揭秘第一个强化学习程序¶
强化学习算法是众多获得决策智能体的机器学习算法之一。 CartPole 是强化学习入门的理想学习环境,使用 DQN 算法可以在很短的时间内让 CartPole 收敛(保持平衡)。 我们将基于 CartPole + DQN 介绍一下 DI-engine 的用法。
使用配置文件¶
DI-engine 使用一个全局的配置文件来控制环境和策略的所有变量,每个环境和策略都有对应的默认配置,这个样例使用的完整配置可以在 cartpole_dqn_config 看到,在教程中我们直接调用即可:
from dizoo.classic_control.cartpole.config.cartpole_dqn_config import main_config, create_config
from ding.config import compile_config
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
初始化采集环境和评估环境¶
在强化学习中,训练阶段和评估阶段和环境交互的策略可能有区别,例如训练阶段往往是采集 n 个步骤就训练一次,且需要一些额外信息帮助训练 而评估阶段则需要完成整局游戏才能得到评分,且只考虑性能评价指标本身。我们推荐将采集和评估环境分开初始化:
from ding.envs import DingEnvWrapper, BaseEnvManagerV2
collector_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = BaseEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make("CartPole-v0")) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
Note
对于常用的强化学习环境格式(例如满足 gym 相关接口的环境),可以通过 DingEnvWrapper 一键转换为适用于 DI-engine 的环境格式。 而 BaseEnvManagerV2 是统筹多个环境的统一管理器,利用 BaseEnvManagerV2 可以同时对多个环境进行并行采集。
选择策略¶
DI-engine 集成了大部分强化学习策略,使用它们只需要选择相应的模型和策略即可(完整的策略列表可以参考 Policy Zoo )。 由于 DQN 是一个 off-policy 策略,所以我们还需要实例化一个 buffer 模块。
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.data import DequeBuffer
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
构建训练管线¶
利用 DI-engine 提供的各类中间件,我们可以很容易的构建整个训练管线,各个中间件的功能和使用方法可以参考 中间件入门 :
from ding.framework import task
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, eps_greedy_handler, CkptSaver
with task.start(async_mode=False, ctx=OnlineRLContext()):
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env)) # 评估流程,放在第一个是为了获得随机模型的评分作为基准值
task.use(eps_greedy_handler(cfg)) # 衰减探索-利用的概率
task.use(StepCollector(cfg, policy.collect_mode, collector_env)) # 采集环境数据
task.use(data_pusher(cfg, buffer_)) # 将数据保存到 buffer
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_)) # 训练模型
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100)) # 保存模型
task.run() # 在评估流程中,如果发现模型表现已经超过了收敛值,这里将提前结束
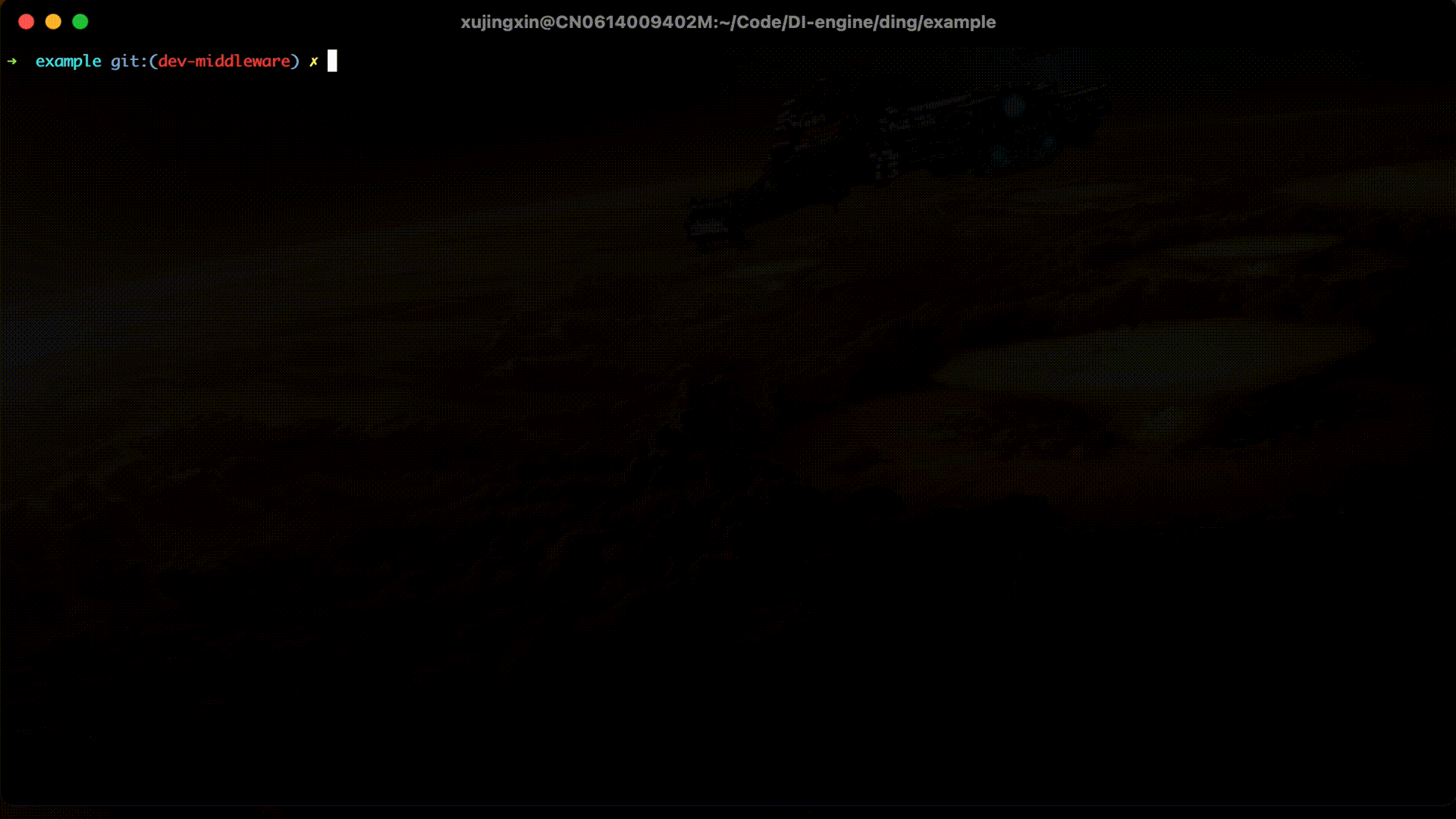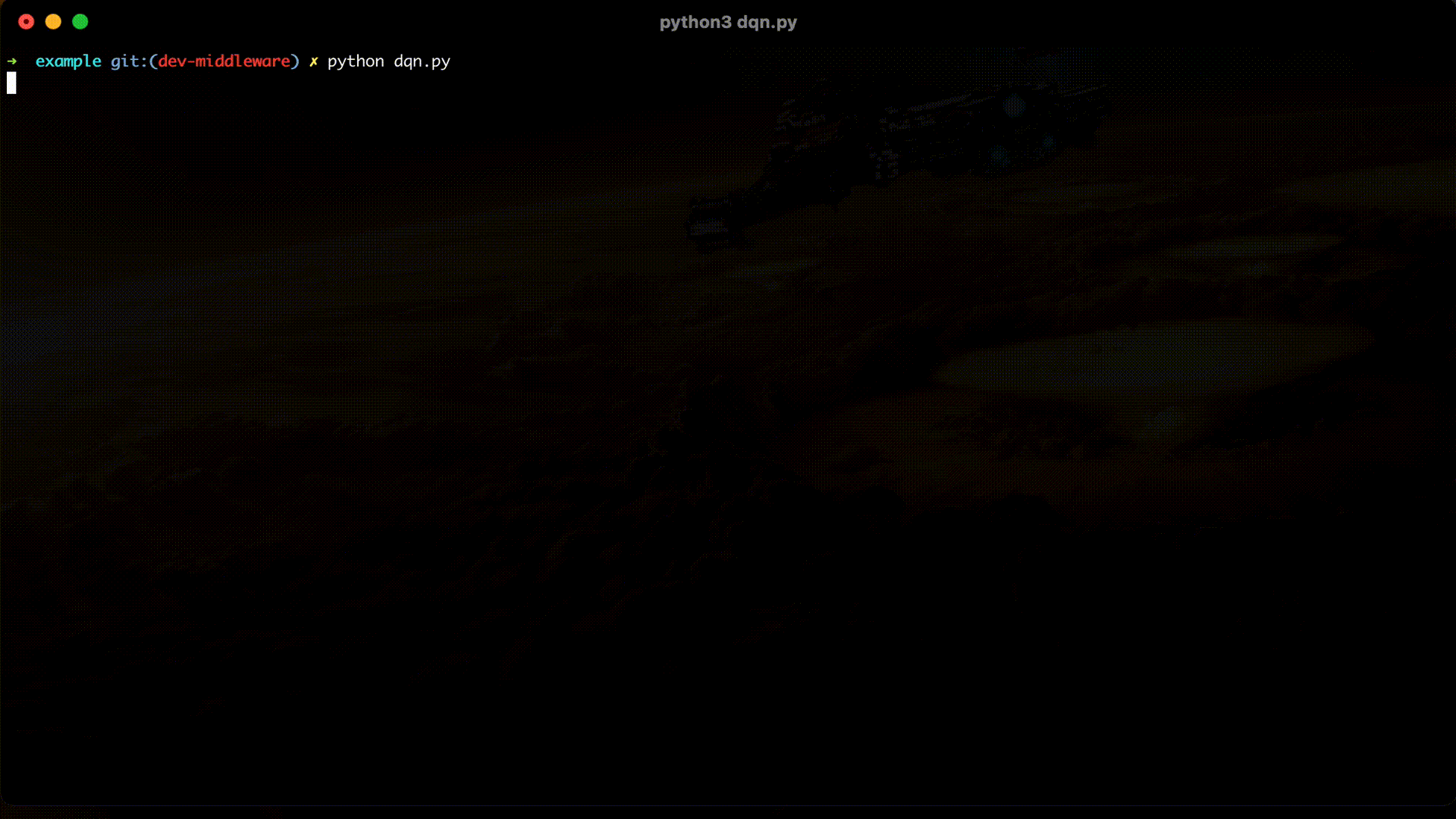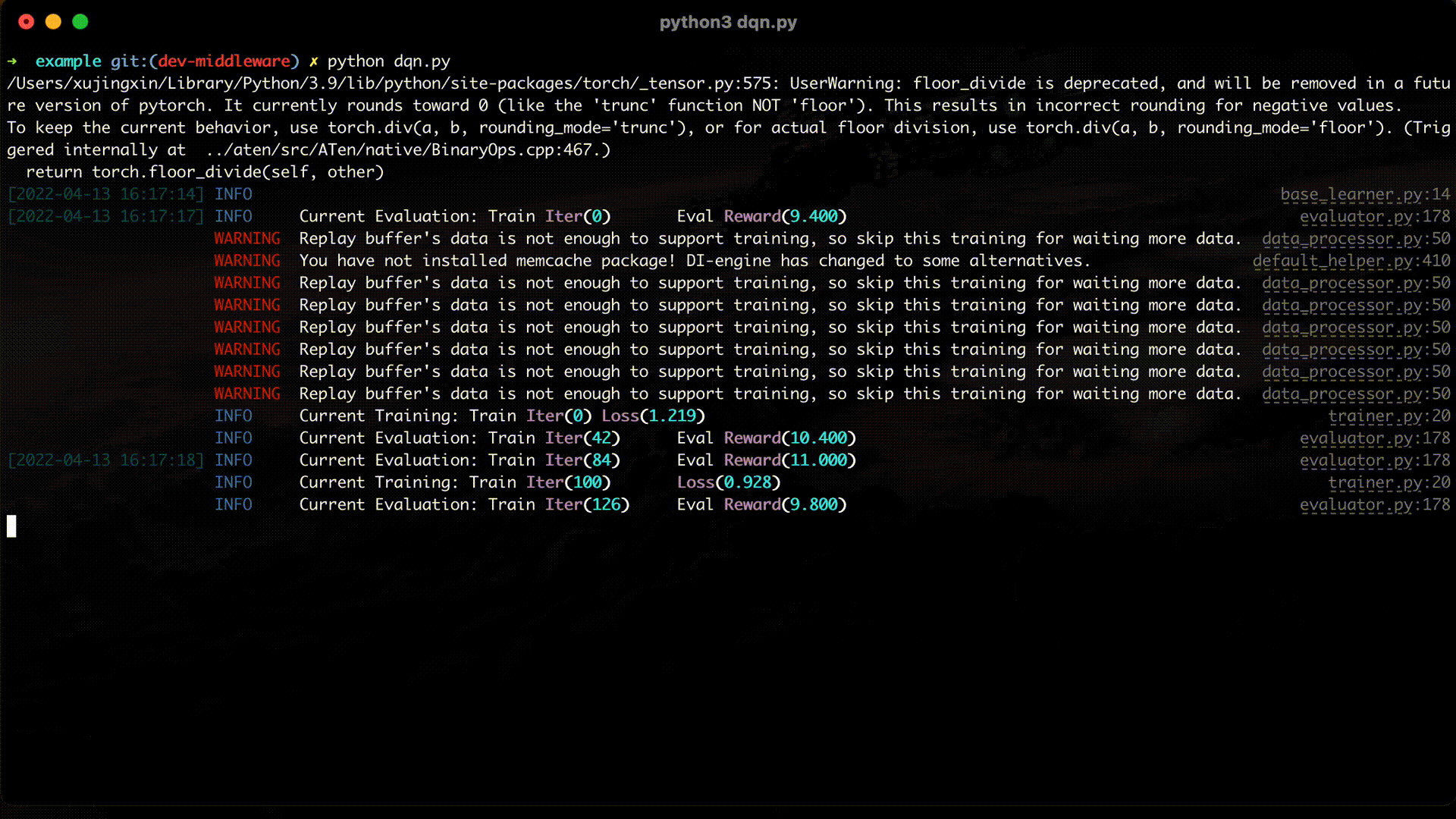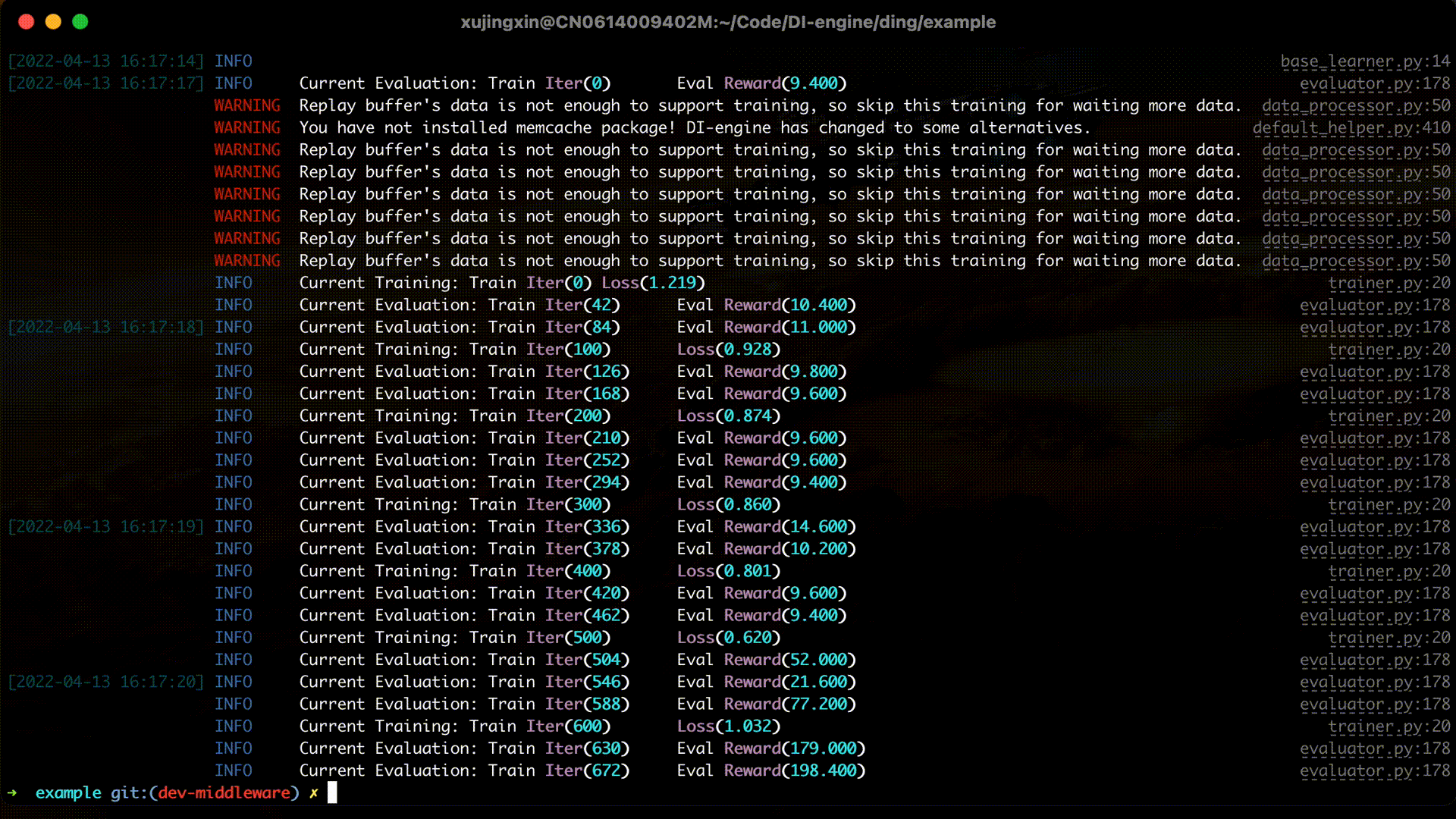
运行代码¶
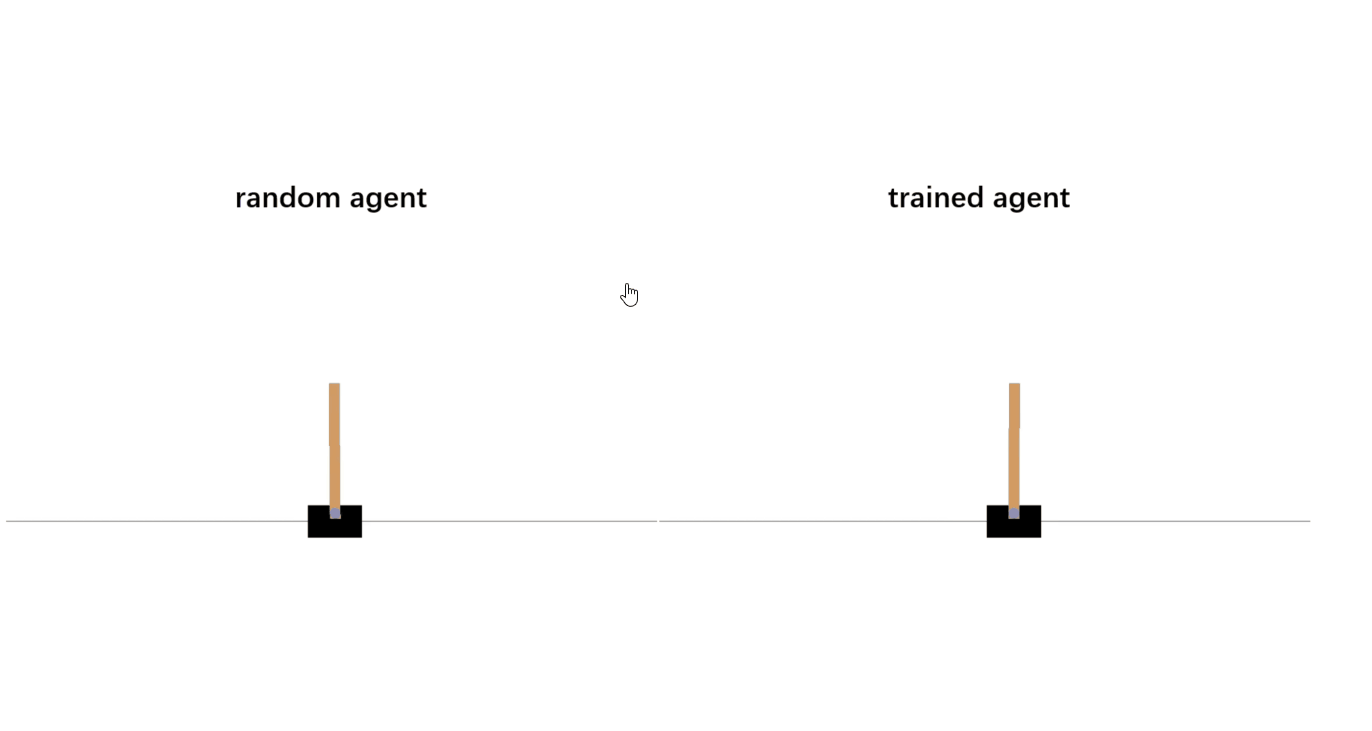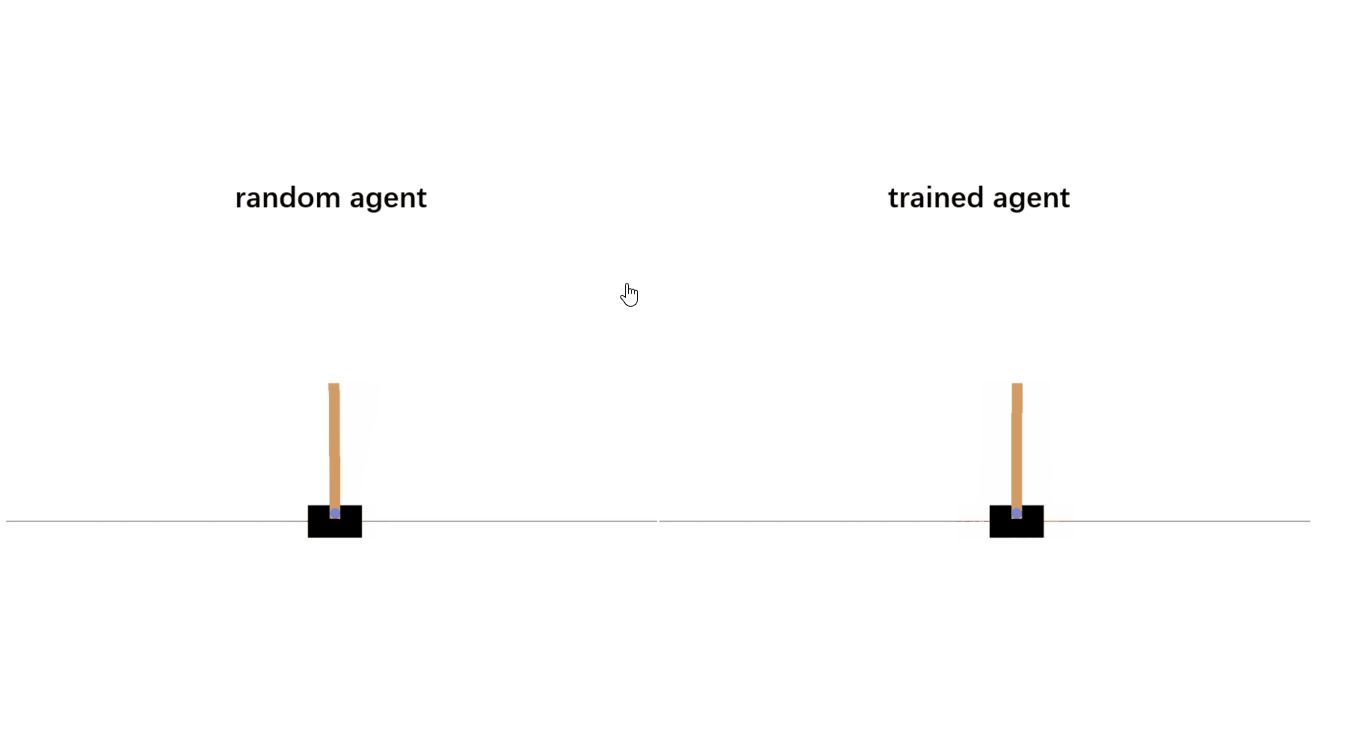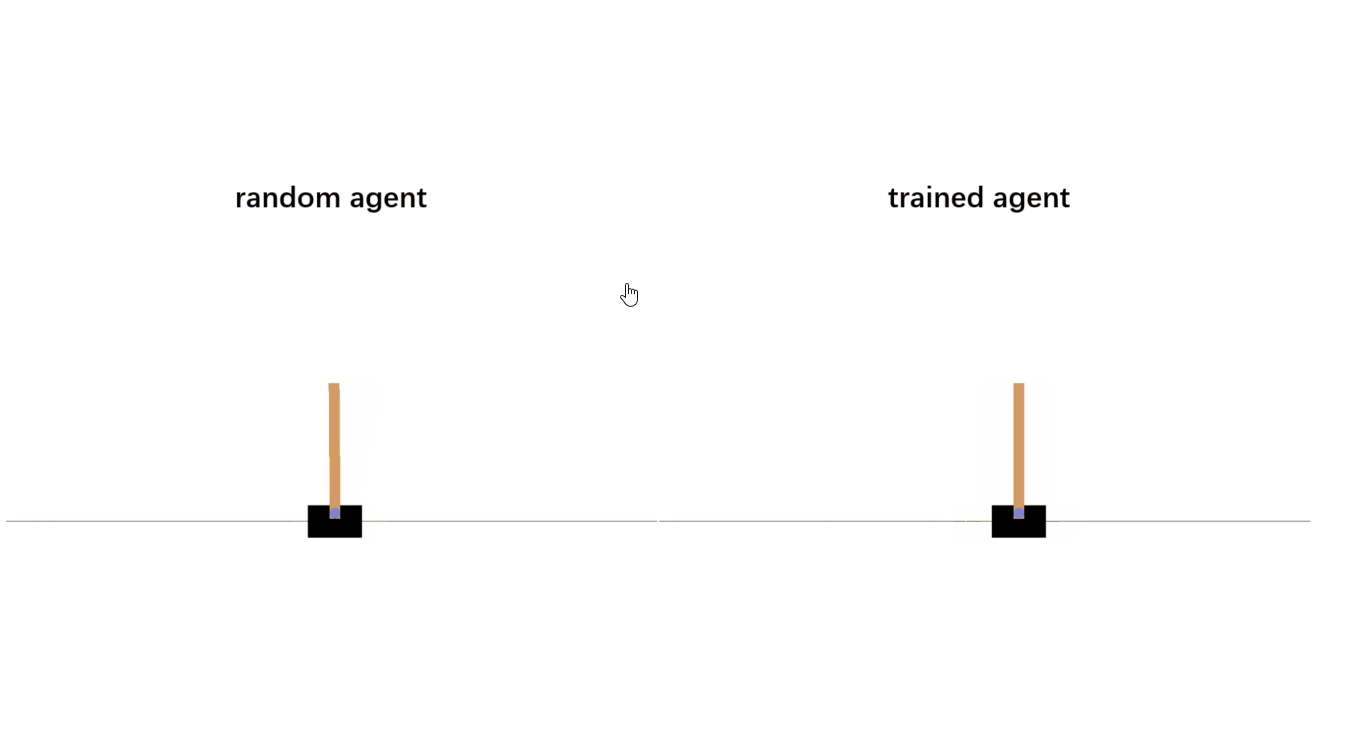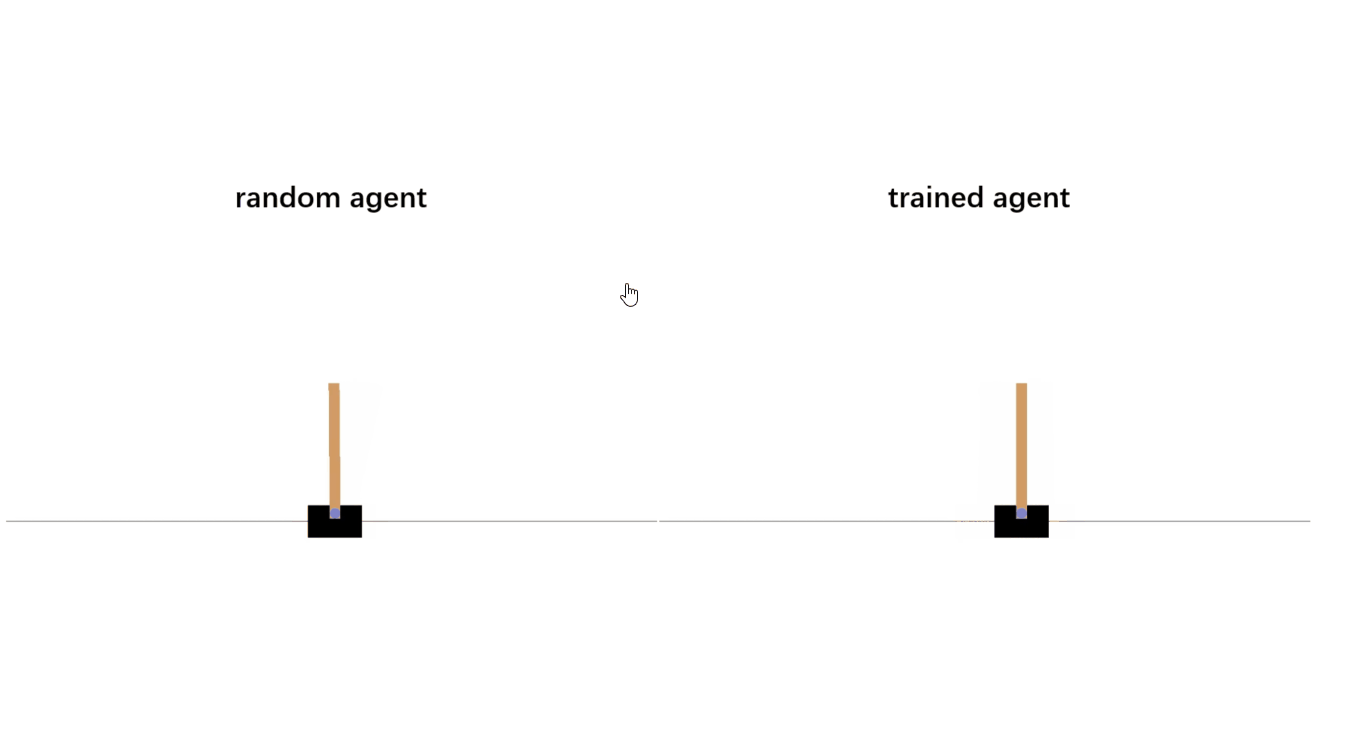
完整的示例代码可以在 DQN example 中找到,通过 python3 -u dqn.py 即可运行代码,下面的 gif 便是一个具体运行的例子。
此外,我们提供了从 DI-engine 安装到训练的全过程 Colab 运行示例 作为参考。
至此您已经完成了 DI-engine 的第一个强化学习任务,您可以在 示例目录 中尝试更多的算法, 或继续阅读文档来深入了解 DI-engine 的 算法, 系统设计 和 最佳实践 。