Pendulum¶
概述¶
倒立摆问题是强化学习中的经典控制问题。Pendulum 是倒立摆问题中的一个连续控制任务。钟摆以随机位置开始,目标是向上摆动保持直立。如下图所示。

安装¶
安装方法¶
Pendulum 环境内置在 gym 中,直接安装 gym 即可。其环境 id 是Pendulum-v0 。
pip install gym
验证安装¶
运行如下 Python 程序,如果没有报错则证明安装成功。
import gym
env = gym.make('Pendulum-v0')
obs = env.reset()
print(obs)
环境介绍¶
动作空间¶
Pendulum 的动作空间属于连续动作空间。
控制力矩: 大小范围是[-2, 2]。
使用 gym 环境空间定义则可表示为:
action_space = spaces.Box(low=-2,high=2)
状态空间¶
Pendulum 的状态空间有 3 个元素,描述了钟摆的角度和角速度。分别是:
sin:钟摆偏离竖直方向角度的 sin 值,范围是[-1, 1]。cos:钟摆偏离竖直方向角度的 cos 值,范围是[-1, 1]。thetadot:钟摆的角角度,范围是[-8, 8]。
奖励空间¶
首先计算 cost ,包括三项:
angle_normalize(th)**2: 对于当前倒立摆与目标位置的角度差的惩罚0.1*thdot**2: 对于角速度的惩罚。避免在接近目标时仍然具有较大的角速度,从而越过目标位置。0.001*(u**2): 对于输入力矩的惩罚。我们所使用的力矩越大,惩罚越大。
三项相加得到cost 。最后,将cost 的相反数,即-cost 作为 reward 值返回。
终止条件¶
Pendulum 环境每个 episode 的终止条件是遇到以下任何一种情况:
达到 episode 的最大 step。
DI-zoo 可运行代码示例¶
下面提供一个完整的 Pendulum 环境 config,采用 DDPG 算法作为 policy。请在DI-engine/dizoo/classic_control/pendulum/entry 目录下运行pendulum_ddpg_main.py 文件,如下。
import os
import gym
from tensorboardX import SummaryWriter
from ding.config import compile_config
from ding.worker import BaseLearner, SampleSerialCollector, InteractionSerialEvaluator, AdvancedReplayBuffer
from ding.envs import BaseEnvManager, DingEnvWrapper
from ding.policy import DDPGPolicy
from ding.model import QAC
from ding.utils import set_pkg_seed
from dizoo.classic_control.pendulum.envs import PendulumEnv
from dizoo.classic_control.pendulum.config.pendulum_ddpg_config import pendulum_ddpg_config
def main(cfg, seed=0):
cfg = compile_config(
cfg,
BaseEnvManager,
DDPGPolicy,
BaseLearner,
SampleSerialCollector,
InteractionSerialEvaluator,
AdvancedReplayBuffer,
save_cfg=True
)
# Set up envs for collection and evaluation
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env = BaseEnvManager(
env_fn=[lambda: PendulumEnv(cfg.env) for _ in range(collector_env_num)], cfg=cfg.env.manager
)
evaluator_env = BaseEnvManager(
env_fn=[lambda: PendulumEnv(cfg.env) for _ in range(evaluator_env_num)], cfg=cfg.env.manager
)
# Set random seed for all package and instance
collector_env.seed(seed)
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
# Set up RL Policy
model = QAC(**cfg.policy.model)
policy = DDPGPolicy(cfg.policy, model=model)
# Set up collection, training and evaluation utilities
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
learner = BaseLearner(cfg.policy.learn.learner, policy.learn_mode, tb_logger, exp_name=cfg.exp_name)
collector = SampleSerialCollector(
cfg.policy.collect.collector, collector_env, policy.collect_mode, tb_logger, exp_name=cfg.exp_name
)
evaluator = InteractionSerialEvaluator(
cfg.policy.eval.evaluator, evaluator_env, policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
replay_buffer = AdvancedReplayBuffer(cfg.policy.other.replay_buffer, tb_logger, exp_name=cfg.exp_name)
# Training & Evaluation loop
while True:
# Evaluate at the beginning and with specific frequency
if evaluator.should_eval(learner.train_iter):
stop, reward = evaluator.eval(learner.save_checkpoint, learner.train_iter, collector.envstep)
if stop:
break
# Collect data from environments
new_data = collector.collect(train_iter=learner.train_iter)
replay_buffer.push(new_data, cur_collector_envstep=collector.envstep)
# Train
for i in range(cfg.policy.learn.update_per_collect):
train_data = replay_buffer.sample(learner.policy.get_attribute('batch_size'), learner.train_iter)
if train_data is None:
break
learner.train(train_data, collector.envstep)
if __name__ == "__main__":
main(pendulum_ddpg_config, seed=0)
实验结果¶
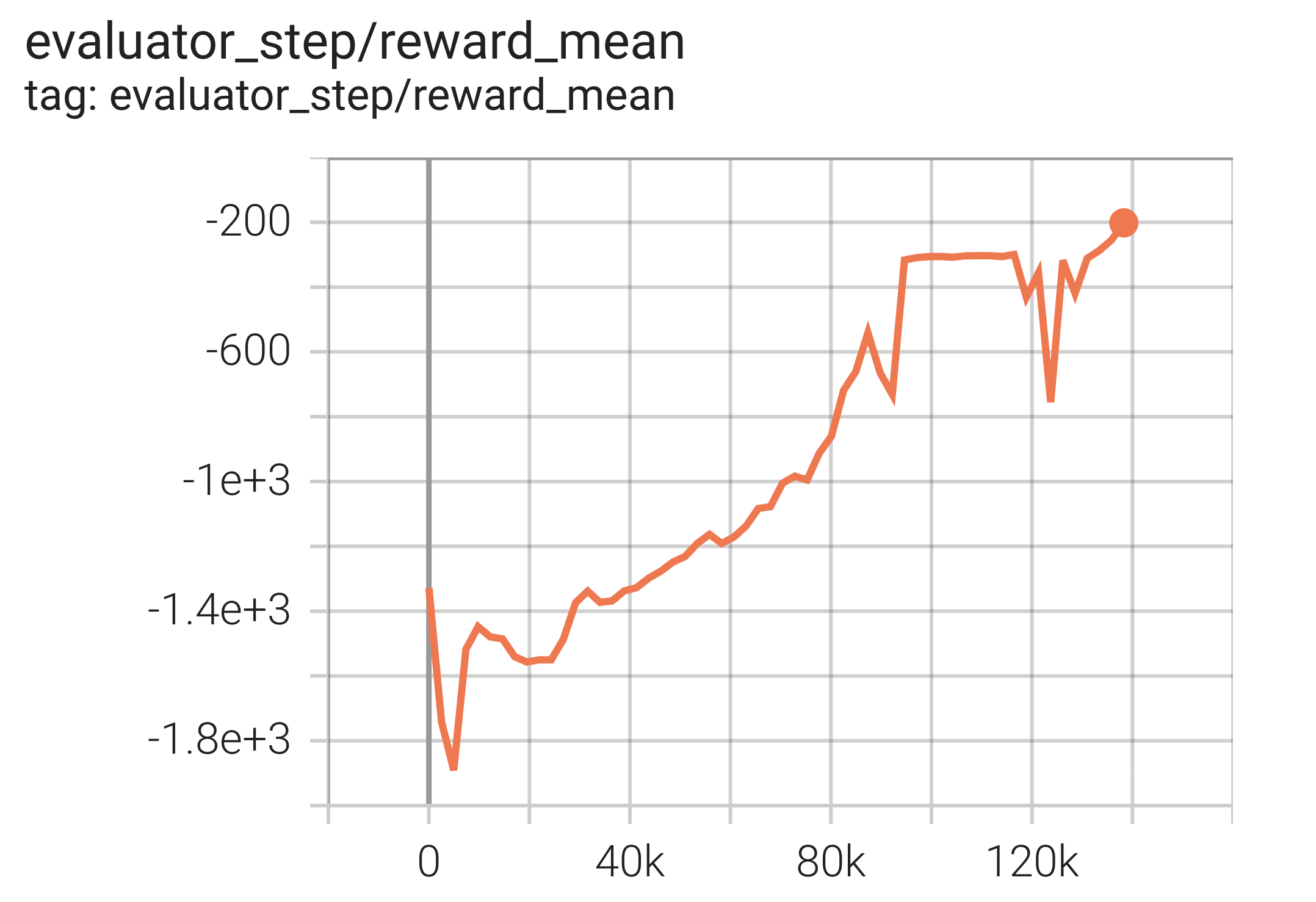
使用 DDPG 算法的实验结果如下。横坐标是episode ,纵坐标是reward_mean 。
参考资料¶
Pendulum 源码