冒险,开始!¶
决策智能是人工智能领域最重要的方向之一,研究者们试图结合强化学习和深度学习去打造媲美甚至超越人类的智能体。更具体一点,我们会将各种各样的决策问题抽象为一种通用的形式:智能体与决策环境不断交互,并在交互中通过探索和利用不断成长。 而从数据流的角度来看,就是智能体来处理来自环境的状态信息,给出合理的响应和决策,环境执行决策并返回反馈信号和新的状态。从优化的角度来看,就是让智能体的行为向探索,适应,征服环境的方向前进。联系实际应用,比如无人驾驶汽车会接收来自环境中的路况信息,给出实时的驾驶行为决策,从而让车辆高效平稳地驶向目的地。
我们首先使用”月球着陆器(Lunarlander)”这个环境来介绍决策智能引擎 DI-engine 中的各种智能体操作,包含如何让智能体和环境交互,如何训练智能体,如何探索更多新奇的事情等等。
在 LunarLander 这个模拟环境里,智能体需要将着陆器安全平稳地降落至指定区域,示意图如下:

先定一个小目标:让你的智能体动起来!¶
智能体形式上是一个可以与环境自由互动的对象,其本质上是一个接受输入,反馈输出的数学模型。它的模型由一个模型结构和一组模型参数构成。
通常,我们会把模型写入存放在一个文件中,或是从一个文件中读出所需要的智能体模型。
这里我们提供了一个由 DI-engine 框架使用 DQN 算法训练的智能体模型:
final.pth.tar 只需要使用以下的代码,就可以让智能体动起来,记得要把函数中的模型地址 ckpt_path='./final.pth.tar' 换成本地保存的地址(例如 ckpt_path='~/Download/final.pth.tar' )
import gym # 载入 gym 库,用于标准化强化学习环境
import torch # 载入 PyTorch 库,用于加载 Tensor 模型,定义计算网络
from easydict import EasyDict # 载入 EasyDict,用于实例化配置文件
from ding.config import compile_config # 载入DI-engine config 中配置相关组件
from ding.envs import DingEnvWrapper # 载入DI-engine env 中环境相关组件
from ding.policy import DQNPolicy, single_env_forward_wrapper # 载入DI-engine policy 中策略相关组件
from ding.model import DQN # 载入DI-engine model 中模型相关组件
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config # 载入DI-zoo lunarlander 环境与 DQN 算法相关配置
def main(main_config: EasyDict, create_config: EasyDict, ckpt_path: str):
main_config.exp_name = 'lunarlander_dqn_deploy' # 设置本次部署运行的实验名,即为将要创建的工程文件夹名
cfg = compile_config(main_config, create_cfg=create_config, auto=True) # 编译生成所有的配置
env = DingEnvWrapper(gym.make(cfg.env.env_id), EasyDict(env_wrapper='default')) # 在gym的环境实例的基础上添加DI-engine的环境装饰器
env.enable_save_replay(replay_path='./lunarlander_dqn_deploy/video') # 开启环境的视频录制,设置视频存放位置
model = DQN(**cfg.policy.model) # 导入模型配置,实例化DQN模型
state_dict = torch.load(ckpt_path, map_location='cpu') # 从模型文件加载模型参数
model.load_state_dict(state_dict['model']) # 将模型参数载入模型
policy = DQNPolicy(cfg.policy, model=model).eval_mode # 导入策略配置,导入模型,实例化DQN策略,并选择评价模式
forward_fn = single_env_forward_wrapper(policy.forward) # 使用简单环境的策略装饰器,装饰DQN策略的决策方法
obs = env.reset() # 重置初始化环境,获得初始观测
returns = 0. # 初始化总奖励
while True: # 让智能体的策略与环境,循环交互直到结束
action = forward_fn(obs) # 根据观测状态,决定决策动作
obs, rew, done, info = env.step(action) # 执行决策动作,与环境交互,获得下一步的观测状态,此次交互的奖励,是否结束的信号,以及其它环境信息
returns += rew # 累计奖励回报
if done:
break
print(f'Deploy is finished, final epsiode return is: {returns}')
if __name__ == "__main__":
main(main_config=main_config, create_config=create_config, ckpt_path='./final.pth.tar')
示例的代码里,通过使用 torch.load 可以获得模型的 PyTorch 对象的参数。 然后使用 load_state_dict 即可将模型加载至 DI-engine 的 DQN 模型中,这样就可以完整地恢复该模型。 然后将 DQN 模型加载到 DQN 策略中,使用评价模式的 forward_fn 函数,即可让智能体对环境状态 obs 产生反馈的动作 action 。 智能体的动作 action 会和环境进行一次互动,生成下一个时刻的环境状态 obs (observation) ,此次交互的奖励 rew (reward),环境是否结束的信号 done 以及其他信息 info (information) 。
Note
环境状态一般是一组向量或张量。奖励值一般是一个实数数值。环境是否结束的信号是一个布尔变量,是或否。其他信息则是环境的创建者想要额外传递的消息,格式不限。
所有时刻的奖励值会被累加,作为本次智能体在这个任务中的总分。
Note
你可以在日志中看到此次部署智能体的总分,以及可以在文件目录中看到此次视频的回放。
更好地评估智能体¶
在强化学习的各种环境中,智能体的初始状态并不总是完全相同。而智能体的成绩可能会随不同的初始状态而发生波动。 因此,我们需要开设多个环境,从而多进行几次评估测试,来更好地为它打分。 比如在”月球着陆器”这个环境里,每一次的月球地貌都不相同。
DI-engine 设计了环境管理器 env_manager 来做到这一点,我们可以使用以下稍微更复杂一些的代码来做到这一点:
import os
import gym
import torch
from tensorboardX import SummaryWriter
from easydict import EasyDict
from ding.config import compile_config
from ding.worker import BaseLearner, SampleSerialCollector, InteractionSerialEvaluator, AdvancedReplayBuffer
from ding.envs import BaseEnvManager, DingEnvWrapper
from ding.policy import DQNPolicy
from ding.model import DQN
from ding.utils import set_pkg_seed
from ding.rl_utils import get_epsilon_greedy_fn
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
# Get DI-engine form env class
def wrapped_cartpole_env():
return DingEnvWrapper(
gym.make(main_config['env']['env_id']),
EasyDict(env_wrapper='default'),
)
def main(cfg, seed=0):
cfg['exp_name'] = 'lunarlander_dqn_eval'
cfg = compile_config(
cfg,
BaseEnvManager,
DQNPolicy,
BaseLearner,
SampleSerialCollector,
InteractionSerialEvaluator,
AdvancedReplayBuffer,
save_cfg=True
)
cfg.policy.load_path = './final.pth.tar'
# build multiple environments and use env_manager to manage them
evaluator_env_num = cfg.env.evaluator_env_num
evaluator_env = BaseEnvManager(env_fn=[wrapped_cartpole_env for _ in range(evaluator_env_num)], cfg=cfg.env.manager)
# switch save replay interface
# evaluator_env.enable_save_replay(cfg.env.replay_path)
evaluator_env.enable_save_replay(replay_path='./lunarlander_dqn_eval/video')
# Set random seed for all package and instance
evaluator_env.seed(seed, dynamic_seed=False)
set_pkg_seed(seed, use_cuda=cfg.policy.cuda)
# Set up RL Policy
model = DQN(**cfg.policy.model)
policy = DQNPolicy(cfg.policy, model=model)
policy.eval_mode.load_state_dict(torch.load(cfg.policy.load_path, map_location='cpu'))
# Evaluate
tb_logger = SummaryWriter(os.path.join('./{}/log/'.format(cfg.exp_name), 'serial'))
evaluator = InteractionSerialEvaluator(
cfg.policy.eval.evaluator, evaluator_env, policy.eval_mode, tb_logger, exp_name=cfg.exp_name
)
evaluator.eval()
if __name__ == "__main__":
main(main_config)
Note
DI-engine 的环境管理器在对多个环境进行并行评估的时候,还会一并统计奖励的平均值,最大值和最小值,以及一些算法相关的其它指标。
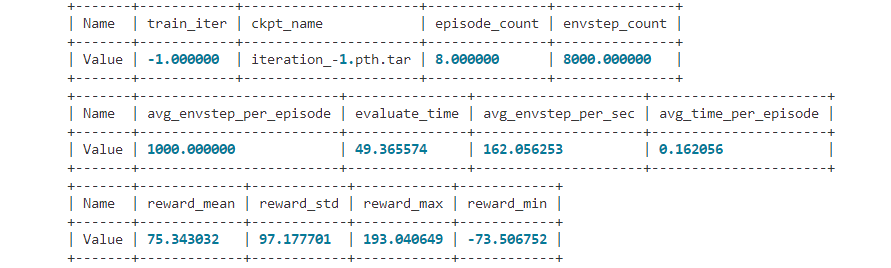
从零训练出强大的智能体¶
使用 DI-engine 运行以下的代码,来获得上述测试中的智能体模型。 试试自己生成一个智能体模型,或许它会更强:
import gym
from ditk import logging
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.envs import DingEnvWrapper, BaseEnvManagerV2, SubprocessEnvManagerV2
from ding.data import DequeBuffer
from ding.config import compile_config
from ding.framework import task, ding_init
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \
eps_greedy_handler, CkptSaver, online_logger, nstep_reward_enhancer
from ding.utils import set_pkg_seed
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
def main():
logging.getLogger().setLevel(logging.INFO)
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
ding_init(cfg)
with task.start(async_mode=False, ctx=OnlineRLContext()):
collector_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(nstep_reward_enhancer(cfg))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(online_logger(train_show_freq=10))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.run()
if __name__ == "__main__":
main()
Note
上述代码在 Intel i5-10210U 1.6GHz CPU 且无GPU设备的情况下大约需要10分钟训练至默认终止点。 如果希望训练的时间变得更短,可以尝试更简单的 Cartpole 环境。
Note
DI-engine 集成了 tensorboard 组件,用于记录训练过程中的关键信息。你可以在训练时开启它,这样你就可以看到实时更新的信息,比如评估器记录的平均总奖励值等等。
做的不错!至此您已经完成了 DI-engine 的 Hello World 任务,使用了提供的代码和模型,学习了强化学习的智能体与环境是如何交互的。 请继续阅读文档, 揭秘第一个强化学习程序 , 来了解 DI-engine 的强化学习算法的生产框架是如何搭建的。