Google Research Football (Gfootball)¶
概述¶
Google Research Football(以下简称 Gfootball)是 Google 团队在开源足球游戏 GamePlay Football的基础上创建的适用于强化学习研究的足球环境, 兼容 OpenAI Gym API,不仅可用于智能体训练,也允许玩家以键盘或手柄输入与内置AI或训练的智能体进行游戏。下图为渲染后的 Gfootball 游戏环境。
安装¶
依赖包
Linux
sudo apt-get install git cmake build-essential libgl1-mesa-dev libsdl2-dev \
libsdl2-image-dev libsdl2-ttf-dev libsdl2-gfx-dev libboost-all-dev \
libdirectfb-dev libst-dev mesa-utils xvfb x11vnc python3-pip
python3 -m pip install --upgrade pip setuptools psutil wheel
MacOS
brew install git python3 cmake sdl2 sdl2_image sdl2_ttf sdl2_gfx boost boost-python3
python3 -m pip install --upgrade pip setuptools psutil wheel
Windows
python -m pip install --upgrade pip setuptools psutil wheel
安装gfootball环境
pip安装
python3 -m pip install gfootball
从github源码安装
git clone https://github.com/google-research/football.git
cd football
python3 -m pip install .
环境安装的验证
python3 -m gfootball.play_game --action_set=full
进入如下游戏界面,证明安装成功。
更多安装环境相关的问题,可以参考Gfootball 官网 github。此外,官方也提供了 docker image 用于在 docker 环境中部署环境,可以参考 docker 部署文档 。
环境创建API¶
在导入并创建环境成功后,可以通过与 openAI gym 相同的代码来与环境交互:
import gfootball.env as football_env
env = football_env.create_environment(
env_name='11_vs_11_stochastic',
representation='raw',
stacked=False,
logdir='/tmp/football',
write_goal_dumps=False,
write_full_episode_dumps=False,
write_video=False,
render=False,
number_of_right_players_agent_controls=1
)
env.reset()
obs = env.observations()
action = get_action(obs) # your model
next_obs, reward, done, info = env.step(action)
创建环境的API如下:
env name。核心参数,决定环境创建的场景,常用为 11 vs 11 stochastic,11 vs 11 easy stochastic,11 vs 11 hard stochastic,分别对应对局中等、简单和困难三种难度内置bot的完整90分钟足球游戏。此外,还有点球等场景如 academy run pass and shoot with keeper,详见 文档 。
Representation。环境输出的表征类型,raw 为原始向量输入,如球员位置、球速度等信息,pixels 为原始图像像素输入,官方还提供了一些现有的环境输入封装。
stacked。是否堆叠帧输入。
logdir。日志文件的保存路径。
write_goal_dumps。是否保存进球时的二进制文件用于生成录像回放。
write_full_episode_dumps。是否保存全程的二进制文件用于生成录像回放。
write_video。是否生成渲染的全程视频。
render。是否实时渲染。
number_of_right_players_agent_controls。选择同时控制的球员数目。
也可以使用由 DI-engine 封装的环境:
### 对局内置bot环境
from dizoo.gfootball.envs.gfootball_env import GfootballEnv
env = GfootballEnv({})
### self play 环境
from dizoo.gfootball.envs.gfootballsp_env import GfootballEnv
env = GfootballEnv({})
状态空间¶
一般使用raw输入信息
球信息:
ball- [x, y, z] 坐标。ball_direction- [x, y, z]球的速度方向。ball_rotation- [x, y, z] 球的旋转方向。ball_owned_team- {-1, 0, 1}, -1 = 球不被球队持有, 0 = 左队, 1 = 右队。ball_owned_player- {0..N-1} 表明球被哪个队员持有。
左队信息:
left_team- N*2维向量 [x, y],表明球员位置。left_team_direction- N*2 维向量 [x, y],表明球员速度方向。left_team_tired_factor- N 维向量 ,表明球员疲劳度. 0表示完全不疲劳。left_team_yellow_card- N 维向量,表明球员是否有黄牌。left_team_active- N 维向量,表明球员是否没有红牌.left_team_roles- N 维向量,表明球员角色:0= ePlayerRoleGK - goalkeeper,1= ePlayerRoleCB - centre back,2= ePlayerRoleLB - left back,3= ePlayerRoleRB - right back,4= ePlayerRoleDM - defence midfield,5= ePlayerRoleCM - central midfield,6= ePlayerRoleLM - left midfield,7= ePlayerRoleRM - right midfield,8= ePlayerRoleAM - attack midfield,9= ePlayerRoleCF - central front,
右队信息:与左队对称
控制球员信息:
active- {0..N-1} 表明控制球员号码。designated- {0..N-1} 表明带球球员号码。sticky_actions- 10维向量表明如下动作是否可执行:0-action_left1-action_top_left2-action_top3-action_top_right4-action_right5-action_bottom_right6-action_bottom7-action_bottom_left8-action_sprint9-action_dribble
比赛信息
score- 得分.steps_left- 剩余步数(全局比赛 3000 步).game_mode - 比赛状态信息:
0=e_GameMode_Normal1=e_GameMode_KickOff2=e_GameMode_GoalKick3=e_GameMode_FreeKick4=e_GameMode_Corner5=e_GameMode_ThrowIn6=e_GameMode_Penalty
图像:RGB的游戏图像信息。
DI-engine封装的状态空间
Players: 29 维avail,可行动作(10 维 one-hot,长传、高脚、短传、射门、冲刺、停止运动、停止冲刺、滑铲、运球、停止运球)(参考#6)[player_pos_x, player_pos_y],当前控制球员位置(2 维坐标)player_direction*100,当前控制球员运动方向(2 维坐标)*player_speed*100,当前控制球员速度(1 维标量)layer_role_onehot,当前控制球员角色(10 维one-hot)[ball_far, player_tired, is_dribbling, is_sprinting],球是否过远,当前控制球员疲劳度,是否在带球、是否在冲刺(4 维 0/1)
Ball: 18维obs['ball'],球位置(3 维坐标)ball_which_zone,人为划定的球所在区域(6 维 one-hot)[ball_x_relative, ball_y_relative],球距离当前控制球员的x、y轴距离(2 维)obs['ball_direction']*20,球运动方向(3 维坐标)*[ball_speed*20, ball_distance, ball_owned, ball_owned_by_us],球速,球与当前控制球员的距离,球是否被控制、球是否被我方控制(4 维)
LeftTeam: 7维。所有我方球员的下述信息(10*7)LeftTeamCloset:7 维离当前控制球员最近我方球员的位置(2 维)
离当前控制球员最近我方球员的速度向量(2 维)
当前控制球员最近我方球员的速度(1 维)
当前控制球员最近我方球员的距离(1 维)
离当前控制球员最近我方球员的疲劳度(1 维)
RightTeam:7 维。所有对方球员的下述信息(11*7)RightTeamCloset:7 维离当前控制球员最近对方球员的位置(2 维)
离当前控制球员最近对方球员的速度向量(2 维)
离当前控制球员最近对方球员的速度(1 维)
离当前控制球员最近对方球员的距离(1 维)
离当前控制球员最近对方球员的疲劳度(1 维)
动作空间¶
Gfootball 的动作空间为 19 维离散动作:
无状态动作
action_idle= 0, 空动作。
移动动作(均为粘滞动作)
action_left= 1, 向左。action_top_left= 2, 向右上。action_top= 3, 向上。action_top_right= 4, 向右上。action_right= 5, 向右。action_bottom_right= 6, 向右下。action_bottom= 7, 向下。action_bottom_left= 8, 向左下。
传球/射门动作
action_long_pass= 9, 长传。action_high_pass= 10, 高传球。action_short_pass= 11, 短传。action_shot= 12, 射门。
其它
action_sprint= 13, 冲刺。action_release_direction= 14, 释放粘滞动作(如移动)。action_release_sprint= 15, 停止冲刺.action_sliding= 16, 滑铲(仅无球时可用).action_dribble= 17, 运球.action_release_dribble= 18, 停止运球.
DI-zoo可运行代码示例¶
完整的训练入口见DI-zoo gfootball。使用 ppo-lstm 进行self-play 训练的配置文件如下。
from easydict import EasyDict
from ding.config import parallel_transform
from copy import deepcopy
from ding.entry import parallel_pipeline
gfootball_ppo_config = dict(
env=dict(
collector_env_num=1,
collector_episode_num=1,
evaluator_env_num=1,
evaluator_episode_num=1,
stop_value=5,
save_replay=False,
render=False,
),
policy=dict(
cuda=False,
model=dict(type='conv1d', import_names=['dizoo.gfootball.model.conv1d.conv1d']),
nstep=1,
discount_factor=0.995,
learn=dict(
batch_size=32,
learning_rate=0.001,
learner=dict(
learner_num=1,
send_policy_freq=1,
),
),
collect=dict(
n_sample=20,
env_num=1,
collector=dict(
collector_num=1,
update_policy_second=3,
),
),
eval=dict(evaluator=dict(eval_freq=50), env_num=1),
other=dict(
eps=dict(
type='exp',
start=0.95,
end=0.1,
decay=100000,
),
replay_buffer=dict(
replay_buffer_size=100000,
enable_track_used_data=True,
),
commander=dict(
collector_task_space=2,
learner_task_space=1,
eval_interval=5,
league=dict(),
),
),
)
)
gfootball_ppo_config = EasyDict(gfootball_ppo_config)
main_config = gfootball_ppo_config
gfootball_ppo_create_config = dict(
env=dict(
import_names=['dizoo.gfootball.envs.gfootballsp_env'],
type='gfootball_sp',
),
env_manager=dict(type='base'),
policy=dict(type='ppo_lstm_command', import_names=['dizoo.gfootball.policy.ppo_lstm']),
learner=dict(type='base', import_names=['ding.worker.learner.base_learner']),
collector=dict(
type='marine',
import_names=['ding.worker.collector.marine_parallel_collector'],
),
commander=dict(
type='one_vs_one',
import_names=['ding.worker.coordinator.one_vs_one_parallel_commander'],
),
comm_learner=dict(
type='flask_fs',
import_names=['ding.worker.learner.comm.flask_fs_learner'],
),
comm_collector=dict(
type='flask_fs',
import_names=['ding.worker.collector.comm.flask_fs_collector'],
),
)
gfootball_ppo_create_config = EasyDict(gfootball_ppo_create_config)
create_config = gfootball_ppo_create_config
gfootball_ppo_system_config = dict(
path_data='./data',
path_policy='./policy',
communication_mode='auto',
learner_multi_gpu=False,
learner_gpu_num=1,
coordinator=dict()
)
gfootball_ppo_system_config = EasyDict(gfootball_ppo_system_config)
system_config = gfootball_ppo_system_config
if __name__ == '__main__':
config = tuple([deepcopy(main_config), deepcopy(create_config), deepcopy(system_config)])
parallel_pipeline(config, seed=0)
训练实例¶
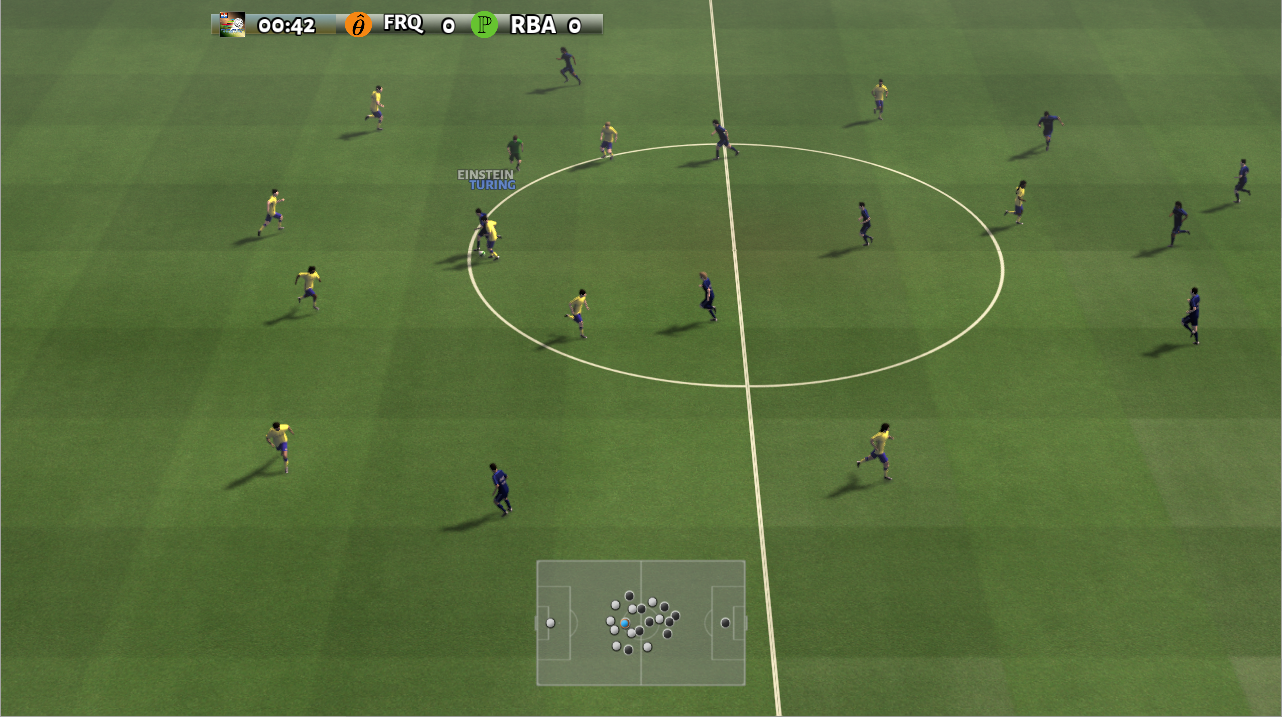
在 DI-engine 的状态空间下,经过 reward 设计和动作空间约束,self play 训练中对内置 hard AI 胜率曲线如下图所示: