Simple Reinforcement Learning¶
DI-drive + DI-engine make RL for Autonomous Driving very easy. Here we show how to use DI-drive to run a simple Reinforcement Learning driving policy with Carla and MetaDrive separately.
Prerequisites¶
Ubuntu 16.04 system + Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz + 32G memory + GPU1060
Carla RL Tutorial¶
DI-drive support several RL policies and provide a simple RL env running with Carla server. The policy takes a small Bird-eye View image together with current speed as input, and directly outputs control signals.
RL training using DI-engine¶
We build simple RL demos that can run varies RL algorithm with the aforementioned simple environment setting.
All the code can be found in demo/simple_rl, including training, evaluating and testing.
Here we show how to run the DQN demo. It follows the standard deployment of a DI-engine RL entry. Other RL policies run in same way.
cd demo/simple_rl
python simple_rl_train.py -p dqn
The config part defines the env and policy settings. Notes that you need to change the Carla server host and port, and modify the environment nums according to yours. By default it uses 8 Carla servers on localhost with port from 9000 to 9016.
train_config = dict(
exp_name=...,
env=dict(
...
),
server=[
dict(carla_host='localhost', carla_ports=[9000, 9016, 2]),
],
policy=dict(
...
),
)
For more details about how to tune parameters in DQN, you can see DI-engine’s doc. Usually you may concern about the replay buffer size and sample num per collection.
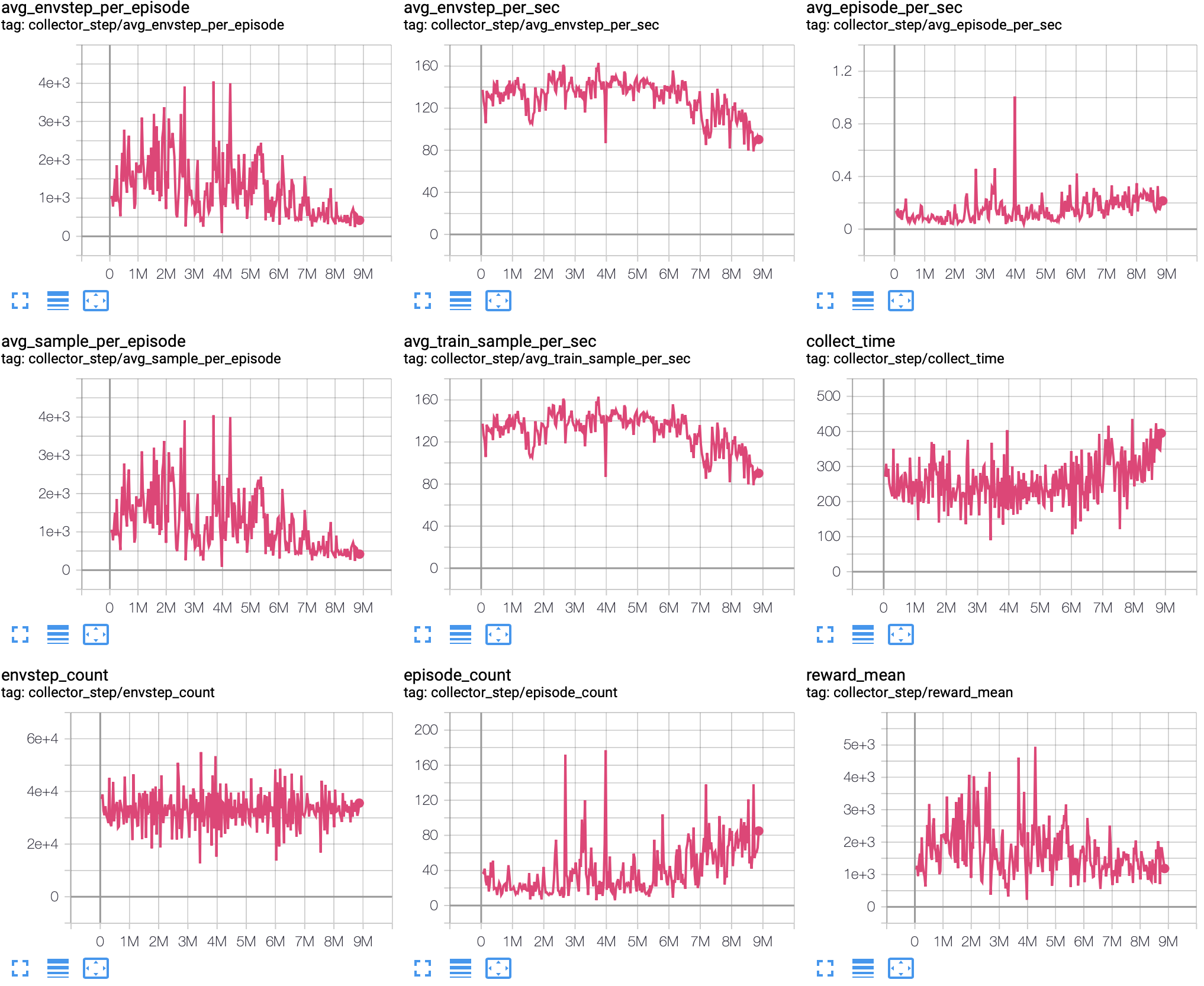
When you see the information in terminal that contains the content in the following picture, it means that you are beginning to train the model.

In the process of training, you can use the tensorboard as a monitor, the default log path is in your working directory.
tensorboard --logdir='./log'
After running for about 24 hours, you will get:
Evaluate and test the trained model¶
After training, you can evaluate the trained model on a benchmark suite. Simply run the following code.
python simple_rl_eval.py -p dqn -c PATH_TO_YOUR_CKPT
You may need to change Carla server numbers and settints, change the suite you want to evaluate, and add your pre-trained weights in policy’s config.
eval_config = dict(
env=dict(
env_num=5,
...
),
server=[dict(
carla_host='localhost',
carla_ports=[9000, 9010, 2]
)],
policy=dict(
cuda=True,
ckpt_path='path/to/your/model',
eval=dict(
evaluator=dict(
suite='FullTown02-v1',
...
),
),
...
),
...
)
The default DQN policy can have nice probability to complete navigation in FullTown02-v2, with traffic lights ignored.
Also, you can test the policy in a town route with a visualized screen. Simply run the following code.
python simple_rl_test.py -p dqn -c PATH_TO_YOUR_CKPT
You may need to change Carla server settints, switch on/off visualization or save a replay gif/video and add your pre-trained weights in policy’s config.
test_config = dict(
env=dict(
...
visualize=dict(
type='birdview',
outputs=['show'], # or 'gif', 'video'
save_dir='',
frame_skip=3, # avoid to be too large
),
),
server=[dict(
carla_host='localhost',
carla_ports=[9000, 9002, 2]
)],
policy=dict(
cuda=True,
ckpt_path='path/to/your/model',
eval=dict(
evaluator=dict(
render=True,
...
),
),
...
),
)
MetaDrive RL Tutorial¶
DI-drive provide a simple entry that can run MetaDrive default environments with DI-engine policies. The training entry can be found in demo/metadrive
cd demo/metadrive
python basic_env_train.py
MetaDrive has standard gym environments. Adding an EnvWrapper together with
other components and pipeline in DI-engine, RL experiments is able to run.
Here, we use “MetaDrive-1000envs-v0” to train and “MetaDrive-validation-v0” to evaluate an on-policy PPO policy. You can modify the env num in config to suit your device.
metadrive_basic_config = dict(
env=dict(
...
collector_env_num=4,
evaluator_env_num=1,
),
...
)