NGU¶
概述¶
NGU(Never Give up) 首次在论文 Never Give Up: Learning Directed Exploration Strategies 中提出, 通过学习一组不同程度的探索策略(directed exploratory policies) 来解决探索困难的游戏。它定义的内在奖励分为2部分: 局内内在奖励(episodic intrinsic reward) 和 局间内在奖励(life-long/inter-episodic intrinsic reward)。
局内内在奖励 核心思想在于在同一局中迅速的抑制智能体再次访问相似的状态,这是通过维护一个存有一局历史样本 embedding 的 memory,然后根据与当前观测的 embedding 最相似的 k 个样本的距离计算得到 一个局内内在奖励值。这里的 embedding 期望它只包含环境观测中智能体动作能够影响的部分而去掉那些环境噪声,因此又称为 controllable state,它是通过训练一个自监督逆动力学模型来实现的。
局间内在奖励 核心思想在于缓慢的抑制智能体访问那些历史局中已经多次访问过的状态,采用 RND 内在奖励来实现此功能。 接着局内内在奖励和局间内在奖励通过相乘的方式融合为新的的内在奖励,然后乘以一个内在奖励的权重 beta,再加上原始外在奖励,作为最终的奖励。
NGU使用一个神经网络(Q 函数)同时学习一组不同程度的探索策略(即具有不同的奖励折扣因子gamma和内在奖励权重beta),在探索和利用之间进行不同程度的权衡。 所提出的方法与现代分布式 RL 算法 R2D2 结合,通过在不同环境实例上并行运行一组collector 收集大量经验,加速收集与训练过程。 在我们的实现中,在收集样本的过程中,每一局开始时随机采样一个 gamma 和 beta,且对于不同环境实例具有不同的固定的 epsilon。 NGU 在 Atari-57 中的所有难于探索的任务中性能翻倍,同时在其余游戏中保持非常高的分数,其人类标准化分的中位数为1344.0%。 作者称 NGU 是第一个在不使用专家轨迹和手工设计特征的情况下,在 Pitfall 游戏中实现非零奖励(平均得分为 8400)的算法。
核心要点¶
NGU 的基线强化学习算法是 R2D2 ,可以参考我们的实现 r2d2 ,它本质上是一个基于分布式框架,采用了双 Q 网络, dueling 结构,n-step td 的 DQN 算法。
NGU 是一种结合了局内内在奖励和局间内在奖励,并利用一组具有不同折扣因子和融合系数的的探索强化学习方法,(其中局内内在奖励对应论文 ICM 局间内在奖励对应论文 RND )的探索方法。
局间内在奖励(RND 奖励)。通过设置一个固定且随机初始化的目标网络作为预测问题,用智能体收集的数据去学习另一个预测器网络来拟合随机网络的输出,如果当前状态,之前已经见过很多次,为了探索,那么它对应的内在 奖励就应该小一些,具体怎么衡量,则是正比于前述 2 个网络输出值的误差。因为在整个状态空间里,如果某个状态区域之前收集数据比较多,也即用于训练预测器网络比较多,那么在此状态区域里,误差会小一些。
局内内在奖励(ICM 奖励)。首先它通过训练一个自监督逆动力学模型,即用 t 时刻和 t+1 时刻的状态观测来预测 t 时刻的动作,然后取出其中的embedding 网络用于将原始状态观测映射为一个 controllable state, 期望它只包含环境状态观测中智能体动作能够影响的部分而去掉那些环境噪声。 然后在一局中维护一个内存表,存着已经访问过的状态观测对应的的 controllable state,然后根据与当前状态观测最相似的k个controllable state 的距离计算得到一个局内内在奖励。
NGU 通过在不同环境实例(actor)上并行运行收集大量经验,在收集游戏轨迹的过程中,每一局开始时从均匀分布的集合中随机采样一个奖励折扣因子 gamma 和内在奖励的权重 beta,这个集合的大小N可变,确定了探索策略的 数量,一般取 32。此外,在我们的实现中,不同环境实例具有不同的固定的 epsilon。
局内内在奖励(ICM奖励)的不同归一化方式对结果影响极大,而且在 minigrid 任务中,我们还对一局最后一个非零的原始奖励乘以一个正比于一局步数的权重,以避免内在奖励对 minigrid 原始目标的影响,详见实现细节。
关键方程或关键框图¶
NGU 算法的整体训练与计算流程如下:

图中左边部分是逆向动力学模型的训练框架,右边部分是局间内在奖励(RND 奖励)和局内内在奖励(ICM 奖励)的产生与融合示意图。
局间内在奖励和局内内在奖励的融合公式:
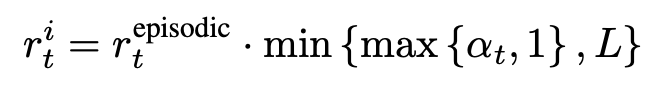
N组奖励折扣因子和内在奖励权重系数的分布图如下所示:
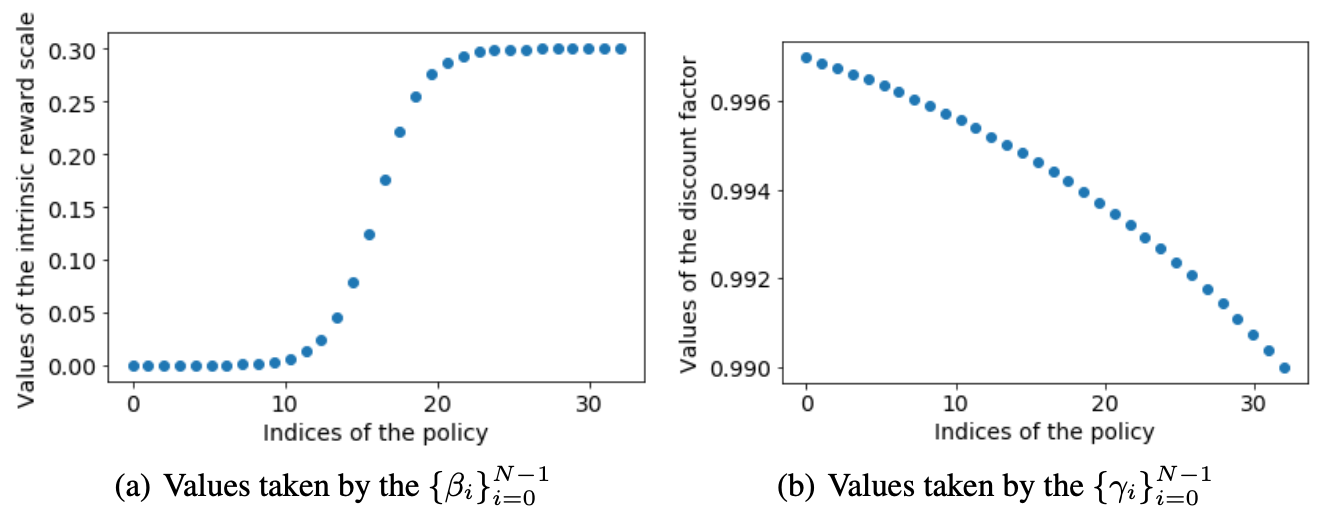
图中左边部分是内在奖励权重系数 beta,右边部分是奖励折扣因子 gamma, 他们的具体计算公式如下图所示。
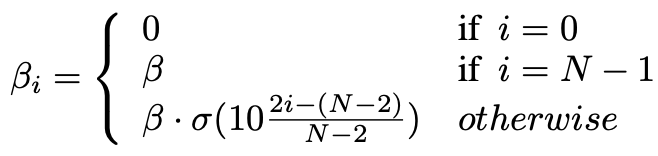
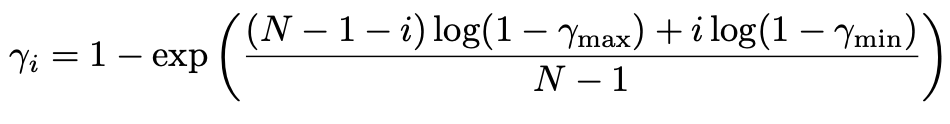
伪代码¶
以下为局内内在奖励的伪代码:

关于 r2d2 算法的细节,请参考 Recurrent Experience Replay in Distributed Reinforcement Learning 和我们的实现 r2d2 。
重要的实现细节¶
1. 奖励归一化。在通过上面所述的算法计算得到局内内在奖励后,由于在智能体学习的不同阶段和不同的环境下,它的幅度是变化剧烈的,如果直接用作后续的计算,很容易造成学习的不稳定。在我们 的实现中,是按照下面的最大最小归一化公式 归一化到 [0,1] 之间:
episodic_reward = (episodic_reward - episodic_reward.min()) / (episodic_reward.max() - episodic_reward.min() + 1e-11),
其中 episodic_reward 是一个 mini-batch 计算得到的局内内在奖励。我们也分析了其他归一化方式的效果。
方法1: transform to batch mean1: erbm1。 由于我们的实现中批数据里面可能会有null_padding的样本(注意null_padding样本的原始归一化前的 episodic reward=0),造成episodic_reward.mean() 不是真正的均值,需要特别处理计算得到真实的均值 episodic_reward_real_mean, 这给代码实现造成了额外的复杂度,此外这种方式不能将局内内在奖励的幅度限制在一定范围内,造成内在奖励的加权系数不好确定。 .. code:
episodic_reward = episodic_reward / (episodic_reward.mean() + 1e-11)方法2. transform to long-term mean1: erlm1。 存在和方法1类似的问题 .. code:
episodic_reward = episodic_reward / self._running_mean_std_episodic_reward.mean方法3. transform to mean 0, std 1。 由于 rnd_reward在[1,5]集合内, episodic reward 应该大于0,例如如果 episodic_reward 是 -2, rnd_reward 越大, 总的intrinsic reward 却越小, 这是不正确的 .. code:
episodic_reward = (episodic_reward - self._running_mean_std_episodic_reward.mean)/ self._running_mean_std_episodic_reward.std方法4. transform to std1, 似乎没有直观的意义。 .. code:
episodic_reward = episodic_reward / self._running_mean_std_episodic_reward.std
2. 在 minigrid 环境上,由于环境设置只有在智能体达到目标位置时,智能体才获得一个正的 0 到 1 之间的奖励,其他时刻奖励都为零,在这种环境上累计折扣内在奖励的幅度会远大于原始的0,1之间的数,造成 智能体学习的目标偏差太大,为了缓解这个问题,我们在实现中对每一局的最后一个非零的奖励乘上一个权重因子,实验证明如果不加这个权重因子,在最简单的 empty8 环境上算法也不能收敛,这显示了原始 外在奖励和内在奖励之间相对权重的重要性。
3.在局内奖励模型(episodic reward model)中需要维护保存一局中所有历史观测的 memory,由于我们在实现时不是实时计算出其局内内在奖励的,而是在收集完一批数据样本后,存在 replay_buffer 中, 然后从 replay_buffer 中采样一个 mini-batch 的序列样本用来计算每个状态观测的局内内在奖励,因此需要设置序列长度(sequence length)近似等于完成一局的长度(trajectory length)。 由于收集的数据中含有 null_padding 的样本,在训练 episodic/rnd 奖励模型时,需要首先舍弃无意义的 null_padding 样本。 episodic/rnd 内在奖励模型训练时 batch_size 应设置足够大(例如 320)时,训练更稳定。 replay_buffer需要先copy.deepcopy(train_data), 再修改样本的奖励为原始外在奖励加上内在奖励, 否则会导致下次从 replay_buffer 采样同一个样本时一直累加其内在奖励。
实现¶
局间内在奖励模型( RndNGURewardModel )的接口定义如下:
- class ding.reward_model.ngu_reward_model.RndNGURewardModel(config: EasyDict, device: str, tb_logger: SummaryWriter)[source]
- Overview:
inter-episodic/RND reward model for NGU. The corresponding paper is never give up: learning directed exploration strategies.
- __init__(config: EasyDict, device: str, tb_logger: SummaryWriter) None[source]
- estimate(data: list) Tensor[source]
Rewrite the reward key in each row of the data.
局内内在奖励模型( EpisodicNGURewardModel )的接口定义如下:
- class ding.reward_model.ngu_reward_model.EpisodicNGURewardModel(config: EasyDict, device: str, tb_logger: SummaryWriter)[source]
- Overview:
Episodic reward model for NGU. The corresponding paper is never give up: learning directed exploration strategies.
- __init__(config: EasyDict, device: str, tb_logger: SummaryWriter) None[source]
- estimate(data: list) Tensor[source]
Rewrite the reward key in each row of the data.
NGU的接口定义如下,它相对于 r2d2 主要有以下几个改动,首先网络的输入除了时刻 t 的状态观测外,还增加了时刻 t-1 的动作,外在奖励,和beta,在实现时动作和 beta 我们都转化成了相应的 one-hot 向量.
- class ding.policy.ngu.NGUPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of NGU. The corresponding paper is never give up: learning directed exploration strategies.
- Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
dqn
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cudabool
False
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policybool
False
Whether the RL algorithm is on-policyor off-policy4
prioritybool
False
Whether use priority(PER)Priority sample,update priority5
priority_IS_weightbool
False
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factorfloat
0.997, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstepint
3, [3, 5]
N-step reward discount sum for targetq_value estimation8
burnin_stepint
2
The timestep of burnin operation,which is designed to RNN hidden statedifference caused by off-policy9
learn.updateper_collectint
1
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy10
learn.batch_sizeint
64
The number of samples of an iteration11
learn.learning_ratefloat
0.001
Gradient step length of an iteration.12
learn.value_rescalebool
True
Whether use value_rescale function forpredicted value13
learn.target_update_freqint
100
Frequence of target network update.Hard(assign) update14
learn.ignore_donebool
False
Whether ignore done for target valuecalculation.Enable it for somefake termination env15
collect.n_sampleint
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs16
collect.unroll_lenint
1
unroll length of an iterationIn RNN, unroll_len>1
注意:... 表示省略的代码片段。 完整代码请参考我们的在DI-engine中的
实现 。
RndNetwork/InverseNetwork¶
首先,我们定义类 RndNetwork 涉及两个神经网络:固定和随机初始化的目标网络 self.target ,
和预测网络 self.predictor 根据代理收集的数据进行训练。我们定义类 InverseNetwork 也分为 2 个部分:self.embedding_net 负责将原始观测映射到隐空间,
和 self.inverse_net 根据t时刻观测和t+1时刻观测的 embedding ,预测 t 时刻的动作。
class RndNetwork(nn.Module):
def __init__(self, obs_shape: Union[int, SequenceType], hidden_size_list: SequenceType) -> None:
super(RndNetwork, self).__init__()
if isinstance(obs_shape, int) or len(obs_shape) == 1:
self.target = FCEncoder(obs_shape, hidden_size_list)
self.predictor = FCEncoder(obs_shape, hidden_size_list)
elif len(obs_shape) == 3:
self.target = ConvEncoder(obs_shape, hidden_size_list)
self.predictor = ConvEncoder(obs_shape, hidden_size_list)
else:
raise KeyError(
"not support obs_shape for pre-defined encoder: {}, please customize your own RND model".
format(obs_shape)
)
for param in self.target.parameters():
param.requires_grad = False
def forward(self, obs: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
predict_feature = self.predictor(obs)
with torch.no_grad():
target_feature = self.target(obs)
return predict_feature, target_feature
class InverseNetwork(nn.Module):
def __init__(self, obs_shape: Union[int, SequenceType], action_shape, hidden_size_list: SequenceType) -> None:
super(InverseNetwork, self).__init__()
if isinstance(obs_shape, int) or len(obs_shape) == 1:
self.embedding_net = FCEncoder(obs_shape, hidden_size_list)
elif len(obs_shape) == 3:
self.embedding_net = ConvEncoder(obs_shape, hidden_size_list)
else:
raise KeyError(
"not support obs_shape for pre-defined encoder: {}, please customize your own RND model".
format(obs_shape)
)
self.inverse_net = nn.Sequential(
nn.Linear(hidden_size_list[-1] * 2, 512), nn.ReLU(inplace=True), nn.Linear(512, action_shape)
)
def forward(self, inputs: Dict, inference: bool = False) -> Dict:
if inference:
with torch.no_grad():
cur_obs_embedding = self.embedding_net(inputs['obs'])
return cur_obs_embedding
else:
# obs: torch.Tensor, next_obs: torch.Tensor
cur_obs_embedding = self.embedding_net(inputs['obs'])
next_obs_embedding = self.embedding_net(inputs['next_obs'])
# get pred action
obs_plus_next_obs = torch.cat([cur_obs_embedding, next_obs_embedding], dim=-1)
pred_action_logits = self.inverse_net(obs_plus_next_obs)
pred_action_probs = nn.Softmax(dim=-1)(pred_action_logits)
return pred_action_logits, pred_action_probs
内在奖励计算¶
关于 RndNGURewardModel/EpisodicNGURewardModel 的训练部分请参考 ngu_reward_model .
这里主要展示是如何根据已经训练好的模型计算局内内在奖励(episodic reward)和局外内在奖励(rnd reward)。
1.episodic reward 在我们在类
EpisodicNGURewardModel的方法_compute_intrinsic_reward中实现根据当前的episodic_memory计算得到当前状态的局内内在奖励。def _compute_intrinsic_reward( self, episodic_memory: List, current_controllable_state: torch.Tensor, k=10, kernel_cluster_distance=0.008, kernel_epsilon=0.0001, c=0.001, siminarity_max=8, ) -> torch.Tensor: # this function is modified from https://github.com/Coac/never-give-up/blob/main/embedding_model.py state_dist = torch.cdist(current_controllable_state.unsqueeze(0), episodic_memory, p=2).squeeze(0).sort()[0][:k] self._running_mean_std_episodic_dist.update(state_dist.cpu().numpy()) state_dist = state_dist / (self._running_mean_std_episodic_dist.mean + 1e-11) state_dist = torch.clamp(state_dist - kernel_cluster_distance, min=0, max=None) kernel = kernel_epsilon / (state_dist + kernel_epsilon) s = torch.sqrt(torch.clamp(torch.sum(kernel), min=0, max=None)) + c if s > siminarity_max: print('s > siminarity_max:', s.max(), s.min()) return torch.tensor(0) return 1 / s2.我们是在收集一批样本后,从 replay buffer 中采样一个 mini-batch 的样本序列,调用上面的
_compute_intrinsic_reward计算局内内在奖励。def estimate(self, data: list) -> None: """ Rewrite the reward key in each row of the data. """ obs, is_null = collect_data_episodic(data) batch_size = len(obs) seq_length = len(obs[0]) # stack episode dim obs = [torch.stack(episode_obs, dim=0) for episode_obs in obs] # stack batch dim if isinstance(self.cfg.obs_shape, int): obs = torch.stack(obs, dim=0).view(batch_size * seq_length, self.cfg.obs_shape).to(self.device) else: # len(self.cfg.obs_shape) == 3 for image obs obs = torch.stack(obs, dim=0).view(batch_size * seq_length, *self.cfg.obs_shape).to(self.device) inputs = {'obs': obs, 'is_null': is_null} with torch.no_grad(): cur_obs_embedding = self.episodic_reward_model(inputs, inference=True) cur_obs_embedding = cur_obs_embedding.view(batch_size, seq_length, -1) episodic_reward = [[] for _ in range(batch_size)] for i in range(batch_size): for j in range(seq_length): if j < 10: episodic_reward[i].append(torch.tensor(0.).to(self.device)) elif j: episodic_memory = cur_obs_embedding[i][:j] reward = self._compute_intrinsic_reward(episodic_memory, cur_obs_embedding[i][j]).to(self.device) episodic_reward[i].append(reward) # if have null padding, the episodic_reward should be 0 if torch.nonzero(torch.tensor(is_null[i]).float()).shape[0] != 0: null_start_index = int(torch.nonzero(torch.tensor(is_null[i]).float()).squeeze(-1)[0]) for k in range(null_start_index, seq_length): episodic_reward[i][k] = torch.tensor(0).to(self.device) # list(list(tensor)) - > tensor # stack episode dim tmp = [torch.stack(episodic_reward_tmp, dim=0) for episodic_reward_tmp in episodic_reward] # stack batch dim episodic_reward = torch.stack(tmp, dim=0) episodic_reward = episodic_reward.view(-1) # torch.Size([32, 42]) -> torch.Size([32*42] # transform to [0,1]: er01 episodic_reward = (episodic_reward - episodic_reward.min()) / (episodic_reward.max() - episodic_reward.min() + 1e-11) return episodic_reward
计算局间内在奖励。
def estimate(self, data: list) -> None: """ Rewrite the reward key in each row of the data. """ obs, is_null = collect_data_rnd(data) if isinstance(obs[0], list): # if obs shape list( list(torch.tensor) ) obs = sum(obs, []) obs = torch.stack(obs).to(self.device) with torch.no_grad(): predict_feature, target_feature = self.reward_model(obs) reward = F.mse_loss(predict_feature, target_feature, reduction='none').mean(dim=1) self._running_mean_std_rnd.update(reward.cpu().numpy()) # transform to mean 1 std 1 reward = 1 + (reward - self._running_mean_std_rnd.mean) / (self._running_mean_std_rnd.std + 1e-11) self.estimate_cnt_rnd += 1 self.tb_logger.add_scalar('rnd_reward/rnd_reward_max', reward.max(), self.estimate_cnt_rnd) self.tb_logger.add_scalar('rnd_reward/rnd_reward_mean', reward.mean(), self.estimate_cnt_rnd) self.tb_logger.add_scalar('rnd_reward/rnd_reward_min', reward.min(), self.estimate_cnt_rnd) return reward
融合局内内在奖励和局外内在奖励¶
def fusion_reward(data, inter_episodic_reward, episodic_reward, nstep, collector_env_num, tb_logger, estimate_cnt): estimate_cnt += 1 index_to_beta = { i: 0.3 * torch.sigmoid(torch.tensor(10 * (2 * i - (collector_env_num - 2)) / (collector_env_num - 2))) for i in range(collector_env_num) } batch_size = len(data) seq_length = len(data[0]['reward']) device = data[0]['reward'][0].device intrinsic_reward_type = 'add' intrisic_reward = episodic_reward * torch.clamp(inter_episodic_reward, min=1, max=5) ... if not isinstance(data[0], (list, dict)): # not rnn based rl algorithm intrisic_reward = intrisic_reward.to(device) intrisic_reward = torch.chunk(intrisic_reward, intrisic_reward.shape[0], dim=0) for item, rew in zip(data, intrisic_reward): if intrinsic_reward_type == 'add': item['reward'] += rew * index_to_beta[data['beta']] else: # rnn based rl algorithm intrisic_reward = intrisic_reward.to(device) # tensor to tuple intrisic_reward = torch.chunk(intrisic_reward, int(intrisic_reward.shape[0]), dim=0) if len(data[0]['obs'][0].shape) == 3: # for env atari, obs is image last_rew_weight = 1 else: # foe env lularlander, minigrid last_rew_weight = seq_length # this is for the nstep rl algorithms for i in range(batch_size): # batch_size typically 64 for j in range(seq_length): # burnin+unroll_len is the sequence length, e.g. 100=2+98 if j < seq_length - nstep: intrinsic_reward = torch.cat([intrisic_reward[i * seq_length + j + k] for k in range(nstep)], dim=0) # if intrinsic_reward_type == 'add': if not data[i]['null'][j]: # if data[i]['null'][j]==True, means its's null data, only the not null data, # we add aintrinsic_reward reward if data[i]['done'][j]: # if not null data, and data[i]['done'][j]==True, so this is the last nstep transition # in the original data. for k in reversed(range(nstep)): # here we want to find the last nonzero reward in the nstep reward list: # data[i]['reward'][j], that is also the last reward in the sequence, here, # we set the sequence length is large enough, # so we can consider the sequence as the whole episode plus null_padding if data[i]['reward'][j][k] != 0: # find the last one that is nonzero, and enlarging <seq_length> times tmp = copy.deepcopy(data[i]['reward'][j][k]) data[i]['reward'][j] += intrinsic_reward * index_to_beta[int(data[i]['beta'][j])] data[i]['reward'][j][k] = last_rew_weight * tmp # substitute the kth reward in the list data[i]['reward'][j] with <seq_length> # times amplified reward break else: data[i]['reward'][j] += intrinsic_reward * index_to_beta[int(data[i]['beta'][j])] return data, estimate_cnt
基准算法性能¶
读者仔细思考可以发现NGU仍然存在一些问题:例如如何选择 N,将内在奖励和外在奖励分为 2 个 Q 网络来学习,如何自适应的奖励选择折扣因子和内在奖励权重系数。 有兴趣的读者可以阅读后续改进工作 Agent57: Outperforming the Atari Human Benchmark.
参考资料¶
Badia A P, Sprechmann P, Vitvitskyi A, et al. Never give up: Learning directed exploration strategies[J]. arXiv preprint arXiv:2002.06038, 2020.
Burda Y, Edwards H, Storkey A, et al. Exploration by random network distillation[J]. https://arxiv.org/abs/1810.12894v1. arXiv:1810.12894, 2018.
Pathak D, Agrawal P, Efros A A, et al. Curiosity-driven exploration by self-supervised prediction[C]//International conference on machine learning. PMLR, 2017: 2778-2787.
Kapturowski S, Ostrovski G, Quan J, et al. Recurrent experience replay in distributed reinforcement learning[C]//International conference on learning representations. 2018.