
instance_name='builtin_ai_evaluator'
)
learner.call_hook('before_run')
for _ in range(max_iterations):
if evaluator.should_eval(learner.train_iter):
stop_flag, reward = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop_flag:
break
new_data, _ = collector.collect(train_iter=learner.train_iter)
train_data = new_data[0] + new_data[1]
learner.train(train_data, collector.envstep)
learner.call_hook('after_run')
if __name__ == "__main__":
main(main_config)
Note: To run the intelligent body against built-in bot mode, python slime_volley_ppo_config.py.
Note: For some specific algorithm, use the corresponding specific entry function.
Algorithm Benchmark¶
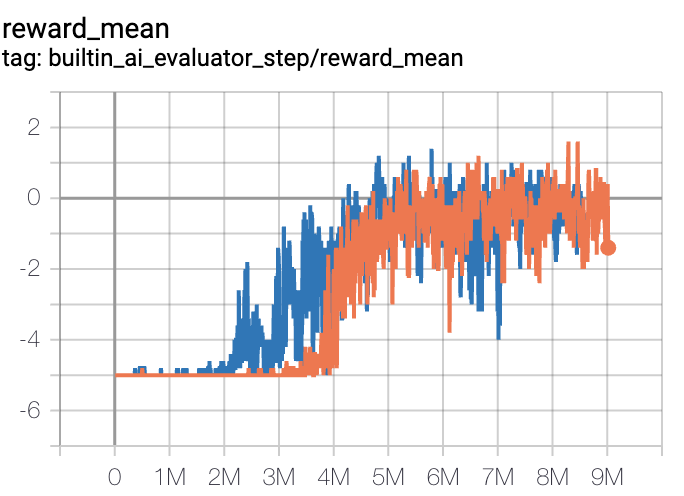
SlimeVolley-v0(Average reward greater than 1 is considered as good agent with the build-in bot)
SlimeVolley-v0 + PPO + vs Bot
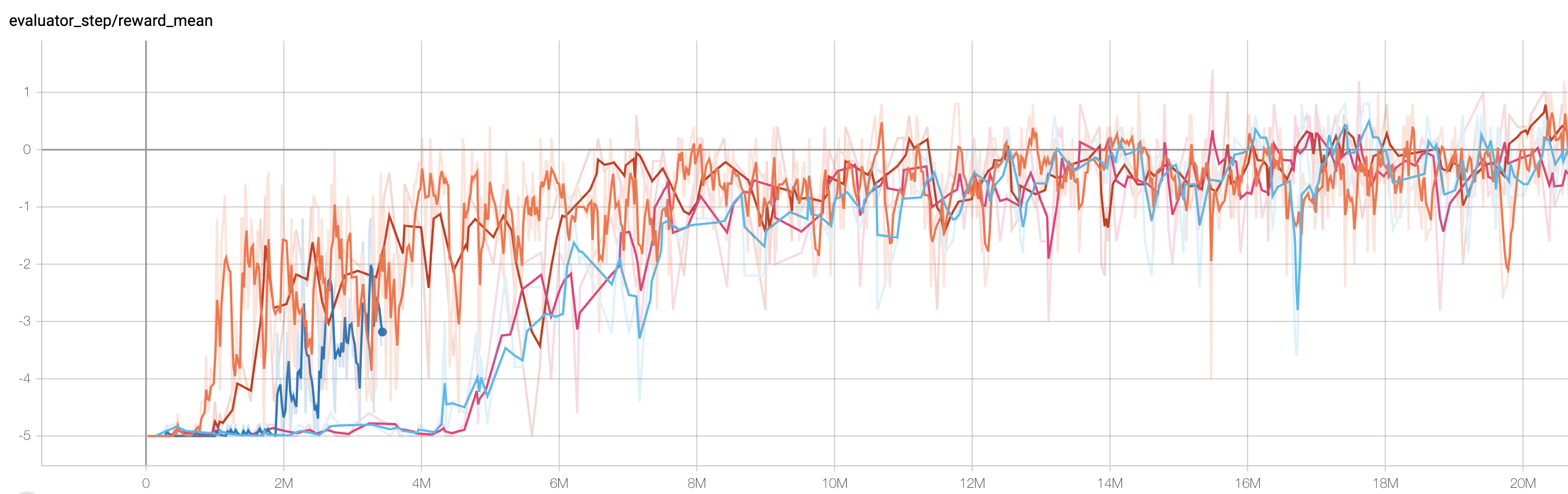
SlimeVolley-v0 + PPO + self-play