MBPO¶
概述¶
Model-based policy optimization (MBPO) 首次在论文 When to Trust Your Model: Model-Based Policy Optimization 中被提出。 MBPO 利用模型生成的短轨迹,并保证每一步的单调提升。 具体来说,MBPO 通过训练模型集合来拟合真实环境的 transition ,并利用它生成从真实环境状态开始的短轨迹来进行策略提升。 对于 RL 策略的选择,MBPO 使用 SAC 作为其 RL 的部分。
这个 repo awesome-model-based-RL 提供了更多 model-based rl 的论文。
核心要点¶
MBPO 是一种 基于模型(model-based)的 强化学习算法。
MBPO 用 SAC 作为 RL 策略。
MBPO 仅支持 连续动作空间 。
MBPO 使用了 model-ensemble。
关键方程或关键框图¶
预测模型(Predictive Model)¶
MBPO 利用高斯神经网络集合(ensemble of gaussian neural network),集合中的每个成员都是:
模型训练中使用的最大似然损失为:
策略优化(Policy Optimization)¶
策略评估步骤(Policy evaluation step):
策略提升步骤(Policy improvement step):
注意:这个更新要保证 \(Q^{\pi_{new}}(\boldsymbol{s}_t,\boldsymbol{a}_t) \geq Q^{\pi_{old}}(\boldsymbol{s}_t,\boldsymbol{a}_t)\), 可以查看原论文中 Appendix B.2 部分 Lemma2 的相关证明 paper。
伪代码¶

Note
MBPO 的首次实现只给出了应用于 SAC 的超参数,并不适用于 DDPG 和 TD3 。
实现¶
默认配置定义如下:
- class ding.policy.mbpolicy.mbsac.MBSACPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Model based SAC with value expansion (arXiv: 1803.00101) and value gradient (arXiv: 1510.09142) w.r.t lambda-return.
https://arxiv.org/pdf/1803.00101.pdf https://arxiv.org/pdf/1510.09142.pdf
- Config:
ID
Symbol
Type
Default Value
Description
1
learn._lambdafloat
0.8
Lambda for TD-lambda return.2
``learn.grad_clip`
float
100.0
Max norm of gradients.3
learn.sample_statebool
True
Whether to sample states ortransitions from env buffer.
Note
For other configs, please refer to ding.policy.sac.SACPolicy.
基准¶
environment |
evaluation results |
config link |
|---|---|---|
Hopper |
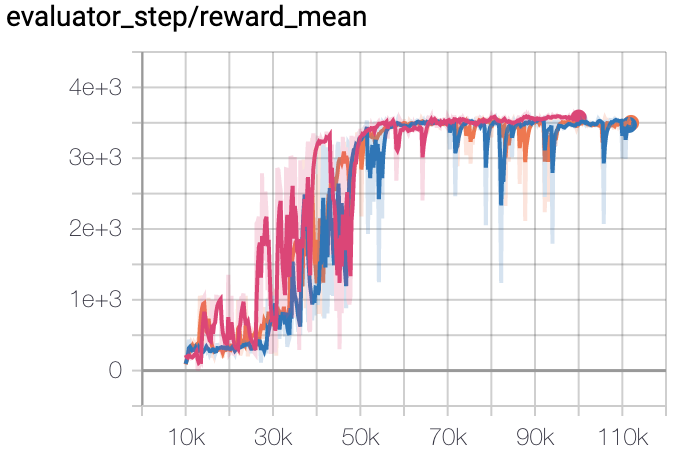
|
|
Halfcheetah |
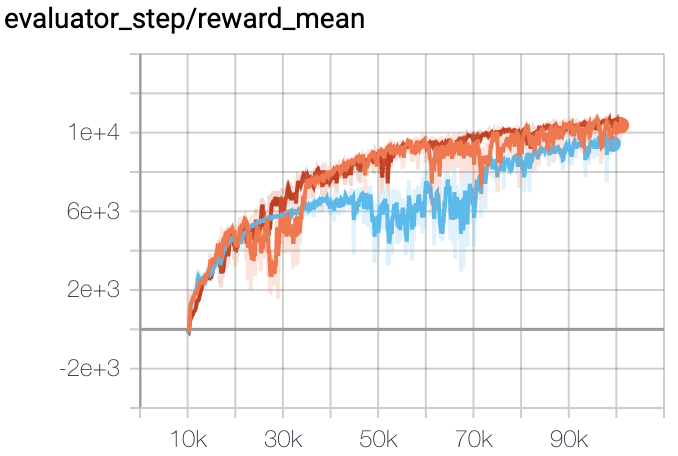
|
|
Walker2d |
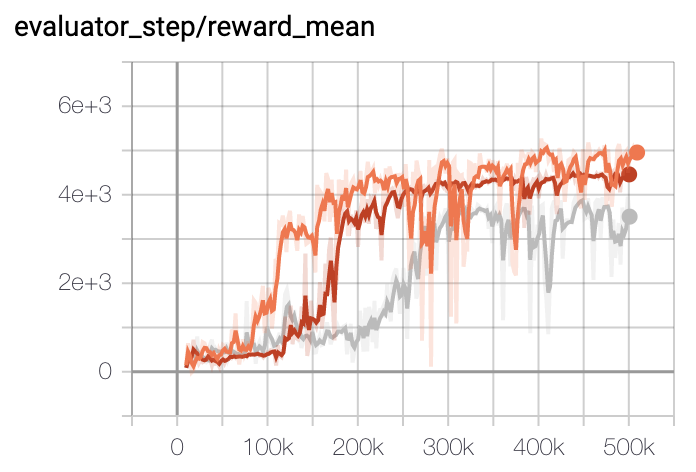
|
P.S.:
上述结果是通过在三个不同的随机种子(0,1,2)上运行相同的配置获得的。
其他公开的实现¶
参考文献¶
Michael Janner, Justin Fu, Marvin Zhang, Sergey Levine: “When to Trust Your Model: Model-Based Policy Optimization”, 2019; arXiv:1906.08253.