DIAYN¶
概述¶
DIAYN (Diversity is All You Need) 首次在论文 Diversity is All You Need: Learning Skills without a Reward Function 中提出, 该算法可以使智能体在不提供奖励信号的环境中,主动学习出一个奖励函数, 并且自动探索出一些有用的技能(skills)。这些学到的技能为很多 RL 任务提供了基石,例如,要找到一个能在任务中获得高回报的策略,通常只需选择具有最大回报的技能就足够了。 另外三个应用分别是:
用于RL算法训练的策略初始化,加速学习过程。
用于分层强化学习:通过学习一个元控制器去组合DIAYN学习到的技能来解决复杂的分层任务。
用于模仿学习:找到最像专家行为的技能,并把该技能对应的策略作为模仿学习中学到的策略
DIAYN 是由三个核心的想法推导出来的。首先,为了让学到的技能有用,我们想让技能去决定智能体在与环境交互中会经历的状态, 即智能体采取不同的技能,能够访问到不同的状态。 其次,我们依靠状态,而不是动作去区分技能,因为无法对环境状态产生影响的动作对于观察者来说是不可见的。 最后,我们为了鼓励探索,并让学到的技能更加多元,对于每一个技能对应的策略,尽可能地让其动作更加随机。
核心要点¶
DIAYN 是无监督学习的算法
训练策略的奖励是由判别器生成,而不是环境给出的奖励
DIAYN 是基于 SAC 算法训练的,其训练过程包括:1.更新判别器以更好地预测技能,2.更新技能以访问不同的状态,使其更具判别能力。
关键方程或关键框图¶
DIAYN的算法的整体训练与计算流程如下:
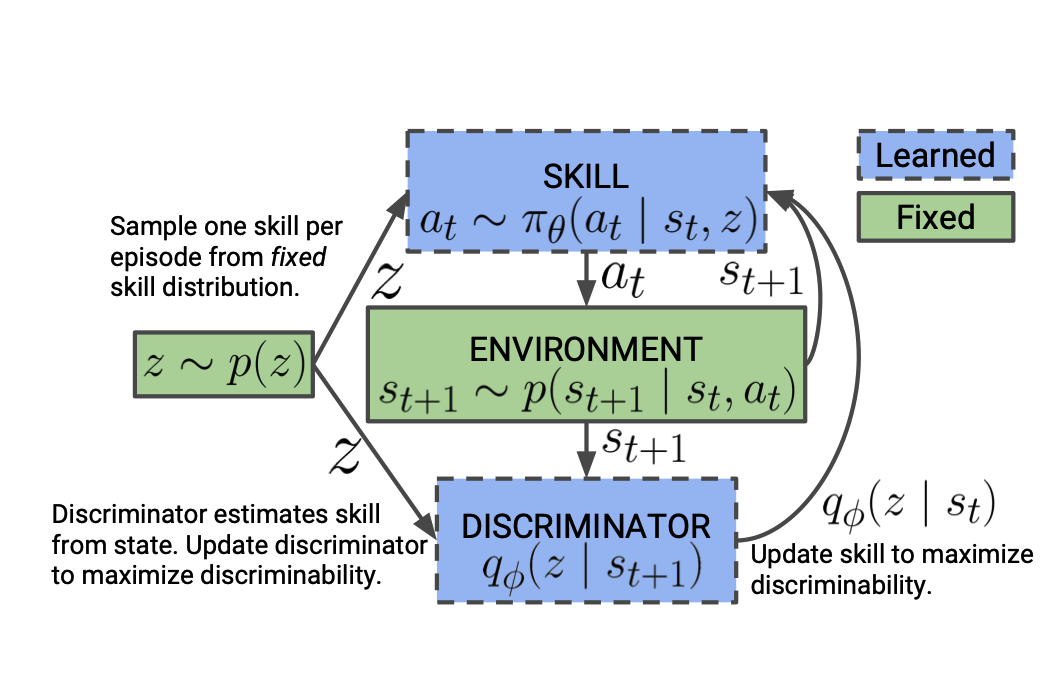
我们在游戏每一个 episode 的初始时刻随机采样一个技能,并通过依赖于这个技能的策略去跟环境交互产生数据。 通过产生的数据,我们去训练判别器使得其更好的通过状态判别技能。然后,我们更新策略使其产生能让判别器的判别能力最大化的数据。 由于我们之前提到 DIAYN 的算法是无监督学习,所以训练策略的奖励函数是由上述三个核心想法计算得来的, 具体来说:
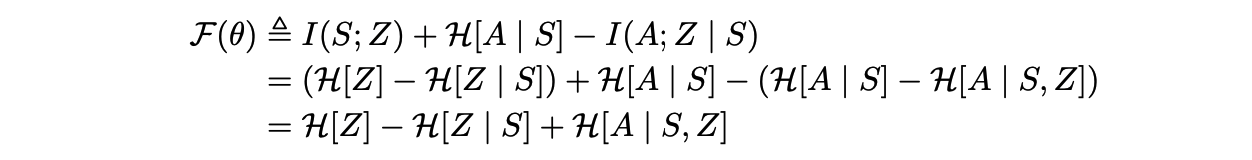
第一项鼓励我们对 p(z) 的先验分布具有很高的熵。在我们的方法中,我们把 p(z) 固定为均匀分布,保证它具有最大的熵。第二项表明,从当前状态推断技能z应该是很容易的。第三项表明,每个技能对应的策略应该尽可能地随机地选择动作,我们通过使用最大熵策略来实现此要求。 由于我们无法对所有的状态和技能进行整合以准确计算 p(z | s),我们用一个学习到的判别器 q(z | s)来近似这个后验。詹森不等式(Jensen’s Inequality) 告诉我们,用 q(z | s)代替p(z | s)可以给我们的目标 F(θ) 提供一个变分下限 G(θ, φ)
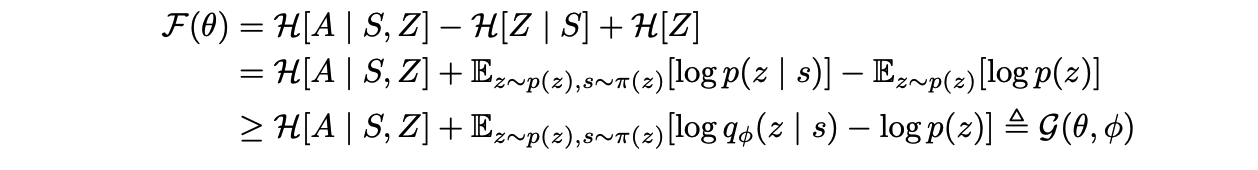
由于在 SAC 算法训练中最大化了策略的熵, 所以我们只需要把奖励函数变成了如下形式并通过 SAC 算法训练策略,便等同于最大化 G 这个期望:
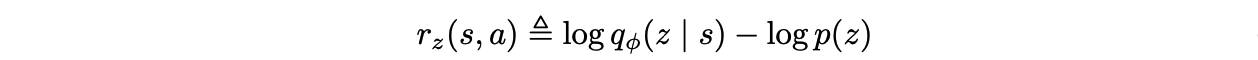
伪代码¶
以下为DIAYN的伪代码:

注意:我们在实现时采用了 off-policy SAC,通过从 buffer 中均匀随机采样 mini-batch 的样本来训练。其中 discriminator 建模为一个神经网络,其输入是观测到的状态,输出是对 skill 的预测分布。
实现¶
TBD
判别器网络¶
- 我们编写的判别器网络是由
linear encoder+regression head构成 discriminator = nn.Sequential( nn.Linear(obs_shape, discriminator_head_hidden_size), activation, RegressionHead( discriminator_head_hidden_size, num_skills, # output size discriminator_head_layer_num, final_tanh=False, activation=activation, norm_type=norm_type ) ) class RegressionHead(nn.Module): def __init__( self, hidden_size: int, output_size: int, layer_num: int = 2, final_tanh: Optional[bool] = False, activation: Optional[nn.Module] = nn.ReLU(), norm_type: Optional[str] = None ) -> None: r""" Overview: Init the Head according to arguments. Arguments: - hidden_size (:obj:`int`): The ``hidden_size`` used before connected to ``DuelingHead`` - output_size (:obj:`int`): The num of output - final_tanh (:obj:`Optional[bool]`): Whether a final tanh layer is needed - layer_num (:obj:`int`): The num of layers used in the network to compute Q value output - activation (:obj:`nn.Module`): The type of activation function to use in ``MLP`` the after ``layer_fn``, if ``None`` then default set to ``nn.ReLU()`` - norm_type (:obj:`str`): The type of normalization to use, see ``ding.torch_utils.fc_block`` for more details """ super(RegressionHead, self).__init__() self.main = MLP(hidden_size, hidden_size, hidden_size, layer_num, activation=activation, norm_type=norm_type) self.last = nn.Linear(hidden_size, output_size) # for convenience of special initialization self.final_tanh = final_tanh if self.final_tanh: self.tanh = nn.Tanh() def forward(self, x: torch.Tensor) -> Dict: r""" Overview: Use encoded embedding tensor to predict Regression output. Parameter updates with RegressionHead's MLPs forward setup. Arguments: - x (:obj:`torch.Tensor`): The encoded embedding tensor, determined with given ``hidden_size``, i.e. ``(B, N=hidden_size)``. Returns: - outputs (:obj:`Dict`): Run ``MLP`` with ``RegressionHead`` setups and return the result prediction dictionary. Necessary Keys: - pred (:obj:`torch.Tensor`): Tensor with prediction value cells, with same size as input ``x``. Examples: >>> head = RegressionHead(64, 64) >>> inputs = torch.randn(4, 64) >>> outputs = head(inputs) >>> assert isinstance(outputs, dict) >>> assert outputs['pred'].shape == torch.Size([4, 64]) """ x = self.main(x) x = self.last(x) if self.final_tanh: x = self.tanh(x) if x.shape[-1] == 1 and len(x.shape) > 1: x = x.squeeze(-1) return {'pred': x}
数据收集¶
在收集数据时,我们会在每个 episode 开始前,通过均匀分布,随机采样出一个技能:
collected_sample = 0 return_data = [] z_one_hot = np.zeros(num_skills) _p_z = np.full(num_skills, 1.0 / num_skills) z = np.random.choice(num_skills, p=_p_z) z_one_hot[z] = 1 while collected_sample < n_sample: with self._timer: # Get current env obs. obs = self._env.ready_obs obs[list(obs.keys())[0]] = np.concatenate((obs[list(obs.keys())[0]], np.float32(z_one_hot)), axis=None) # Policy forward. self._obs_pool.update(obs) if self._transform_obs: obs = to_tensor(obs, dtype=torch.float32) policy_output = self._policy.forward(obs, **policy_kwargs) self._policy_output_pool.update(policy_output) # Interact with env. actions = {env_id: output['action'] for env_id, output in policy_output.items()} actions = to_ndarray(actions) timesteps = self._env.step(actions)
基准算法性能¶
Hopper



Ant



HalfCheetah



参考资料¶
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, Sergey Levine. Diversity is All You Need: Learning Skills without a Reward Function. arXiv:1802.06070.