D4RL (MuJoCo)¶
概述¶
D4RL 是离线强化学习(offline Reinforcement Learning)的开源 benchmark,它为训练和基准算法提供标准化的环境和数据集。数据集的收集策略包含
通过手工设计的规则和专家演示生成的数据集
多任务数据集(代理在相同的环境中执行不同的任务)
使用混合策略收集的数据集
具体包含以下7个子环境
Maze2D
AntMaze
Gym-MuJoco
Adroit
FrankaKitchen
Flow
Offline CARLA
注意:offline rl 是训练用 d4rl 的数据集,测试是用具体的 RL 环境来交互,比如 Mujoco.
其中 Mujoco 数据集是旨在促进机器人、生物力学、图形和动画等需要快速准确模拟领域研究和开发的物理引擎,常来作为连续空间强化学习算法的基准测试环境。它是包含 20 个子环境的集合,在 D4RL 中,用到的子环境有 Half Cheetah, Hopper, Walker2D。 每个子环境包含5个小环境
expert: 在线训练一个SAC算法直到策略达到专家性能水平,使用该专家策略收集1百万的样本数据
medium-expert: 混合等量的专家策略和中等策略收集的数据
medium: 首先在线训练一个 SAC 算法,在中间停止训练,然后使用这个部分训练的策略收集1百万的样本数据
medium-replay:在线训练一个 SAC 算法直到策略达到中等性能水平,将训练期间放在缓冲区中的所有样本收集起来
random:使用一个随机初始化的策略来收集
下图所示为其中 Hopper 游戏。

安装¶
安装方法¶
安装 d4rl,gym 和 mujoco-py 库即可,其中 d4rl 可以通过 pip 一键安装或通过 clone 安装
# pip install
pip install git+https://github.com/rail-berkeley/d4rl@master#egg=d4rl
# installed by cloning the repository
git clone https://github.com/rail-berkeley/d4rl.git
cd d4rl
pip install -e .
mujoco 只要安装 gym 和 mujoco-py 两个库即可,可以通过 pip 一键安装或结合 DI-engine 安装
mujoco-py 库目前已不再需要激活许可(
mujoco-py>=2.1.0),可以通过pip install free-mujoco-py 安装如果安装
mujoco-py>=2.1, 可以通过如下方法:
# Installation for Linux
# Download the MuJoCo version 2.1 binaries for Linux.
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-linux-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
# Installation for macOS
# Download the MuJoCo version 2.1 binaries for OSX.
wget https://mujoco.org/download/mujoco210-macos-x86_64.tar.gz
# Extract the downloaded mujoco210 directory into ~/.mujoco/mujoco210.
tar xvf mujoco210-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco210 ~/.mujoco/mujoco210
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.2,>=2.1'
如果安装
mujoco-py<2.1, 可以通过如下方法:
# Installation for Linux
# Download the MuJoCo version 2.0 binaries for Linux.
wget https://www.roboti.us/download/mujoco200_linux.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
unzip mujoco200_linux.zip && mkdir -p ~/.mujoco && mv mujoco200_linux ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
# Installation for macOS
# Download the MuJoCo version 2.0 binaries for OSX.
wget https://www.roboti.us/download/mujoco200_macos.zip
# Extract the downloaded mujoco200 directory into ~/.mujoco/mujoco200.
tar xvf mujoco200-macos-x86_64.tar.gz && mkdir -p ~/.mujoco && mv mujoco200_macos ~/.mujoco/mujoco200
# Download unlocked activation key.
wget https://www.roboti.us/file/mjkey.txt -O ~/.mujoco/mjkey.txt
# Install and use mujoco-py
pip install gym
pip install -U 'mujoco-py<2.1'
验证安装¶
安装完成后,可以通过在 Python 命令行中运行如下命令验证安装成功:
import gym
import d4rl # Import required to register environments
# Create the environment
env = gym.make('maze2d-umaze-v1')
# d4rl abides by the OpenAI gym interface
env.reset()
env.step(env.action_space.sample())
# Each task is associated with a dataset
# dataset contains observations, actions, rewards, terminals, and infos
dataset = env.get_dataset()
print(dataset['observations']) # An N x dim_observation Numpy array of observations
# Alternatively, use d4rl.qlearning_dataset which
# also adds next_observations.
dataset = d4rl.qlearning_dataset(env)
镜像¶
DI-engine 准备好了配备有框架本身的镜像,可通过docker pull opendilab/ding:nightly-mujoco获取,或访问docker
hub获取更多镜像
Gym-MuJoco 变换前的空间(原始环境)¶
观察空间¶
物理信息组成的向量(3D position, orientation, and joint angles etc.),具体尺寸为
(N, ),其中N根据环境决定,数据类型为float64Fujimoto 提到,对于d4rl 数据集做 obs norm 会提升 offline 的训练稳定性
动作空间¶
物理信息组成的向量(torque etc.),一般是大小为N的连续动作空间(N随具体子环境变化),数据类型为
float32,需要传入 np 数组(例如动作为array([-0.9266078 , -0.4958926 , 0.46242517], dtype=float32))如在 Hopper 环境中,N 的大小为 3,动作在
[-1, 1]中取值
奖励空间¶
根据具体游戏内容不同,游戏得分会有非常大的差异,通常是一个 float 数值,具体的数值可以参考最下方的基准算法性能部分。
其他¶
游戏结束即为当前环境 episode 结束
关键事实¶
Vector 物理信息输入,经验上做 norm 中不宜减去均值
连续动作空间
稠密奖励
奖励取值尺度变化较大
变换后的空间(RL 环境)¶
观察空间¶
基本无变换
动作空间¶
基本无变换,依然是大小为N的连续动作空间,取值范围
[-1, 1],尺寸为(N, ),数据类型为np.float32
奖励空间¶
基本无变换
上述空间使用 gym 环境空间定义则可表示为:
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(11, ), dtype=np.float64)
act_space = gym.spaces.Box(low=-1, high=1, shape=(3, ), dtype=np.float32)
rew_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(1, ), dtype=np.float32)
其他¶
环境
step方法返回的info必须包含eval_episode_return键值对,表示整个episode的评测指标,在 Mujoco 中为整个episode的奖励累加和
其他¶
惰性初始化¶
为了便于支持环境向量化等并行操作,环境实例一般实现惰性初始化,即__init__方法不初始化真正的原始环境实例,只是设置相关参数和配置值,在第一次调用reset方法时初始化具体的原始环境实例。
存储录像¶
在环境创建之后,重置之前,调用enable_save_replay方法,指定游戏录像保存的路径。环境会在每个 episode 结束之后自动保存本局的录像文件。(默认调用gym.wrappers.RecordVideo实现 ),下面所示的代码将运行一个环境 episode,并将这个 episode 的结果保存在./video/中:
from easydict import EasyDict
from dizoo.mujoco.envs import MujocoEnv
env = MujocoEnv(EasyDict({'env_id': 'Hoopper-v3' }))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
DI-zoo 可运行代码示例¶
完整的训练配置文件在 github link
内,对于具体的配置文件,例如https://github.com/opendilab/DI-engine/blob/main/dizoo/d4rl/config/hopper_medium_cql_default_config.py,使用如下的 demo 即可运行:
from easydict import EasyDict
from easydict import EasyDict
hopper_medium_cql_default_config = dict(
env=dict(
env_id='hopper-medium-v0',
norm_obs=dict(use_norm=False, ),
norm_reward=dict(use_norm=False, ),
collector_env_num=1,
evaluator_env_num=8,
use_act_scale=True,
n_evaluator_episode=8,
stop_value=6000,
),
policy=dict(
cuda=True,
model=dict(
obs_shape=11,
action_shape=3,
twin_critic=True,
actor_head_type='reparameterization',
actor_head_hidden_size=256,
critic_head_hidden_size=256,
),
learn=dict(
data_path=None,
train_epoch=30000,
batch_size=256,
learning_rate_q=3e-4,
learning_rate_policy=1e-4,
learning_rate_alpha=1e-4,
ignore_done=False,
target_theta=0.005,
discount_factor=0.99,
alpha=0.2,
reparameterization=True,
auto_alpha=False,
lagrange_thresh=-1.0,
min_q_weight=5.0,
),
collect=dict(
n_sample=1,
unroll_len=1,
data_type='d4rl',
),
command=dict(),
eval=dict(evaluator=dict(eval_freq=500, )),
other=dict(replay_buffer=dict(replay_buffer_size=2000000, ), ),
),
)
hopper_medium_cql_default_config = EasyDict(hopper_medium_cql_default_config)
main_config = hopper_medium_cql_default_config
hopper_medium_cql_default_create_config = dict(
env=dict(
type='d4rl',
import_names=['dizoo.d4rl.envs.d4rl_env'],
),
env_manager=dict(type='base'),
policy=dict(
type='cql',
import_names=['ding.policy.cql'],
),
replay_buffer=dict(type='naive', ),
)
hopper_medium_cql_default_create_config = EasyDict(hopper_medium_cql_default_create_config)
create_config = hopper_medium_cql_default_create_config
注:对于offline RL的算法,比如TD3_bc,CQL,需要使用专门的入口函数,示例可以参考 link
基准算法性能¶
Walker2d
walker2d-medium-expert-v0 + CQL
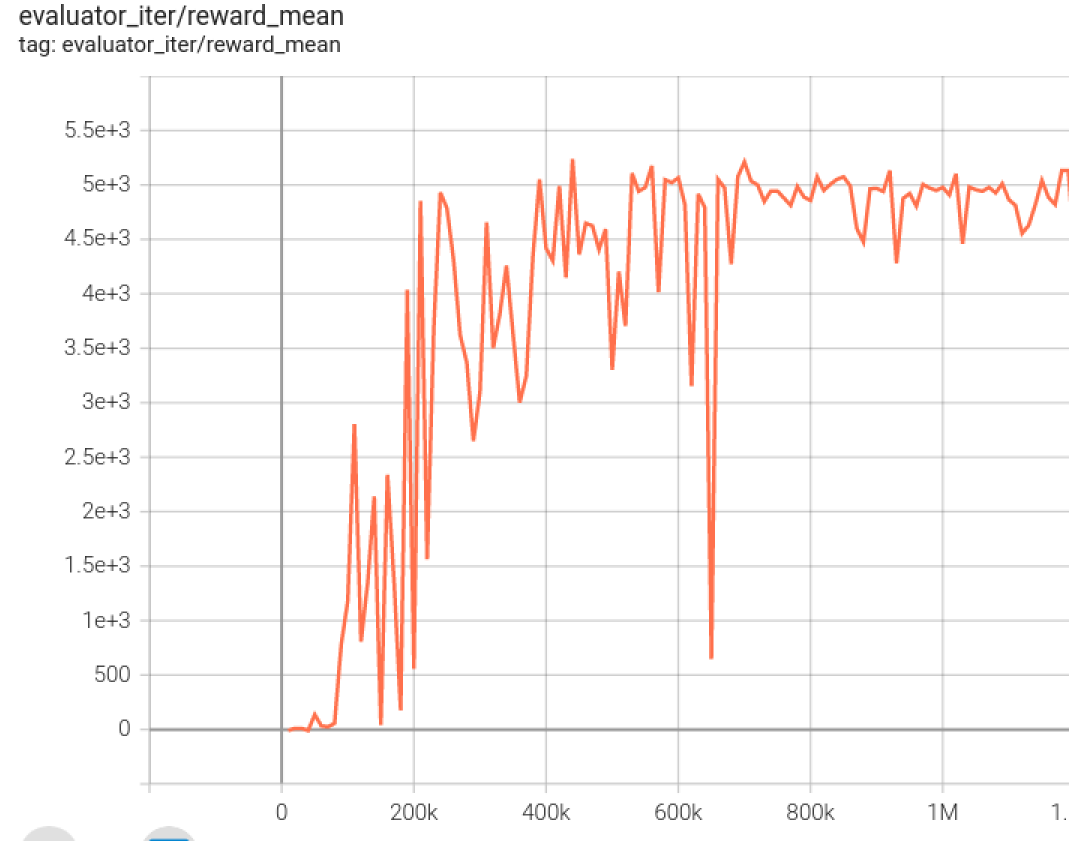
一般迭代1M iteration 需要 9 小时(NVIDIA V100)