Configuration File System¶
Introduction¶
Configuration file system is an important component in machine learning algorithm tools, and the complexity of reinforcement learning makes its configuration field tasks more intricate compared to other machine learning tasks. To address this issue, DI-engine is designed based on the principle of “Convention over Configuration” (CoC), and a set of basic principles and related tools are developed, including:
Python configuration principles
Configuration compilation principles
Default configuration and user configuration
Classification of core configuration fields for reinforcement learning tasks
Note
To learn more about the Convention over Configuration principle, you can refer to a Chinese blog post 设计杂谈(0x02)——约定大于配置 .
Basic Principles¶
The overall schematic diagram is as follows:
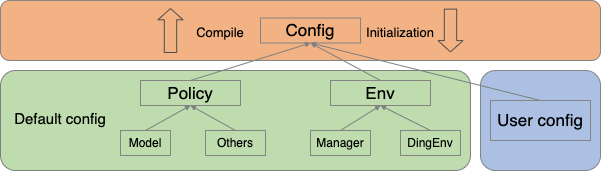
Python Configuration Principles¶
As most machine learning programs value programming flexibility and ease of use, DI-engine uses Python files (specifically, multi-level dict) as the default configuration file to be compatible with various special requirements. Users who previously used yaml and json can also easily migrate to Python configuration. However, for parts outside of the core modules, such as communication interfaces in reinforcement learning simulation environments, native configuration can also be used without any special restrictions.
Configuration Compilation Principles¶
For the entire training program, DI-engine uses tool functions such as compile_config and get_instance_cfg as boundaries. Before the boundary, users can customize the required configuration content through various means such as using default configurations, modifying configurations in the code, and entering configurations from the command line. However, after the boundary, all configuration files will be fixed and no further changes will be allowed. The training program will also create corresponding functional modules and training pipelines based on the configuration at that time. This rule is called the Configuration Compilation Principles , where the period before the boundary is the configuration compilation generation period , and the period after the boundary is the configuration runtime usage period . In addition, in the tool functions, the final generated configuration file will be exported and stored in the experiment directory folder (usually named total_config.py ), which can be used by users to check the validity of the configuration file settings or to reproduce the original experiment directly using this file.
Note
Typically, after completing an experiment, relevant information is stored in a path folder named after the exp_name configuration field. Among them, the macro configuration information file is total_config.py , and the configuration file that can be directly used for training after format conversion is formatted_total_config.py . Users can import the corresponding main_config and create_config directly from this file and pass them to the training entry function to start the experiment.
Tip
To ensure the effectiveness of the Configuration Compilation Principles, users are advised not to use operations such as cfg.get('field_xxx', 'xxx') in module code as it can violate the compilation principles and cannot record and track relevant modifications.
Default Configuration and User Configuration¶
On the other hand, due to the various configuration contents such as MDP modeling settings, algorithm tuning settings, and training system efficiency settings in reinforcement learning training programs, there are often numerous configurable file fields. However, different configuration fields have different usage frequencies, and in most cases, most configuration fields do not need to be modified by users. Therefore, DI-engine has introduced the concept of default configuration, where core concepts in reinforcement learning, such as Policy, Env, and Buffer, often have their default configurations (default config), whose complete definitions and explanations can be found in the corresponding class definitions. When using DI-engine, users only need to specify the configuration fields that need to be modified or added in the current situation. In the boundary function mentioned earlier (such as compile_config ), the default configuration and user configuration are compiled and merged to form the final configuration file. The specific merging rules are as follows:
Fields that exist in the default configuration but not in the user configuration will use the default values.
Fields that exist in the user configuration but not in the default configuration will use the values specified by the user.
Fields that exist in both the default configuration and the user configuration will use the values specified by the user.
The Categories of Core Configuration Fields of a Reinforcement Learning Task¶
Overall, the configuration fields required for reinforcement learning tasks in DI-engine can be mainly classified into two categories:
The first category consists of objects that are shared by various workers/middleware in the training pipeline, such as algorithm policies (
Policy), environments (Env), reward models (Reward Model), data queues (Buffer), and so on. Each of these objects has its own default configuration. In the overall configuration file, they are placed in parallel with each other and maintain a flat hierarchy. The meaning of each object’s configuration fields can be found in the corresponding class definition, and the class variablesconfigand class methoddefault_configspecify the default configuration and calling method.The second category consists of workers/middleware that perform various tasks in the training pipeline, such as learners (
Learner), data collectors (Collector), and so on. They generally have fewer corresponding parameters, which can be directly specified in the training entry function or attached to the global area of the overall configuration file. There are no special requirements for their specific implementation, and the code should be kept clear and easy to use.
In addition to the main configuration main_config , there is also a creation configuration create_config that helps to quickly create training entry points. This part of the creation configuration is only used in the serial_pipeline_xxx series of quick training entry points, and can be ignored by users who create their own custom training entry functions. The creation configuration needs to specify the corresponding type name ( type ) and the path required to import the module ( import_names ).
Note
Due to historical reasons, there were many sub-domains defined in the Policy field, such as learn, collect, eval, other, and so on. However, in the latest version of DI-engine (>=0.4.7), the mandatory dependency on these definitions has been removed. Now, using or not using these structures is optional, as long as the configuration fields are corresponded with the corresponding effective code segments in the policy.
Other Tools¶
DI-engine also provides some related tools for configuration file storage and formatting. For specific information, please refer to the code ding/config .
Analysis of Configuration File Examples¶
Here’s a specific configuration example in DI-engine, which is used to train a DQN agent in the CartPole environment (the example used in the quick start document). The specific configuration content and related field explanations are as follows:
from easydict import EasyDict
cartpole_dqn_config = dict(
exp_name='cartpole_dqn_seed0',
env=dict(
collector_env_num=8,
evaluator_env_num=5,
n_evaluator_episode=5,
stop_value=195,
),
policy=dict(
cuda=False,
model=dict(
obs_shape=4,
action_shape=2,
),
nstep=1,
discount_factor=0.97,
learn=dict(
update_per_collect=5,
batch_size=64,
learning_rate=0.001,
),
collect=dict(n_sample=8),
),
)
cartpole_dqn_config = EasyDict(cartpole_dqn_config)
main_config = cartpole_dqn_config
cartpole_dqn_create_config = dict(
env=dict(
type='cartpole',
import_names=['dizoo.classic_control.cartpole.envs.cartpole_env'],
),
env_manager=dict(type='base'),
policy=dict(type='dqn'),
)
cartpole_dqn_create_config = EasyDict(cartpole_dqn_create_config)
create_config = cartpole_dqn_create_config
if __name__ == "__main__":
# or you can enter `ding -m serial -c cartpole_dqn_config.py -s 0`
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
The entire configuration file can be divided into two parts, main_config and create_config . The main configuration (main_config) contains three parts: experiment name (exp_name), environment (env), and policy (policy), which respectively specify the most relevant and frequently modified configuration fields for the current task.
The creation configuration specifies the types of environment, environment manager, and policy, so that the quick training entry serial_pipeline below can directly run this configuration file. If you are using the task/middleware method to customize the training entry, you can directly load this configuration file.