TD3¶
概述¶
Twin Delayed DDPG (TD3) 首次在2018年发表的论文 Addressing Function Approximation Error in Actor-Critic Methods 中被提出,它是一种考虑了策略和值更新中函数逼近误差之间相互作用的算法。 TD3 是一种基于 deep deterministic policy gradient (DDPG) 的 无模型(model-free) 算法,属于 演员—评委(actor-critic) 类算法中的一员。此算法可以解决高估偏差,时间差分方法中的误差积累以及连续动作空间中对超参数的高敏感性的问题。具体来说,TD3通过引入以下三个关键技巧来解决这些问题:
截断双 Q 学习(Clipped Double-Q Learning):在计算Bellman误差损失函数中的目标时,TD3 学习两个 Q 函数而不是一个,并使用较小的 Q 值。
延迟的策略更新(Delayed Policy Updates): TD3更新策略(和目标网络)的频率低于 Q 函数的更新频率。在本文中,作者建议在对 Q 函数更新两次后进行一次策略更新。在我们的实现中,TD3 仅在对 critic 网络更新一定次数 \(d\) 后,才对策略和目标网络进行一次更新。我们通过配置参数
learn.actor_update_freq来实现策略更新延迟。目标策略平滑(Target Policy Smoothing):通过沿动作变化平滑 Q 值,TD3 为目标动作引入噪声,使策略更加难以利用 Q 函数的预测错误。
核心要点¶
TD3 仅支持 连续动作空间 (例如: MuJoCo).
TD3 是一种 异策略(off-policy) 算法.
TD3 是一种 无模型(model-free) 和 演员—评委(actor-critic) 的强化学习算法,它会分别优化策略网络和Q网络。
关键方程或关键框图¶
TD3 提出了一个截断双 Q 学习变体(Clipped Double-Q Learning),它利用了这样一个概念,即遭受高估偏差的值估计可以用作真实值估计的近似上限。结合下式计算 \(Q_{\theta_1}\) 的 target,当 \(Q_{\theta_2} \textless Q_{\theta_1}\) 时,我们认为 \(Q_{\theta_1}\) 高估了,并将其当作真实值估计的近似上限,取较小的 \(Q_{\theta_2}\) 计算 \(y_1\) 以减少过估计。
作为原始版本双 Q 学习的一种拓展,此扩展的动机是,如果目标和当前网络过于相似,例如在actor-critic框架中使用缓慢变化的策略,原始版本的双 Q 学习有时是无效的。
TD3表明,目标网络是深度 Q 学习方法中的一种常见方法,通过减少误差积累来减少目标的方差是至关重要的。
首先,为了解决动作价值估计和策略提升的耦合问题,TD3建议延迟策略更新,直到动作价值估计值尽可能小。因此,TD3只在固定数量次数的 critic 网络更新后再更新策略和目标网络。
我们通过配置参数 learn.actor_update_freq 来实现策略更新延迟。
其次,截断双 Q 学习(Clipped Double Q-learning)算法的目标更新如下:
在实现中,我们可以通过使用单一的 actor 来优化 \(Q_{\theta_1}\) 以减少计算开销。由于 TD target 计算过程中使用了同样的策略,因此对于 \(Q_{\theta_2}\) 的优化目标, \(y_2= y_1\) 。
最后,确定性策略的一个问题是,由于以神经网络参数化的 Q 函数对 buffer 中动作的价值估计存在突然激增的尖峰(narrow peaks),这会导致策略网络过拟合到这些动作上。并且当更新 critic 网络时,使用确定性策略的学习目标极易受到函数近似误差引起的不准确性的影响,从而增加了目标的方差。 TD3 引入了一种用于深度价值学习的正则化策略,即目标策略平滑,它模仿了SARSA的学习更新。具体来说,TD3通过在目标策略中添加少量随机噪声并在多次计算以下数值后,取平均值来近似此期望:
我们通过配置 learn.noise、 learn.noise_sigma 和 learn.noise_range 来实现目标策略平滑。
伪代码¶

扩展¶
TD3 可以与以下技术相结合使用:
遵循随机策略的经验回放池初始采集
在优化模型参数前,我们需要让经验回放池存有足够数目的遵循随机策略的 transition 数据,从而确保在算法初期模型不会对经验回放池数据过拟合。 DDPG/TD3 的
random-collect-size默认设置为25000, SAC 为10000。 我们只是简单地遵循 SpinningUp 默认设置,并使用随机策略来收集初始化数据。 我们通过配置random-collect-size来控制初始经验回放池中的 transition 数目。
实现¶
默认配置定义如下:
- class ding.policy.td3.TD3Policy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
Policy class of TD3 algorithm. Since DDPG and TD3 share many common things, we can easily derive this TD3 class from DDPG class by changing
_actor_update_freq,_twin_criticand noise in model wrapper. Paper link: https://arxiv.org/pdf/1802.09477.pdf
Config:
ID
Symbol
Type
Default Value
Description
Other(Shape)
1
typestr
td3
RL policy register name, referto registryPOLICY_REGISTRYthis arg is optional,a placeholder2
cudabool
False
Whether to use cuda for network3
random_collect_sizeint
25000
Number of randomly collectedtraining samples in replaybuffer when training starts.Default to 25000 forDDPG/TD3, 10000 forsac.4
model.twin_criticbool
True
Whether to use two criticnetworks or only one.Default True for TD3,Clipped DoubleQ-learning method inTD3 paper.5
learn.learning_rate_actorfloat
1e-3
Learning rate for actornetwork(aka. policy).6
learn.learning_rate_criticfloat
1e-3
Learning rates for criticnetwork (aka. Q-network).7
learn.actor_update_freqint
2
When critic network updatesonce, how many times will actornetwork update.Default 2 for TD3, 1for DDPG. DelayedPolicy Updates methodin TD3 paper.8
learn.noisebool
True
Whether to add noise on targetnetwork’s action.Default True for TD3,False for DDPG.Target Policy Smoo-thing Regularizationin TD3 paper.9
learn.noise_rangedict
dict(min=-0.5,max=0.5,)Limit for range of targetpolicy smoothing noise,aka. noise_clip.10
learn.-ignore_donebool
False
Determine whether to ignoredone flag.Use ignore_done onlyin halfcheetah env.11
learn.-target_thetafloat
0.005
Used for soft update of thetarget network.aka. Interpolationfactor in polyak aver-aging for targetnetworks.12
collect.-noise_sigmafloat
0.1
Used for add noise during co-llection, through controllingthe sigma of distributionSample noise from dis-tribution, Ornstein-Uhlenbeck process inDDPG paper, Gaussianprocess in ours.
模型
在这里,我们提供了 ContinuousQAC 模型作为 TD3 的默认模型的示例。
- class ding.model.ContinuousQAC(obs_shape: int | SequenceType, action_shape: int | SequenceType | EasyDict, action_space: str, twin_critic: bool = False, actor_head_hidden_size: int = 64, actor_head_layer_num: int = 1, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, encoder_hidden_size_list: SequenceType | None = None, share_encoder: bool | None = False)[source]
- Overview:
The neural network and computation graph of algorithms related to Q-value Actor-Critic (QAC), such as DDPG/TD3/SAC. This model now supports continuous and hybrid action space. The ContinuousQAC is composed of four parts:
actor_encoder,critic_encoder,actor_headandcritic_head. Encoders are used to extract the feature from various observation. Heads are used to predict corresponding Q-value or action logit. In high-dimensional observation space like 2D image, we often use a shared encoder for bothactor_encoderandcritic_encoder. In low-dimensional observation space like 1D vector, we often use different encoders.- Interfaces:
__init__,forward,compute_actor,compute_critic
- compute_actor(obs: Tensor) Dict[str, Tensor | Dict[str, Tensor]][source]
- Overview:
QAC forward computation graph for actor part, input observation tensor to predict action or action logit.
- Arguments:
x (
torch.Tensor): The input observation tensor data.
- Returns:
outputs (
Dict[str, Union[torch.Tensor, Dict[str, torch.Tensor]]]): Actor output dict varying from action_space:regression,reparameterization,hybrid.
- ReturnsKeys (regression):
action (
torch.Tensor): Continuous action with same size asaction_shape, usually in DDPG/TD3.
- ReturnsKeys (reparameterization):
logit (
Dict[str, torch.Tensor]): The predictd reparameterization action logit, usually in SAC. It is a list containing two tensors:muandsigma. The former is the mean of the gaussian distribution, the latter is the standard deviation of the gaussian distribution.
- ReturnsKeys (hybrid):
logit (
torch.Tensor): The predicted discrete action type logit, it will be the same dimension asaction_type_shape, i.e., all the possible discrete action types.action_args (
torch.Tensor): Continuous action arguments with same size asaction_args_shape.
- Shapes:
obs (
torch.Tensor): \((B, N0)\), B is batch size and N0 corresponds toobs_shape.action (
torch.Tensor): \((B, N1)\), B is batch size and N1 corresponds toaction_shape.logit.mu (
torch.Tensor): \((B, N1)\), B is batch size and N1 corresponds toaction_shape.logit.sigma (
torch.Tensor): \((B, N1)\), B is batch size.logit (
torch.Tensor): \((B, N2)\), B is batch size and N2 corresponds toaction_shape.action_type_shape.action_args (
torch.Tensor): \((B, N3)\), B is batch size and N3 corresponds toaction_shape.action_args_shape.
- Examples:
>>> # Regression mode >>> model = ContinuousQAC(64, 6, 'regression') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['action'].shape == torch.Size([4, 6]) >>> # Reparameterization Mode >>> model = ContinuousQAC(64, 6, 'reparameterization') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['logit'][0].shape == torch.Size([4, 6]) # mu >>> actor_outputs['logit'][1].shape == torch.Size([4, 6]) # sigma
- compute_critic(inputs: Dict[str, Tensor]) Dict[str, Tensor][source]
- Overview:
QAC forward computation graph for critic part, input observation and action tensor to predict Q-value.
- Arguments:
inputs (
Dict[str, torch.Tensor]): The dict of input data, includingobsandactiontensor, also containslogitandaction_argstensor in hybrid action_space.
- ArgumentsKeys:
obs: (
torch.Tensor): Observation tensor data, now supports a batch of 1-dim vector data.action (
Union[torch.Tensor, Dict]): Continuous action with same size asaction_shape.logit (
torch.Tensor): Discrete action logit, only in hybrid action_space.action_args (
torch.Tensor): Continuous action arguments, only in hybrid action_space.
- Returns:
outputs (
Dict[str, torch.Tensor]): The output dict of QAC’s forward computation graph for critic, includingq_value.
- ReturnKeys:
q_value (
torch.Tensor): Q value tensor with same size as batch size.
- Shapes:
obs (
torch.Tensor): \((B, N1)\), where B is batch size and N1 isobs_shape.logit (
torch.Tensor): \((B, N2)\), B is batch size and N2 corresponds toaction_shape.action_type_shape.action_args (
torch.Tensor): \((B, N3)\), B is batch size and N3 corresponds toaction_shape.action_args_shape.action (
torch.Tensor): \((B, N4)\), where B is batch size and N4 isaction_shape.q_value (
torch.Tensor): \((B, )\), where B is batch size.
- Examples:
>>> inputs = {'obs': torch.randn(4, 8), 'action': torch.randn(4, 1)} >>> model = ContinuousQAC(obs_shape=(8, ),action_shape=1, action_space='regression') >>> assert model(inputs, mode='compute_critic')['q_value'].shape == (4, ) # q value
- forward(inputs: Tensor | Dict[str, Tensor], mode: str) Dict[str, Tensor][source]
- Overview:
QAC forward computation graph, input observation tensor to predict Q-value or action logit. Different
modewill forward with different network modules to get different outputs and save computation.- Arguments:
inputs (
Union[torch.Tensor, Dict[str, torch.Tensor]]): The input data for forward computation graph, forcompute_actor, it is the observation tensor, forcompute_critic, it is the dict data including obs and action tensor.mode (
str): The forward mode, all the modes are defined in the beginning of this class.
- Returns:
output (
Dict[str, torch.Tensor]): The output dict of QAC forward computation graph, whose key-values vary in different forward modes.
- Examples (Actor):
>>> # Regression mode >>> model = ContinuousQAC(64, 6, 'regression') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['action'].shape == torch.Size([4, 6]) >>> # Reparameterization Mode >>> model = ContinuousQAC(64, 6, 'reparameterization') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['logit'][0].shape == torch.Size([4, 6]) # mu >>> actor_outputs['logit'][1].shape == torch.Size([4, 6]) # sigma
- Examples (Critic):
>>> inputs = {'obs': torch.randn(4, 8), 'action': torch.randn(4, 1)} >>> model = ContinuousQAC(obs_shape=(8, ),action_shape=1, action_space='regression') >>> assert model(inputs, mode='compute_critic')['q_value'].shape == (4, ) # q value
训练 actor-critic 模型
首先,我们在
_init_learn中分别初始化 actor 和 critic 优化器。 设置两个独立的优化器可以保证我们在计算 actor 损失时只更新 actor 网络参数而不更新 critic 网络,反之亦然。# actor and critic optimizer self._optimizer_actor = Adam( self._model.actor.parameters(), lr=self._cfg.learn.learning_rate_actor, weight_decay=self._cfg.learn.weight_decay ) self._optimizer_critic = Adam( self._model.critic.parameters(), lr=self._cfg.learn.learning_rate_critic, weight_decay=self._cfg.learn.weight_decay )
- 在
_forward_learn中,我们通过计算 critic 损失、更新 critic 网络、计算 actor 损失和更新 actor 网络来更新 actor-critic 策略。 critic loss computation计算当前值和目标值
# current q value q_value = self._learn_model.forward(data, mode='compute_critic')['q_value'] q_value_dict = {} if self._twin_critic: q_value_dict['q_value'] = q_value[0].mean() q_value_dict['q_value_twin'] = q_value[1].mean() else: q_value_dict['q_value'] = q_value.mean() # target q value. SARSA: first predict next action, then calculate next q value with torch.no_grad(): next_action = self._target_model.forward(next_obs, mode='compute_actor')['action'] next_data = {'obs': next_obs, 'action': next_action} target_q_value = self._target_model.forward(next_data, mode='compute_critic')['q_value']
Q 网络目标(Clipped Double-Q Learning)和损失计算
if self._twin_critic: # TD3: two critic networks target_q_value = torch.min(target_q_value[0], target_q_value[1]) # find min one as target q value # network1 td_data = v_1step_td_data(q_value[0], target_q_value, reward, data['done'], data['weight']) critic_loss, td_error_per_sample1 = v_1step_td_error(td_data, self._gamma) loss_dict['critic_loss'] = critic_loss # network2(twin network) td_data_twin = v_1step_td_data(q_value[1], target_q_value, reward, data['done'], data['weight']) critic_twin_loss, td_error_per_sample2 = v_1step_td_error(td_data_twin, self._gamma) loss_dict['critic_twin_loss'] = critic_twin_loss td_error_per_sample = (td_error_per_sample1 + td_error_per_sample2) / 2 else: # DDPG: single critic network td_data = v_1step_td_data(q_value, target_q_value, reward, data['done'], data['weight']) critic_loss, td_error_per_sample = v_1step_td_error(td_data, self._gamma) loss_dict['critic_loss'] = critic_loss
critic network updateself._optimizer_critic.zero_grad() for k in loss_dict: if 'critic' in k: loss_dict[k].backward() self._optimizer_critic.step()
actor loss computation和actor network update取决于策略更新延迟(delaying the policy updates)的程度。if (self._forward_learn_cnt + 1) % self._actor_update_freq == 0: actor_data = self._learn_model.forward(data['obs'], mode='compute_actor') actor_data['obs'] = data['obs'] if self._twin_critic: actor_loss = -self._learn_model.forward(actor_data, mode='compute_critic')['q_value'][0].mean() else: actor_loss = -self._learn_model.forward(actor_data, mode='compute_critic')['q_value'].mean() loss_dict['actor_loss'] = actor_loss # actor update self._optimizer_actor.zero_grad() actor_loss.backward() self._optimizer_actor.step()
- 在
目标网络(Target Network)
我们通过
_init_learn中的self._target_model初始化来实现目标网络。 我们配置learn.target_theta来控制平均中的插值因子。# main and target models self._target_model = copy.deepcopy(self._model) self._target_model = model_wrap( self._target_model, wrapper_name='target', update_type='momentum', update_kwargs={'theta': self._cfg.learn.target_theta} )
目标策略平滑正则(Target Policy Smoothing Regularization)
我们通过
_init_learn中的目标模型初始化来实现目标策略平滑正则。 我们通过配置learn.noise、learn.noise_sigma和learn.noise_range来控制引入的噪声,通过对噪声进行截断使所选动作不会太过偏离原始动作。if self._cfg.learn.noise: self._target_model = model_wrap( self._target_model, wrapper_name='action_noise', noise_type='gauss', noise_kwargs={ 'mu': 0.0, 'sigma': self._cfg.learn.noise_sigma }, noise_range=self._cfg.learn.noise_range )
基准¶
environment |
best mean reward |
evaluation results |
config link |
comparison |
|---|---|---|---|---|
HalfCheetah (HalfCheetah-v3) |
11148 |
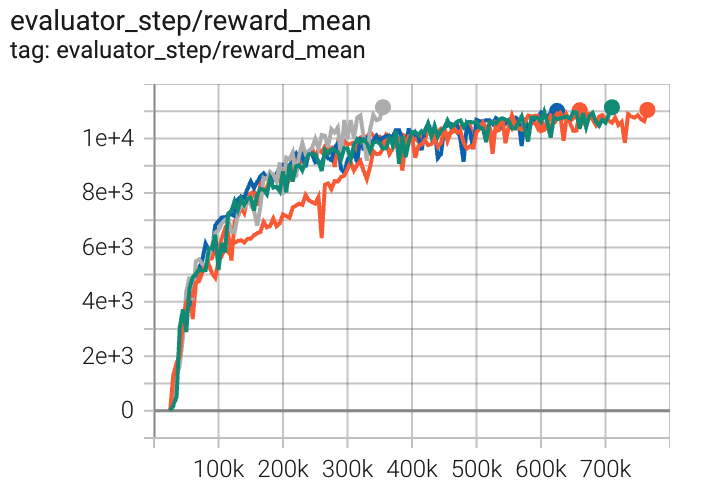
|
Tianshou(10201) Spinning-up(9750) Sb3(9656) |
|
Hopper (Hopper-v2) |
3720 |
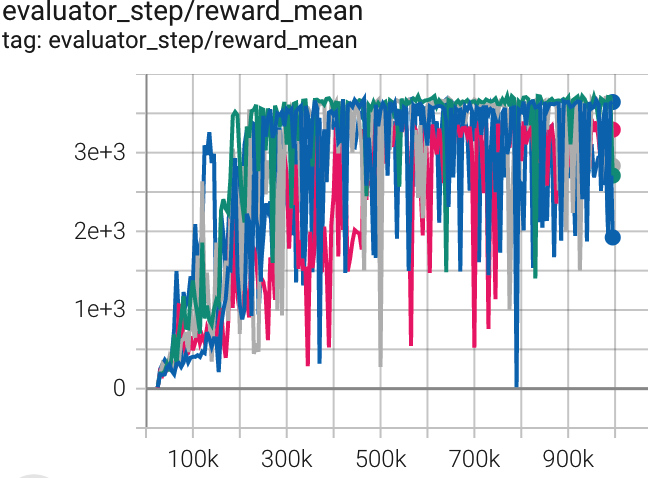
|
Tianshou(3472) Spinning-up(3982) sb3(3606 for Hopper-v3) |
|
Walker2d (Walker2d-v2) |
4386 |
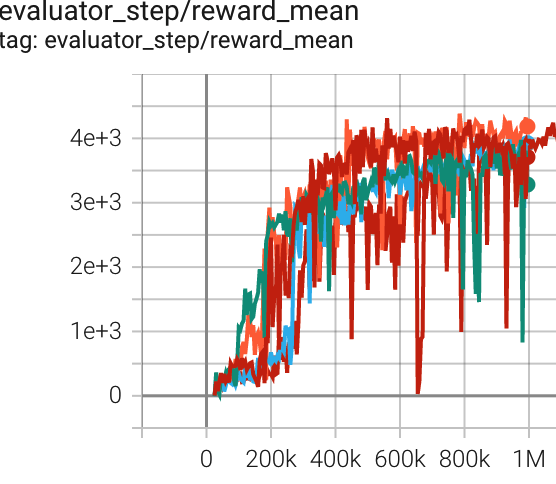
|
Tianshou(3982) Spinning-up(3472) sb3(4718 for Walker2d-v2) |
P.S.:
上述结果是通过在五个不同的随机种子(0,1,2,3,4)上运行相同的配置获得的。
参考文献¶
Scott Fujimoto, Herke van Hoof, David Meger: “Addressing Function Approximation Error in Actor-Critic Methods”, 2018; [http://arxiv.org/abs/1802.09477 arXiv:1802.09477].