DREX in MetaDrive¶
DREX is an preference based Inverse Reinforcement Learning(IRL) method by generating rankings automatically through injecting different level noise.
We implement DREX in Metadrive.
DREX model takes Top-Down Semantic Maps and Vehicle’s states(including steer and speed) as input to learn the reward model from given demonstrations ranked by their noise level.
Training DREX reward model¶
train_drex_model.py are used for training the reward model.
You may need to change the dataset path.
The Default setting for DREX is setting noise level from 0 to 1, the interval is 0.1, total 11 levels. 20 full trajectorys in every level, 19 for training and 1 leave for validation.
Then create 6000 random pratial trajcectorys for training set, and 300 for validation set.
Default Configuration of training reward model:
config = dict(
dataset_path = '/test_drex',
noise_level = ['1.0','0.9','0.8','0.7','0.6','0.5','0.4','0.3','0.2','0.1','0.0'],
drex_path = '/test_drex',
reward_model_name = 'drex_reward_model',
)
Training the reward model:
python train_drex_model.py
Training PPO with DREX¶
Default Configuration of training PPO with DREX:
metadrive_basic_config = dict(
exp_name='drex_ppo_train',
reward_model_path = '/reward_model/drex_reward_model',
env=dict(
metadrive=dict(
traj_control_mode = 'jerk',
use_render=False,
seq_traj_len = 1,
use_lateral_penalty = False,
traffic_density = 0.2,
use_lateral = True,
use_speed_reward = True,
use_jerk_reward = False,#
avg_speed = 6.5,
driving_reward = 0.2,
speed_reward = 0.1,
),
manager=dict(
shared_memory=False,
max_retry=5,
context='spawn',
),
n_evaluator_episode=10,
stop_value=99999,
collector_env_num=8,
evaluator_env_num=2,
),
policy=dict(
cuda=True,
action_space='continuous',
model=dict(
obs_shape=[5, 200, 200],
action_shape=2,
action_space='continuous',
encoder_hidden_size_list=[128, 128, 64],
),
learn=dict(
epoch_per_collect=2,
batch_size=64,
learning_rate=3e-4,
learner=dict(
hook=dict(
save_ckpt_after_iter=5000,
)
)
),
collect=dict(
n_sample=300,
),
eval=dict(
evaluator=dict(
eval_freq=1000,
),
),
)
)
Training PPO with DREX reward model:
python train_ppo_drex.py
Results¶
compare DREX result with PPO training with expert-defined reward. The blue curve is PPO with DREX reward model. The red curve is PPO with expert-defined reward.
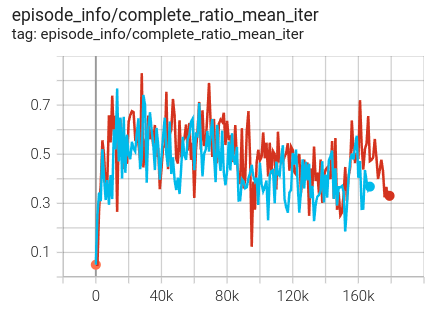
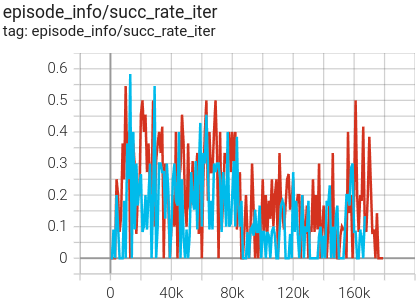
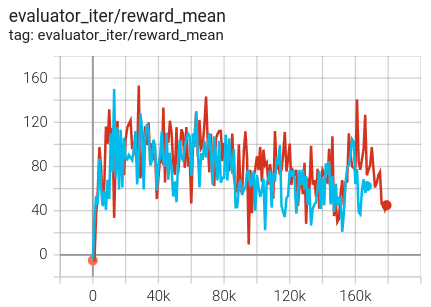
Testing with visualization:
If you want to visualization the driving process, you should change the render setting in
train_ppo_drex.py : use_render = True
@inproceedings{brown2020better,
title={Better-than-demonstrator imitation learning via automatically-ranked demonstrations},
author={Brown, Daniel S and Goo, Wonjoon and Niekum, Scott},
booktitle={Conference on robot learning},
pages={330--359},
year={2020},
organization={PMLR}
}