Policy Features¶
Policy is defined as an instance to run forward with observation as input and action as output. Basically it should
have these interfaces: init, reset and forward.
DI-drive defines policy in a more complex but powerful way. One policy can have different running modes,
in order to be suitable for various kinds of training and test procedures, i.e. a Reinforcement Learning policy
may act differently when sampling data and evaluating, a Supervised Learning policy may have different outputs
when labels are not equal to control signal.
As a result of this, DI-drive follows the policy definition of
DI-engine which defines
three modes: collect, eval and learn. Different modes of policy may have different
behavior but share some core modules such as a Neural Network computation graph, and can be
called with the same interfaces.
DI-drive makes this work by defining policy’s property of each mode, in which it maps a set of functions in
policy with interfaces that can be directly called by the user. For example, calling forward method of a
policy.collect_mode is the same as calling policy._forward_collect method. Same as init, reset,
state_dict and load_state_dict. This makes the policy polymorphic under the same core computing logic.
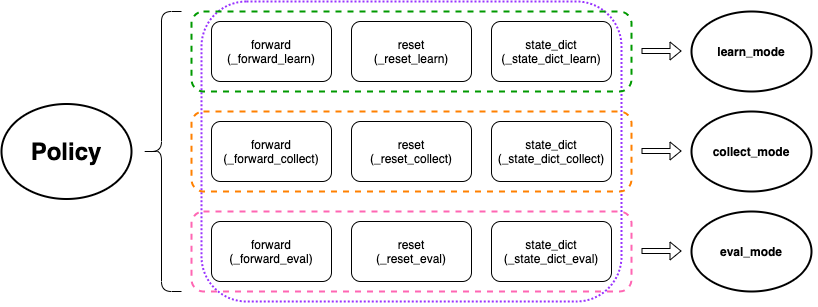
After that, it is natural to use the same policy with different modes in some worker instances to realize various
functions during training, collecting and evaluating etc. What is more, users are allowed to design their own
policy mode in this way. Just keep the external interface init, reset and forward (state_dict as
optional) able to be called as usual.
my_policy = MyPolicy(...)
# collection data
collector.policy = my_policy.collect_mode
data = collector.collect(n_sample=...)
# evaluation
evaluator.policy = my_policy.eval_mode
results = evaluator.eval(suite=...)
# training
learner.policy = my_policy.learn_mode
loss = learner.train(train_data=...)
DI-drive uses DI-engine’s EnvManager to sample data in parallel. One policy should be able to handle data
from several environments when computing forward. For NN model, this is done by put all data together as a
batch and run forward for one time. For the other model like PID controller, the policy should store internal
information for each environment to run correctly.
env_manager = BaseEnvManager(...)
my_policy = MyPolicy(...).xxx_mode
obs = env_manager.ready_obs
# obs is a dict contains observation in several environments like {env_id: obs, ...}
actions = my_policy.forward(obs)
# policy should return a dict with all actions of environments in the passed obs dict, like {env_id: action, ...}