Taxi¶
概述¶
Taxi 环境是一个离散空间的经典的强化学习环境,它模拟了一个乘客在城市中的出行过程。在这个环境中,汽车需要从一个位置出发,到指定地点去接一个乘客,然后将乘客成功送达另一个位置。Taxi 环境展示如下图所示:

安装¶
安装方法¶
Taxi 环境在 gym 中就可以直接调用。其环境的 id 是 Taxi-v3 。
pip install gym
验证安装¶
在 Python 中运行如下命令,验证安装成功
import gym
from gym.spaces import Discrete
env = gym.make("Taxi-v3", render_mode="rgb_array")
obs = env.reset()
print(obs)
assert env.observation_space == Discrete(500)
assert env.action_space == Discrete(6)
环境介绍¶
动作空间¶
Taxi 的动作空间属于离散动作空间,动作形状为 (1, ) , 范围为 {0, 5} ,表示对汽车不同的操作。
0: 向下移动1: 向上移动2: 向右移动3: 向左移动4: 接乘客5: 甩乘客
在 gym 环境空间的定义之下表示为
action_space = gym.spaces.Discrete(6)
状态空间¶
状态空间同样是离散的空间,和动作空间一样状态形状为 (1, ) , 范围为 {0, 499},共 500 个状态。
Taxi 环境背景是个 5×5 大小的地图,地图中有 4 块带有颜色标识的位置。乘客的起点在这 4 块颜色标识的位置之一,或者是在车里;乘客的终点也是在 4 块带有颜色标识的位置之一。一共有 500 个状态。这 500 个状态是综合汽车和乘客二者的状态汇总的。在 gym 的空间环境定义下表示为
observation_space = gym.spaces.Discrete(500)
500 个状态中每个状态由下列 4 个信息而定。可通过如下方式查看每个状态编码的数字对应的各个信息
obs = env.reset()
taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(obs)
其中每个元素的范围如下
taxi_row: 汽车位置的行,在 0, 1, 2, 3, 4 之间,代表行的索引taxi_col: 汽车位置的列,在 0, 1, 2, 3, 4 之间,代表列的索引pass_loc: 乘客初始状态,在 0, 1, 2, 3, 4 之间。其中 0, 1, 2, 3 分别代表在 红、绿、黄、蓝 位置,4 代表乘客在车里dest_idx: 乘客的目的地,在 0, 1, 2, 3 之间,分别代表 红、绿、黄、蓝 四个位置
状态空间的值通过如下方式计算,即 (`` taxi_row * 100 + taxi_col * 20 + pass_loc * 4 + dest_idx * 1`` )
奖励空间¶
-1: 汽车正常行动一次 (汽车到乘客出发点正常接客也算一次)-10: 汽车非正常情况下接客甩客 (包含:未在乘客出发点就接客、车上有乘客时还接客、车上无乘客时甩客,甩客时车不在目的地)+20: 汽车成功将乘客送达目的地
终止条件¶
Taxi 环境下,每个 episode 终止条件是遇到下列任何一种情况:
成功送达乘客。也即如果 step 没有限制,那么只有成功送达了乘客,才能终止。
达到 episode 的最大 step。可以通过设置
env中变量max_episode_steps
DI-zoo 可运行代码示例¶
如下为基于 DQN 基础算法进行实现,详细文件位置在 dizoo\taxi\config\taxi_dqn_config.py,运行如下代码:
from easydict import EasyDict
taxi_dqn_config = dict(
exp_name='taxi_dqn_seed0',
env=dict(
collector_env_num=8,
evaluator_env_num=8,
n_evaluator_episode=8,
stop_value=20,
max_episode_steps=60,
env_id="Taxi-v3"
),
policy=dict(
cuda=True,
model=dict(
obs_shape=34,
action_shape=6,
encoder_hidden_size_list=[128, 128]
),
random_collect_size=5000,
nstep=3,
discount_factor=0.99,
learn=dict(
update_per_collect=10,
batch_size=64,
learning_rate=0.0001,
learner=dict(
hook=dict(
log_show_after_iter=1000,
)
),
),
collect=dict(n_sample=32),
eval=dict(evaluator=dict(eval_freq=1000, )),
other=dict(
eps=dict(
type="linear",
start=1,
end=0.05,
decay=3000000
),
replay_buffer=dict(replay_buffer_size=100000,),
),
)
)
taxi_dqn_config = EasyDict(taxi_dqn_config)
main_config = taxi_dqn_config
taxi_dqn_create_config = dict(
env=dict(
type="taxi",
import_names=["dizoo.taxi.envs.taxi_env"]
),
env_manager=dict(type='base'),
policy=dict(type='dqn'),
replay_buffer=dict(type='deque', import_names=['ding.data.buffer.deque_buffer_wrapper']),
)
taxi_dqn_create_config = EasyDict(taxi_dqn_create_config)
create_config = taxi_dqn_create_config
if __name__ == "__main__":
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), max_env_step=3000000, seed=0)
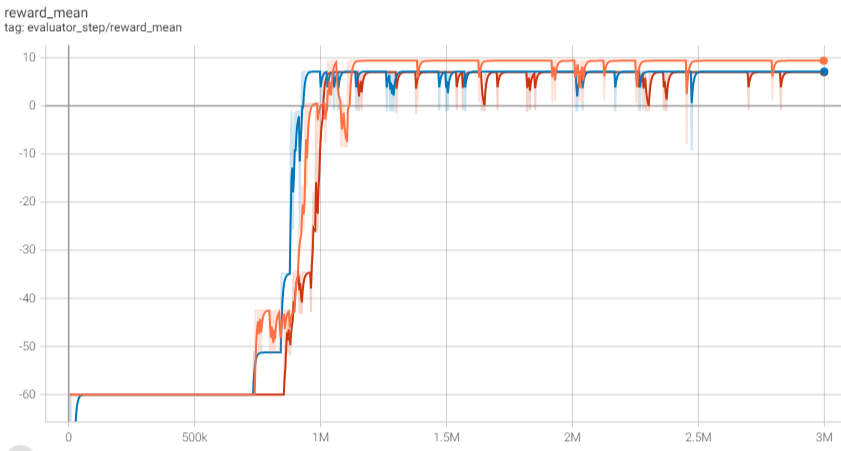
基准算法性能¶
选择总迭代步数为300000,随机选择三个不同的种子,基于DQN算法迭代结果如下图所示:可以看到大约 700k - 800k 步数后评估奖励均值开始收敛,1M 步数后评估奖励均值基本收敛到每次评估都能成功接客并送达乘客。